前言
什么是爬虫
网络爬虫(Web Spider)又叫网络蜘蛛,或者网络机器人(在FOAF社区中间,更经常的称为网页追逐者),正如他的英文名一样,很形象的一个名字。把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。它是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。其中的工作原理就是通过编程让程序自动化,模拟人的操作,模仿人给服务器发送请求,从返回的信息中抓取需要的数据.爬虫还有另外一些不常使用的名字还有蚂蚁,自动索引,模拟程序或者蠕虫等等.爬虫应用很广泛,比如我们常用的百度,谷歌等等搜索引擎,我们搜出来的信息都是爬虫抓取并存储到数据库中的数据,例如:百度的快照,明明页面没有了,但是快照还能看到,因为页面的数据已经被搜索引擎中网络爬虫爬下来存储到数据库中
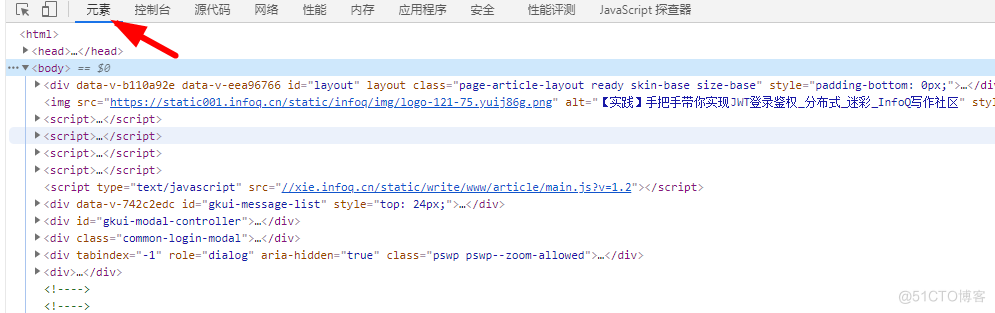
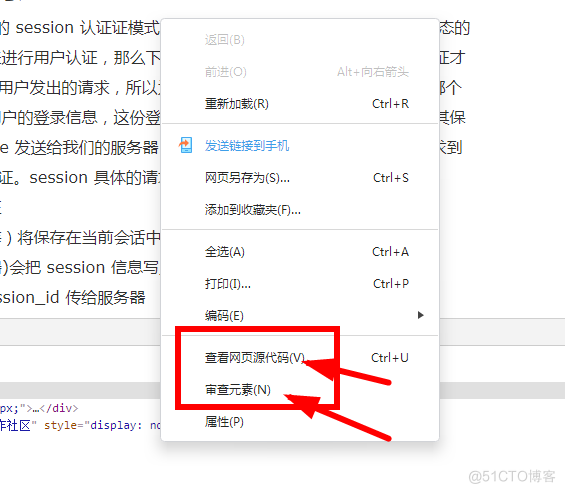
除了搜索引擎,还有很多爬虫工具和软件:比如在仿站盛行的时代,出现很多类似的网页抓取软件,比如网页小偷(这名字看着就很刑啊~哈哈哈),仿站小工具,还有大家耳熟能详的火车头采集器,这些软件能把别人的网站信息或者数据下载到本地电脑,把收集的数据经过清洗整理,然后可以进行一些相关的数据分析.但是必须明确的是,爬取数据只是取数阶段,跟实际的数据分析还差很长的距离.其实网络爬虫爬取网页爬取到的是网页的html内容,比如我们操在浏览器审查源码或查看源码(按F12或者鼠标右键都可调出相关面板)所看到的内容,如下图:
一般网页的html代码格式如下:
<html> <head> <title>测试</title> <style> body { margin: 0; } canvas { width: 100%; height: 100% } </style> </head> <body> <script> //js脚本...</script> </body></html>网页信息大致可分为两个部分:
头部<head>身体<body>我们在浏览器看到的内容都写在<body></body>这对标签里面
爬虫的作用
网络爬虫是通过网页的链接地址来寻找网页。通常从网站某一个特定的页面开始读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网络爬虫就可以用这个原理把互联网上所有的网页都抓取下来,这样你就可以尽可能多地从互联网获取到更多有用的数据,通过对这些数据的整理和分析,得出相关结论,做出正确的决策,所以爬虫对于数据分析来说是很重要的取数环节.不过需要提醒的是并不是网络上任何信息都可随你任意爬取,一定要在法律允许的范围内爬取公开的数据,而且爬取到的数据不可以用于非法操作,最重要的是不要由于自己的爬虫造成别人损失,比如系统崩溃,服务器宕机...总的来说就是合法适当.
如何实现爬虫
废话不多说,直接上代码.今天就使用Python的Requests库实现网页信息的获取,在信息大爆炸的今天,新闻报道的成本越来越底,在自媒体的时代,人人都是自己的代言人,都是一个行走的流量品牌,新闻的数量越来越多,新闻信息里面的包含了许多话题,简直目不暇接,因此新闻的获取对于舆情工作者来说十分重要,所以本文以爬取新浪新闻为例展开
Requests的安装
如果你安装了Anaconda,requests就已经可用了,若没有安装,可通过下面的命令进行安装:
pip install requests本文还用到BeautifulSoup库来解析网页信息,BeautifulSoup是一个从文件中提取数据的Python库,广泛应用爬虫之中,其中最常用的搜索方法是find_all()比如:
soup.find_all("a")#还可以简写soup("a")#两句代码是等价的 a是html中的a标签BeautifulSoup库的安装命令如下:
pip install beautifulsoup4具体的使用我们到实例中去感受
实现爬取流程

代码实现
导入所需模块
import requestsfrom bs4 import BeautifulSoupimport timefrom random import randomimport pandas as pd使用requests获取网页信息,并获取每个分页地址
页面地址:http://travel.sina.cn/itinerary/
接口地址:http://travel.sina.cn/interface/2018_feed.d.json?target=3&page=xx
def get_news_urls(page_url): """获取每个分页的所有新闻的url,并返回""" _urls = [] headers = { # 浏览器请求头 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36' } res = requests.get(page_url, headers=headers) if res.status_code != 200: # 验证是否爬取成功,成功状态码为200 print('url acquisition failed! : ' + page_url) return None res_content = res.json().get('cards') if res_content: # 返回数据是否有数据 for item in res_content: _urls.append('http:' + item['scheme']) return _urls else: print('url parse failed! : ' + page_url) return None获取每个新闻的详情
def get_one_news(news_url): #取得一个新闻页面新闻的详细信息 headers = { # 浏览器请求头 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36' } res = requests.get(news_url, headers=headers) if res.status_code != 200: print('url acquisition failed! : ' + news_url) return None res.encoding = 'utf-8' # 解析爬取的网页数据 soup = BeautifulSoup(res.text, 'lxml') title = soup.find(attrs={'class': 'page-header'}).h1.string content = ''.join( [''.join(list(i.strings)) for i in soup.find(attrs={'id': 'artibody'}).find_all(attrs={'align': 'justify'})]) ctime = list(soup.find(attrs={'class': 'time-source'}).strings)[0].strip() source = list(soup.find(attrs={'class': 'time-source'}).strings)[1].strip() return {'title': title, 'content': content, 'ctime': ctime, 'source': source}保存信息到excel
def save_to_csv(all_data): pd.DataFrame(all_data).to_csv('news.csv', encoding='utf-8', index=False) print('文件保存完毕!请查看当前目录')验证执行各个函数,实现数据爬取和内容保存
if __name__ == '__main__': page_num = 5 # 爬取的页数,每页10条新闻 base_url = 'http://travel.sina.cn/interface/2018_feed.d.json?target=3&page={}' all_news_urls = [] all_data = [] # 循环每一页,获取所有新闻的url for i in range(1, page_num + 1): print('========开始爬取第{}页========='.format(i)) page_url = base_url.format(i) news_urls = get_news_urls(page_url) if news_urls: for news_url in news_urls: # 循环所有新闻的url,获取新闻的 print(news_url) data = get_one_news(news_url) if data: all_data.append(data) print('总共获得新闻', len(all_data), '条!') save_to_csv(all_data) # 保存到本地文件执行结果如下:

csv文件截图

实现爬虫的注意事项
最后再托付一句:一定要在法律允许的范围内爬取公开的数据,不可以非法爬取他人网站信息,而且爬取到的数据不可以用于非法操作