基于struts+hibernate的采购管理系统的
分析与实现
摘 要
当今社会己进入信息社会时代,信息己经受到社会的广泛关注,被看作社会和科学技术发展的三大支柱(材料、能源、信息)之一。信息是管理的基础,是进行决策的基本依据。在一个组织里,信息己作为人力、物力、财力之外的第四种能源,占有重要的地位。然而,信息是一种非物质的,有别于基本资源的新形式的资源。信息也是管理的对象,必须进行管理和控制。随着信息技术的发展及ERP系统的日益普及,计算机在管理中的作用越来越不容忽视。企业之间通过网络进行交易的趋势越来越明显。在这种环境中,采购作为生产经营的一个重要环节应加强管理,充分利用外部环境条件,逐步实现物资采购的信息化管理。
物资采购管理系统是针对内部而设计的,应用于的局域网,这样可以使得内部管理更有效的联系起来。企业采购管理系统是将IT技术用于企业采购信息的管理, 它能够收集与存储企业采购的档案信息,提供更新与检索企业采购信息档案的接口;提高工作效率。
系统采用Java为编程语言。论文主要介绍了本课题的开发背景,所要完成的功能和开发的过程。重点的说明了系统设计的重点、设计思想、难点技术和解决方案。
关键词:企业采购;管理;系统;开发;JAVA
Research of Procurement Management Based on Struts and Hibernate
Abstract
Today's society has entered the era of information society, information has been widespread concern in society, as the three pillars of the social and scientific and technological development (materials, energy, information) one. Information management, decision-making basis for an organization, the information has the energy of the fourth addition to the human, material and financial resources to occupy an important position. However, information is a non-material resources of the new form is different from the basic resources. Information is also managed objects, management and control. With the development of the information technology and the prevalence of the ERP system, it is hardly to ignore the play of the computer in enterprise management. It is more apparent that many commercial actions among many enterprises are taking place in the network. Under the circumstances, purchasing management, which is an important link of enterprise operation, must be strengthened firstly. Then, purchasing management will be put into execution with the good condition, which the outer circumstances provide.
Aiming at the management in enterprise, the system, which will be put into execution with LAN, will make the management in enterprise better. Inventory management system is IT technology for the management of inventory information, it can collect the files and store the inventory information, provide updates and retrieve inventory information file interface; improve work efficiency.
The system uses Java as programming language. The paper introduces the development background of the subject, to complete the development and function of the process. Focus on the focus of system design, design ideas, difficult technology and solutions.
Key words: procurement; management; system; development ; JAVA
目录
摘 要ii
Abstractii
第一章 引言11
1.1研究现状11
1.2主要研究的目的及内容11
1.3研究方法及设计思路22
1.3.1 研究方法22
1.3.2 设计思路22
1.4.相关技术简介33
1.4.1 JSP技术简介33
1.4.2 Struts 框架33
1.4.3 Hibernate数据访问框架44
1.4.4 B/S模式分析44
1.5 系统开发步骤55
第二章 需求分析及可行性分析66
2.1需求分析66
2.1.2运行需求分析66
2.1.3其他需求分析66
2.2 可行性分析66
2.2.1经济可行性66
2.2.2技术可行性77
2.2.3 运行可行性77
2.2.4时间可行性77
2.2.5 法律可行性77
第三章 系统分析与设计88
3.1系统实现目标88
3.2 系统设计88
3.2.1系统设计88
3.3数据库设计99
3.3.1数据库概述99
3.3.2数据库实现99
3.4系统体系结构1010
3.5系统流程图1111
3.6系统用例图1414
第四章 系统实现1616
4.1.系统实现1616
4.1.1 登录模块1616
4.1.2系统主界面2020
4.1.3用户操作2121
4.1.4供应商管理2323
4.1.5材料信息管理2626
4.1.6订单信息管理2828
4.1.7信息查询3535
第五章 系统测试3939
5.1系统调试3939
5.1.1 程序调试3939
5.2 程序测试3939
5.2.1 测试的重要性及目的3939
5.2.2 测试的步骤4040
5.2.3 测试的主要内容4040
结束语4343
参考文献4444
致 谢4545
外文原文4646
中文翻译5454
第一章 引言
1.1研究现状
随着信息技术的发展及ERP系统的日益普及,计算机在管理中的作用越来越不容忽视。在这种环境中,采购作为生产经营的一个重要环节应加强管理,充分利用外部环境条件,逐步实现企业采购的信息化管理。企业采购管理系统是针对内部而设计的,应用于的局域网,这样可以使得内部管理更有效的联系起来。本课题就是针对企业采购管理,开发一个基于JAVA设计语言的管理系统,本系统采用了目前流行Eclipse JAVA EE开发工具,后台采用SQL Server 2008数据库。其中系统涉及用户登录模块、订单管理模块、基本信息管理模块、采购查询模块四大模块。本课题研究的重点是中小型企业采购管理问题。实现业务流程控制,生成采购计划,直至生成采购执行单,提高采购业务效率,为企业决策者快速决策提供实时的关键数据支持。
近年来我国信息事业发展迅速,手工管理方式在企业采购信息管理等需要大量事务处理的应用中已显得不相适应,采用IT技术提高服务质量和管理水平势在必行。目前,对外开放必然趋势使信息行业直面外国同行单位的直接挑战,因此,信息行业必须提高其工作效率,改善其工作环境。这样,企业采购信息管理的信息化势在必行。
在传统的企业采购信息管理中,其过程往往是很复杂的,繁琐的,企业采购信息管理以企业采购信息管理为核心,在此过程中又需要经过若干道手续,因为整个过程都需要手工操作,效率十分低下,且由于他们之间关联复杂,统计和查询的方式各不相同;且会出现信息的重复传递问题,因此该过程必须实现信息化。
随着计算机技术和网络技术的飞速发展,各企业都相继采用信息技术对企业采购有关信息进行管理。然而,也注意到许多单位,并没有很好地运用现代信息技术对企业采购等信息进行管理,很多企业采购管理系统将所有的管理事务全都交给管理员来完成,如果信息有任何的增删改查,都需要通过管理员来完成,非常麻烦。如何开发一个实用的企业采购管理系统,是摆在设计者面前的一大难题。 通过对企业采购管理系统进行深入分析和研究,本文从功能模块、数据格式、通用性三个方面进行细化,提出企业采购管理系统设计的理论依据和实现的方法。设计系统的数据层、逻辑层、界面层,重点体现数据格式的规范,也为通用性的实施提供保障。最后在系统开发环节,从技术层面实现代码的可重用性及系统的通用性,从而使系统的设计更具实用性和通用性。总之我觉得现在逐渐发展起来的信息系统可以让企业采购管理变得非常灵活,每一种角色都有自己的权限,保证了信息的安全性以及操作简易性。因此,基于MVC 的企业采购管理系统将会是以后的趋势。所以我通过开发完成一个小型企业采购管理系统,以便能更好的衔接。
1.2主要研究的目的及内容
国内企业在激烈的环境生存与发展,需要发挥采购的积极作用,在进行详细分析与研究的基础上,明确企业的不足并迅速加以弥补,采购管理目标是以最小的成本取得最大的效益。
采购管理就是以合适的时间、地点、质量和数量在企业外部获取产品,采购管理的目的是保证企业的商品供应,以使生产顺利进行,并提升企业的竞争力。
国外,大卫.琼斯在其著作《采购原理与管理》一书中说,采购的角色发生了变化,采购不再被认为是例行公事的或行政性的订购活动,即采购不再仅仅是订购或购买,而是具有战略作用的,关乎从原材料到使用和弃置整个过程的物料流动。
供应链管理现在已经被大型组织看作是降低成本和增加价值的一个领域。组织从供应链中削减成本的能力会受到采购活动发展阶段的影响。如果采购职能得到了适当的发展,采购可以在供应链管理领域进行运作性的,战术的和战略的改进。如果某些组织的采购部门能够以积极主动的战略方式提高供应链的效率和有效性,那么其他组织也可以,然而,降低购置成本、战略外包、电子商务,所有这些都要靠采购活动发展到适当水平。事务性的、被动的采购活动是无法对这些理念真正做出贡献的,而得到良好发展的战略性的采购活动则能够做到。具体细化到设计上,主要体现在以下几个方面:
1.数据库的建立与维护:系统中需要长期保存的信息应持久化到数据库,方便读取、更新、修改。如何设计数据库及其各类表是我们首先应解决的关键问题。
2.简易实用的采购管理:通过简单实用的各种采购管理功能,能够有效地提高采购效率,使企业快速决定其他决策目标。
3.实现信息共享:使企业采购人员和其他部门所有成员及时准确的了解供应商信息、采购计划、采购执行单的各流程的状态等等。
4.数据库的安全性管理:SQL Server2008访问控制,数据库权限管理,数据库角色管理等。
本课题的目的是使企业采购信息管理清晰化,透明化,便于操作,易于管理。通过功能模块的优化组合实现不同的管理细节,使管理过程实现最大程度的自动化与信息化,并能自动对人工操作环节进行复查,使企业采购管理系统出错率降至最低。在传统的企业采购信息管理中,各种管理工作往往是很复杂烦琐的。企业采购信息管理的特点是信息处理量比较大,所管理的种类比较繁多,而且由于消费、缴费等单据发生量特别大,关联信息多,查询和统计的方式不尽相同。在管理过程中经常会出现信息的重复传递,因此企业采购信息管理必须实现计算机化处理。我们系统开发的总体任务是实现企业采购信息管理的系统化、规范化、自动化、信息化与智能化,从而达到提高企业采购信息管理效率的目的。
1.3研究方法及设计思路
1.3.1 研究方法
企业采购信息管理是信息行业业务流程过程中十分重要且必备的环节之一,在信息行业业务流程当中起着承上启下的作用,其重要性不言而喻。但是,目前许多信息行业在具体的业务流程处理过程中仍然使用手工操作的方式来实施,不仅费时、费力,效率低下,而且无法达到理想的效果。针对上述问题,采用软件工程的开发原理,依据软件流程过程规范,按照需求分析、概要设计、详细设计、程序编码、测试、软件应用、软件维护等过程开发了一个企业采购管理系统。采用JSP作为开发技术,结合SQL Server2008数据库,数据库设计遵循3范式,解决了企业采购管理系统中存在的数据安全性、数据一致性以及系统运行速度等问题。
1.3.2 设计思路
(1)系统应符合企业采购信息管理的规定,满足信息行业相关人员日常使用的需要,并达到操作过程中的直观,方便,实用,安全等要求;
(2)系统采用模块化程序设计方法,既便于系统功能的各种组合和修改,又便于未参与开发的技术维护人员补充,维护;
(3)系统应具备数据库维护功能,及时根据用户需求进行数据的添加、删除、修改、备份等操作;
(4)尽量采用现有软件环境及先进的管理系统开发方案,从而达到充分利用现有资源,提高系统开发水平和应用效果的目的。
1.4.相关技术简介
1.4.1 JSP技术简介
JSP(JavaServer Pages)是由Sun Microsystems公司倡导、许多公司参与一起建立的一种动态网页技术标准。它是在传统的网页HTML文件(*.htm,*.html)中插入Java程序段(Scriptlet)和JSP标记(tag),从而形成JSP文件(*.jsp)。 用JSP开发的Web应用是跨平台的,即能在Linux下运行,也能在其他操作系统上运行。JSP技术使用Java编程语言编写类XML的tags和scriptlets,来封装产生动态网页的处理逻辑。网页还能通过tags和scriptlets访问存在于服务端的资源的应用逻辑。JSP将网页逻辑与网页设计和显示分离,支持可重用的基于组件的设计,使基于Web的应用程序的开发变得迅速和容易。 Web服务器在遇到访问JSP网页的请求时,首先执行其中的程序段,然后将执行结果连同JSP文件中的HTML代码一起返回给客户。插入的Java程序段可以操作数据库、重新定向网页等,以实现建立动态网页所需要的功能。 JSP与Java Servlet一样,是在服务器端执行的,通常返回该客户端的就是一个HTML文本,因此客户端只要有浏览器就能浏览。
JSP主要优点如下:
(1)一次编写,到处运行。在这一点上Java比PHP更出色,除了系统之外,代码不用做任何更改。
(2)系统的多平台支持。基本上可以在所有平台上的任意环境中开发,在任意环境中进行系统部署,在任意环境中扩展。相比JSP/PHP的局限性是显而易见的。
(3)强大的可伸缩性。从只有一个小的war文件就可以运行Servlet/JSP,到由多台服务器进行集群和负载均衡,到多台Application进行事务处理,消息处理,一台服务器到无数台服务器,Java显示了一个巨大的生命力。
(4)多样化和功能强大的开发工具支持。这一点与JSP很像,Java已经有了许多非常优秀的开发工具,而且许多可以免费得到,并且其中许多已经可以顺利的运行于多种平台之下。
1.4.2 Struts 框架
Struts是一个为开发基于模型(Model)-视图(View)-控制器(Controller)模式的应用框架的开源框架,是利用Java Servlet和JSP构建Web应用的一项非常有用的技术。事件是指从客户端页面(浏览器)由用户操作触发的事件,Struts使用Action来接受浏览器表单提交的事件,这里使用了Command模式,每个继承Action的子类都必须实现一个方法execute。在struts中,实际是一个表单form对应一个Action(或DispatchAction),换一句话说:在Struts中实际是一个表单只能对应一个事件,struts这种事件方式成为application event,application event和component event相比是一个粗粒度的事件。Struts重要的表单对象ActionForm是一种对象,它代表了一种应用,这个对象中至少包含几个字段,这些字段是Jsp页面表单中的input字段,因为一个表单对应一个事件,所以,当我们需要将时间粒度细化到表单中这些字段时,也就是说,一个字段对应一个事件时,单纯使用struts就不太可能,当然通过结合JavaScript也是可以转弯实现的。Struts是一个基于Sun J2EE平台的MVC框架,主要采用Servlet和JSP技术来实现的。
Struts框架可分为以下四个部分,其中三个就和MVC模式紧密相关:
(1)模型(Model),本质上来说在Struts中Model是一个Action类,开发者通过其实现业务逻辑,同时用户请求通过控制器(Controller)向Action的转发过程是基于由Struts-config.xml文件描述的配置信息的。
(2)视图(View),View是由与控制器Servlet配合工作的一整套JSP定制标签库构成,利用他们我们可以快速建立应用系统的界面。
(3)控制器(Controller),本质上是一个Servlet,将客户端请求转发到相应的Action类。
(4)XML文件解析的工具包,Struts是用XML来描述如何自动产生一些JAVABean的属性的,此外Struts还利用XML来描述国际化应用中的用户提示信息,这样一来就实现了应用系统的多种语言支持。
页面模板技术采用Apache组织的Tiles技术,可实现灵活的页面模板功能。
1.4.3 Hibernate数据访问框架
数据持久层采用Hibernate开源框架,它对JDBC进行了非常轻量级的对象封装,可以使程序员可以使用对象编程思维来操纵数据库。Hibernate是Java平台上的一种全功能的、开发源代码的 OR Mapping框架,支持java的JDO规范,它可以支持当前所有的主流关系型数据库和对象型数据库产品以及XML文件等数据源。与JDO不同,Hibernate完全着眼于关系数据库的OR映射,并且包括比大多数商业产品更多的功能。大多数EJB CMP CMR 解决方案使用程序代码产生持续性程序代码,而JDO使用字节码修饰;与之相反,Hibernate使用反射和执行时字节码产生,使它对于使用者几乎是透明的。
利用此框架可以以面向对象的方式来操作数据,可以容易的实现在各个应用数据库产品之间的移植,而不需要修改系统的大部分代码,同时也能很方便地实现同一个应用程序访问多个数据库的功能。利用此框架不但可以提高开发速度,而且可以使系统的可维护性、可移植性、可重用性提高。
1.4.4 B/S模式分析
C/S模式主要由客户应用程序(Client)、服务器管理程序(Server)和中间件(middleware)三个部件组成。客户应用程序是系统中用户与数据进行交互的部件。服务器程序负责有效地管理系统资源,如管理一个信息数据库,其主要工作是当多个客户并发地请求服务器上的相同资源时,对这些资源进行最优化管理。中间件负责联结客户应用程序与服务器管理程序,协同完成一个作业,以满足用户查询管理数据的要求。
B/S模式是一种以Web技术为基础的新型的MIS系统平台模式。把传统C/S模式中的服务器部分分解为一个数据服务器与一个或多个应用服务器(Web服务器),从而构成一个三层结构的客户服务器体系。
第一层客户机是用户与整个系统的接口。客户的应用程序精简到一个通用的浏览器软件,如Netscape Navigator,微软公司的IE等。浏览器将HTML代码转化成图文并茂的网页。网页还具备一定的交互功能,允许用户在网页提供的申请表上输入信息提交给后台,并提出处理请求。这个后台就是第二层的Web服务器。
第二层Web服务器将启动相应的进程来响应这一请求,并动态生成一串HTML代码,其中嵌入处理的结果,返回给客户机的浏览器。如果客户机提交的请求包括数据的存取,Web服务器还需与数据库服务器协同完成这一处理工作。 第三层数据库服务器的任务类似于C/S模式,负责协调不同的Web服务器发出的SQ请求,管理数据库。
B/S模式首先简化了客户端。它无需象C/S模式那样在不同的客户机上安装不同的客户应用程序,而只需安装通用的浏览器软件。这样不但可以节省客户机的硬盘空间与内存,而且使安装过程更加简便、网络结构更加灵活。假设一个企业的决策层要开一个讨论库存问题的企业采购,他们只需从企业采购室的计算机上直接通过浏览器查询数据,然后显示给大家看就可以了。甚至与会者还可以把笔记本电脑联上企业采购室的网络插口,自己来查询相关的数据。其次,它简化了系统的开发和维护。系统的开发者无须再为不同级别的用户设计开发不同的客户应用程序了,只需把所有的功能都实现在Web服务器上,并就不同的功能为各个组别的用户设置权限就可以了。各个用户通过HTTP请求在权限范围内调用Web服务器上不同处理程序,从而完成对数据的查询或修改。当形势变化时,它无须再为每一个现有的客户应用程序升级,而只需对Web服务器上的服务处理程序进行修订。这样不但可以提高公司的运作效率,还省去了维护时协调工作的不少麻烦。如果一个公司有上千台客户机,并且分布在不同的地点,那么便于维护将会显得更加重要。
再次,它使用户的操作变得更简单。对于C/S模式,客户应用程序有自己特定的规格,使用者无需接受专门培训。而采用B/S模式时,客户端只是一个简单易用的浏览器软件。无论是决策层还是操作层的人员都无需培训,就可以直接使用。B/S模式的这种特性,还使 MIS系统维护的限制因素更少。
最后,B/S特别适用于网上信息发布,使得传统的MIS的功能有所扩展。这是C/S所无法实现的。而这种新增的网上信息发布功能恰是现代企业所需的。这使得企业的大部分书面文件可以被电子文件取代,从而提高了企业的工作效率,使企业行政手续简化,节省人力物力。
鉴于B/S相对于C/S的先进性,B/S逐渐成为一种流行的MIS系统平台。各软件公司纷纷推出自己的Internet方案,基于Web的财务系统、基于Web的ERP。一些企业已经领先一步开始使用它,并且收到了一定的成效。 B/S模式的新颖与流行,和在某些方面相对于C/S的巨大改进,使B/S成了MIS系统平台的首选。本系统也采用B/S结构开发。
1.5 系统开发步骤
一般说来,管理信息系统的建立与应用可以划分成总体规划、系统开发和系统运行三个阶段,其中系统开发阶段还可进一步分为系统分析、系统设计和系统实施等工作环节。上述各个阶段排列成一个严格的线性开发序列,在每个工作阶段均产生完整的技术文档作为下一阶段工作的指导和依据,每一阶段都应对文档进行评审,确信该阶段工作已完成并达到要求后才能进入下一阶段,同时在以后的工作中不能轻易改变前面经过评审的成果。上述开发方式的主要优点是便于开发工作的组织和管理,并且可大大降低管理信息系统开发的复杂性。国内外许多系统开发的实例都证明这是一种行之有效的开发方式。
国外曾有人对一些软件项目开发各阶段的工作量进行统计结果表明,程序编写在开发工作中只占很小比例,而调试工作却占整个开发工作量的一半左右,因此“系统开发就是编程”的习惯说法显然是片面的。在建立管理信息系统的三个阶段中,总体规划和系统开发阶段的工作量约占整个工作量的2/3,而运行、维护阶段要占1/3,这说明一个管理信息系统开发后,仍应十分重视它的维护工作,以便使系统不断完善并充分发挥其作用。
第二章 需求分析及可行性分析
2.1需求分析
伴随着信息行业的蓬勃发展和人们办公自动化意识的增强,企业采购管理部门的工作也越来越繁重,原来的企业采购管理系统已经不能完全满足相关人员使用的需要。为了协助信息行业开展企业采购管理工作,提高工作效率,充分利用信息行业的现有资源,开发更好的企业采购管理系统势在必行。
企业采购管理系统是将IT技术用于企业采购信息的管理, 它能够收集与存储信息,提供更新与检索的接口;协助信息行业开展企业采购管理工作,提高工作效率。
企业采购管理系统采用B/S结构、结合网络数据库开发技术来设计本系统。开发语言采用JAVA,数据库使用SQL Server2008数据库。完成以下基本功能:
本系统是一个独立的系统,用来解决企业采购信息的管理问题。采用JSP技术构建了一个有效而且实用的企业采购信息管理平台,目的是为高效地完成对企业采购信息的管理。
企业采购管理系统具有标准企业采购管理系统所具有的现实中完整的企业采购管理步骤,完全的虚拟现实实现。真正实现节约资源、提高效率、业务处理的同时真正实现企业采购管理系统的功能作用。
2.1.2运行需求分析
硬件系统环境:Core 5600、1G MB(RAM)、120GB(HD)。系统运行时对数据的保密性要求不高对一般的数据不要求进行加密。此外,对其它软件几乎没有依赖性,程序健壮性较好
2.1.3其他需求分析
系统的性能要求通常指系统需要的存储容量以及后援存储,重新启动和安全性,运行效率等方面的考虑。本系统要有较好的可维护性、可靠性、可理解性、效率。要易于用户理解和操作。可维护性包括了可读性、可测试性等含义。可靠性通常包括正确性和健壮性。开发过程中,在各种矛盾的目标之间作权衡,并在一定的限制的条件下(经费、时间、可用的软、硬件资源等),使上述各方面最大限度的得到满足。
2.2 可行性分析
2.2.1经济可行性
经济可行性研究是对组织的经济现状和投资能力进行分析,对系统建设运行和维护费用进行估算,对系统建成后可能取得的社会和经济效益进行估计。由于本系统是作为毕业设计由自己开发的,在经济上的投入甚微,系统建成之后将为今后企业采购信息管理提供很大的方便,估算新系统的开发费用和今后的运行、维护费用,估计新系统将获得的效益,并将费用与效益进行比较,看是否有利。开发、运行和维护费用主要包括:
购买和安装企业采购的费用:计算机硬件、系统软件、 机房、电源、空调等;软件开发费用:若由实习单位的技术人员开发,则该项费用可以计入下面的人员费用一项;人员费用:系统开发人员、操作人员和维护人员的工资、培训费用等;消耗品费用:系统开发所用材料、系统正常运行所用消耗品,例如水、电费,打印纸、软盘、色带等开支。所有开支都不大,所以经济上是可行的。
2.2.2技术可行性
技术可行性要考虑现有的技术条件是否能够顺利完成开发工作,软硬件配置是否满足开发的需求等。企业采购管理系统用的是JSP开发语言,调试相对简单,当前的计算机硬件配置也完全能满足开发的需求,因此在技术上是绝对可行的。软件方面:由于目前B/S模式软件相对发展成熟,Eclipse已发行多个版本,渐趋完善,故软件的开发平台成熟可行,它们速度快、容量大、可靠性能高、价格低,完全能满足系统的需求。
2.2.3 运行可行性
对新系统运行后给现行系统带来的影响(包括组织机构、管理方式、工作环境等)和后果进行估计和评价。同时还应考虑现有管理人员的培训、补充,分析在给定时间里能否完成预定的系统开发任务等。
运行可行性是对组织结构的影响,现有人员和机构以及环境对系统的适应性及人员培训补充计划的可行性。当前我国信息化技术已经相当普及,各类操作人员水平都有相当的高度,所以在运行上是可行性的。
本系统的开发,是典型的Mis开发,主要是对数据的处理,包括数据的收集,数据的变换,及数据的各种形式的输出。采用流行的JSP+SQL Server2008体系,已无技术上的问题。
2.2.4时间可行性
从时间上看,在四个月的时间里学习相关知识,并开发企业采购信息管理系统,时间上是有点紧,但是不是不可能实现,通过四个多月的努力功能应该基本实现。
2.2.5 法律可行性
① 所有技术资料都为合法。
② 开发过程中不存在知识产权问题。
③ 未抄袭任何已存在的企业采购信息管理系统,不存在侵犯版权问题。
④ 开发过程中未涉及任何法律责任。
综上所述,本系统的开发从技术上、从经济上、从法律上都是完全可靠的。
第三章 系统分析与设计
3.1系统实现目标
采购是公司生产产品及维护正常运作而必须消耗的物品及必须配置的设施的购入活动的总称,是公司成本控制的重点。无论是公司管理者还是财务部门,对采购工作存在的风险都有着非常强的敏感性,这不仅因为采购是直接影响生产成本的主要因素,而是因为采购有着很高的认为欺诈的可能。在日趋完善的现代经营管理模式中,公司管理当局越来越注重财务管理和财务运作的有效性。
合理的采购管理具有很重要的意义:
建立和实施制度化的采购管理程序,这是采购管理工作有效进行的根本保证,有法必依,违法必究,这是制度能切实贯彻执行的保证。只有制度化了,才能在公司中用法制,而不是人治。采购管理系统是为了实现企业的长远发展目标而实施的一个系统工程,也是一个企业能否取得经济效益的关键它能够为企业的发展提供科学的管理功能,减少管理费用。利用计算机的数据库技术,使得企业的采购、库存和销售能够有利的结合起来,避免和克服人工管理信息时,劳动量大,计算和统计的不准确等种种缺陷和弊端,使企业的管理规范化和自动化,从而对采购管理提供更加科学、准确的数据,实现了采购管理的系统化、规范化和自动化。通过使用采购管理系统能够降低材料采购成本在企业经营中所占的比例,能够提高企业的利润。
企业为满足生产所需和提高生产效率,将开发企业采购管理系统。
系统实现目标:易于操作,有良好的互动性,能为员工的工作带来便易。开发出来的系统还必须是安全性高,扩展性强。能在日后不断升级优化。
3.2 系统设计
3.2.1系统设计
该系统采用B/S体系结构,在客户机上并不安装客户端,而是使用网络浏览器,这样节省一大部分开发、维护和升级报销。本系统不仅要求功能完善,而且还要界面友好,因此,对于一个成功的系统设计,功能模块的设计是关键。
本系统是一个独立的系统,用来解决企业采购信息的管理问题。采用JSP技术构建了一个有效而且实用的企业采购信息管理平台,目的是为高效地完成对企业采购信息的管理。经过对课题的深入分析,采购系统需实现以下功能模块:
各个模块实现的功能如下:
根据关键字快速检索信息。
3.3数据库设计
3.3.1数据库概述
数据库设计就是针对应用需求和环境,建立合理的数据库模式和存储结构,保证数据的高效存取,并满足应用的任务处理要求。数据库设计是应用系统建设的核心技术,是数据库应用领域的主要研究课题。
数据库是数据管理的最新技术。十多年来数据库管理系统已从专用的应用程序发展成为通用的系统软件。由于数据库具有数据结构化,最低冗余度,较高的程序与数据独立性,易于扩充,易于编制应用程序等优点,较大的信息系统都是建立在数据库设计之上的。因此不仅大型计算机及中小型计算机,甚至微型机都配有数据库管理系统。
设计数据库必须遵循一定的规则,在关系型数据库中,这种规则就是范式,范式是符合某一种级别的关系模式的集合。一般人们设计数据库遵循第三范式。即:数据库表中不包含已在其他表中包含的非主关键字信息。采用范式减少了数据冗余,节约了存储空间,同时加快了增、删、改的速度。
本系统是用SQL Server2008作为系统数据库。SQL Server是由微软公司研制和发布的分布式关系型数据库管理系统,可以支持企业、部门以及个人等各种用户完成信息系统、电子商务、决策支持、商业智能等工作。SQL Server2008系统只要由4个主要部分组成。这四个部分被称为4个服务,这些服务分别是数据库引擎、分析服务、报表服务和集成服务。这些服务之间相互存在和相互应用。SQL Server2008在易用性、可用性、可管理性、可编程性、动态开发、运行性能等方面有突出的优点。SQL Server 2008还增强了审查,使你可以审查你的数据的操作,从而提高了遵从性和安全性。审查不只包括对数据修改的所有信息,还包括关于什么时候对数据进行读取的信息。SQL Server 2008具有像服务器中加强的审查的配置和管理这样的功能,这使得公司可以满足各种规范需求。SQL Server 2008还可以定义每一个数据库的审查规范,所以审查配置可以为每一个数据库作单独的制定。为指定对象作审查配置使审查的执行性能更好,配置的灵活性也更高。提供了稀疏列,这个功能使NULL数据不占物理空间,从而提供了一个非常有效的管理数据库 中的空数据的方法。例如,稀疏列使得一般包含极多要存储在一个SQL Server 2008数据库中的空值的对象模型不会占用很大的空间。稀疏列还允许管理员创建1024列以上的表。
3.3.2数据库实现
本系统一共设计五张表,分别是t_order,t_price,t_supplier,t_user,t_product.
t_order表存放订单,t_price表存放付款单,t_supplier表存放供应商,t_user表存放用户信息,t_product存放材料信息。
t_order(id,ordername,productid,supplierid,num,status,numb,price,allprice,username);
t_price(id,pricename,productid,supplierid,price,status,username,remark,inputdate);
t_supplier(id,suppliername,phone,adrr,mun,username,web,email,remark);
t_user(id,username,password,realname,power,);
t_product(id,productname,num,inputdate,counts,remark);
3.4系统体系结构
在系统功能分析的基础上,系统功能模块图如下图3-1所示:
图3-1 系统体系结构
系统有四个主要功能,分别是用户登录,基础信息管理,订单管理,采购查询。其中基础信息管理可以对用户信息,材料信息,供应商信息及订单信息进行管理。订单管理功能对订单进行管理,整个系统中,会有7种状态的订单。采购查询,是系统为用户提供的便捷查询方式,根据关键字,即可快速检索出需要查询的信息。
3.5系统流程图
系统流程图如图3-2所示:
输入用户名、密码
密码正确?
N
N
进入主控模块
选择操作方式
退出系统
Y
图3-2 主控流程图
用户输入用户名及密码,系统会进行匹配查询,如果在数据库中,有匹配的用户信息,则可以登录。且系统有4种权限的用户,分别是管理员,审批员,采购员及仓库管理员,不同权限的用户,有不同的操作权限。
采购流程如图3-3所示:
创建采购单
创建采购单
N
审批
审批
Y
采购
退出系统
图3-3 采购流程
采购员创建采购单后,提交审批。审批成功后,则开始采购,审批不成功,则重新创建采购单或修改订单,重新提交审批。
退货流程如图3-4所示:
检验物品
Y
N
创建退货单
审批
N
确认收货
Y
退货
退出系统
图3-4 退货流程
仓库管理员对入库的物品进行质量检验,对质量不合格的物品申请退货,并提交退货单等待审批。审批成功的退货单,进行退货,审批不成功则重新创建退货单或者修改退货单。对于质量合格的物品,直接确认收货。
3.6系统用例图
管理员用例图如图3-5所示:

图3-5 管理员用例图
采购员用例图如图3-6所示:
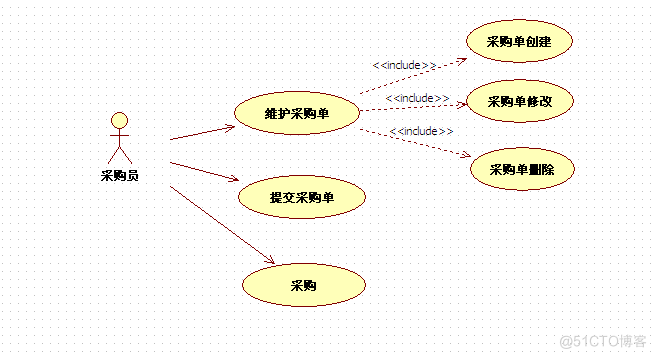
图3-6 采购员用例图
审批员用例图如图3-7所示:
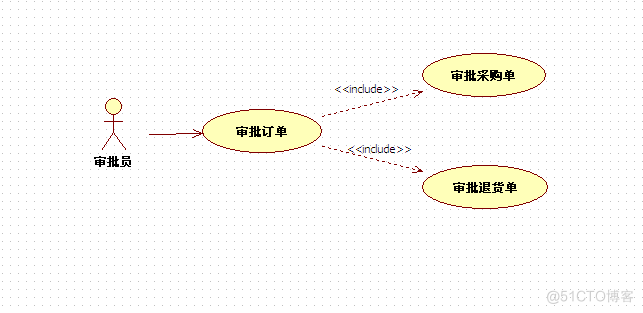
图3-7 审批员用例图
仓库管理员用例图如图3-8所示:
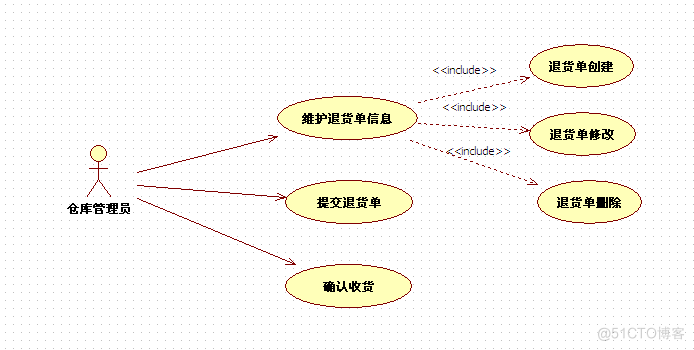
图3-8 仓库管理员用例图
第四章 系统实现
4.1.系统实现
4.1.1 登录模块
对于一个完整的企业采购管理系统,不仅要求功能强大、操作简单,还要有良好的设计风格和另人爽目的界面。登录界面对于整个系统来说是非常重要的,因为它设置了进入本系统的用户和口令,防止非法用户进入系统,破坏系统安全和所保存的数据,只有合法的管理员在输入正确的密码后方可进入系统,否则将提示密码或用户名输入错误,并询问用户是否重新输入。这样就对使用者有了限制,增加了系统的安全性和保密性,便于控制和管理,有利于系统的维护。
登陆界面如图4-1所示:

图 4-1 登录界面
当用户没有输入用户名时,系统会弹出这样的提示框,如图4-2所示:

图 4-2 错误登录页面1
当用户没有输入密码时,系统会弹出这样的提示框,如图4-3所示:

图4-3 错误登录页面2
当用户名或密码不正确时,会提示信息错误,请重新填写,如图4-4所示:

图4-4 错误登录界面3
登录界面代码实现:
public class LoginAction extends BaseAction{
private LoginServices loginServices;
private Integer id;
private String username;
private String password;
private String realname;
public String checkUser() throws Exception{
if (!(StringUtils.isEmpty(username)|| StringUtils.isEmpty(password))) {
TUser user = loginServices.checkUser(username,password);
if (user!=null) {
setSessionAttribute("user", user);
return SUCCESS;
}
setRequestAttribute("error", "error");
}
return ERROR;
}
public String updateUser() throws Exception{
TUser user = new TUser();
user.setId(id);
user.setPassword(password);
user.setUsername(username);
user.setRealname(realname);
loginServices.updateUser(user);
setSessionAttribute("user", user);
return "update";
}
}
}
<script type="text/javascript">
function commit() {
if(form1.username.value=="") {
alert("请您输入用户名!");
form1.username.focus();
return false;
}
if(form1.password.value=="") {
alert("请您输入密码!");
form1.password.focus();
return false;
}
return true;
}
登录界面设计代码:
</script>
<table width="100%" border="0" cellspacing="0" cellpadding="0">
<tr>
<td width="31%" height="35" class="login-text02">帐号 <br /></td>
<td width="69%"><input name="username" id= "username" type="text" size="28" style="width:150px" /></td>
</tr>
<tr>
<td height="35" class="login-text02">密码 <br /></td>
<td><input name="password" id="password" type="password" size="30" style="width:150px"/></td>
</tr>
<tr>
<td height="35"> </td>
<td><input name="Submit2" type="submit" class="right-button02" value="登 录" />
<input name="reset232" type="reset"" class="right-button02" value="重 置" />
</tr>
<%
if("error".equals((String)request.getAttribute("error"))){ %>
<font color="red">信息错误,请重新填写!</font>
<%}%>
</table>
4.1.2系统主界面
当使用管理员身份登录的主界面,如图4-5所示:

图4-5 管理员主界面
当用户身份为管理员时,则拥有系统的最高权限,可以创建四种权限的用户身份。分别是管理员,采购员,审批员及仓库管理员。
当使用普通用户登录时主界面,如图4-6所示:

图4-6 普通用户主界面
普通用户是和管理员相对的用户身份,包括采购员,仓库管理员,审批人员三种,由管理员进行创建。每种身份有对应的操作权限。并且不能越权操作。
采购员:创建原始采购单,提交采购申请,对审批通过的采购订单进行采购。
审批人员:对提交的采购订单及退货单进行审批;
仓库管理员:对到达货物进行质量检验,产品合格则确认收货,产品不合格,则创建退货单,等待审批。
4.1.3用户操作
使用管理员身份登录时,可以查看用户的信息,并对用户进行增、删、改、查操作:
当使用管理员身份时,可以对用户信息进行查看,如图4-7所示:

图 4-7 用户信息
当使用管理员身份登录时,可以创建不同权限的用户,如图4-8所示:

图 4-8 创建用户
当使用管理员的身份登录时,可以修改用户的信息(但是用户创建之后,用户名是不允许进行修改的),如图4-9所示:

图4-9 修改用户信息
用户管理代码实现:
public class UserAction extends BaseAction{
添加:
public String addUser() throws Exception{
TUser user = new TUser();
user.setPassword(password);
user.setPower(power);
user.setRealname(realname);
user.setUsername(username);
userServices.addUser(user);
return "addUser";
}
public String preupdateUser() throws Exception{
TUser user = userServices.getUser(id);
setRequestAttribute("user",user);
return "preupdateUser";
}
修改:
public String updateUser() throws Exception{
TUser user = userServices.getUser(id);
user.setPassword(password);
user.setRealname(realname);
user.setPower(power);
userServices.updateUser(user);
return "updateUser";
}
删除:
public String delUser() throws Exception{
userServices.delUser(id);
return "delUser";
}
}
}
4.1.4供应商管理
供应商管理模块是本系统中一个基础的部分,在本模块中包括对供应商信息的增删改查功能,确保资料的安全。增加了系统的安全性和保密性,便于控制和管理。及时的更新供应商信息,可以帮助企业做正确的采购策略。
查询供应商信息,如图4-10所示:

图4-10 查询供应商信息
添加供应商信息,这里要求要将所有供应商的信息添加完全,详细的展示供应商信息,是企业能够全面了解供应商信息,更好的制定采购计划,如图4-11所示:

图 4-11添加供应商
修改供应商信息,可以对供应商信息进行及时的更新,如图4-12所示:

图 4-12 修改供应商信息
供应商模块关键代码实现:
public class SupplierAction extends BaseAction{
添加:
public String addSupplier() throws Exception{
TSupplier supplier = new TSupplier();
supplier.setAdrr(adrr);
supplier.setPhone(phone);
supplier.setSuppliername(suppliername);
supplier.setEmail(email);
supplier.setNum(num);
supplier.setRemark(remark);
supplier.setUsername(username);
supplier.setWeb(web);
supplierServices.addSupplier(supplier);
return "addSupplier";
}
public String preupdateSupplier() throws Exception{
TSupplier supplier = supplierServices.getSupplier(id);
setRequestAttribute("supplier",supplier);
return "preupdateSupplier";
}
修改:
public String updateSupplier() throws Exception{
TSupplier supplier = supplierServices.getSupplier(id);
supplier.setAdrr(adrr);
supplier.setPhone(phone);
supplier.setSuppliername(suppliername);
supplier.setEmail(email);
supplier.setNum(num);
supplier.setRemark(remark);
supplier.setUsername(username);
supplier.setWeb(web);
supplierServices.updateSupplier(supplier);
return "updateSupplier";
}
删除:
public String delSupplier() throws Exception{
supplierServices.delSupplier(id);
return "delSupplier";
}
public SupplierServices getSupplierServices() {
return supplierServices;
}
public void setSupplierServices(SupplierServices supplierServices) {
this.supplierServices = supplierServices;
}
4.1.5材料信息管理
本模块主要实现材料信息的增加、删除、修改、浏览等操作。将以前采购过的材料、将要进行采购的材料以及正在考虑采购的材料信息录入系统,便于企业查询和管理。如下图所示:
材料信息查询,如图4-13所示:

图4-13 查询材料信息
材料信息添加,需要添加材料的名称、编号、出厂日期、数量、以及备注信息,要求必须添加完整。提供重置按钮,点击后,可以重写填写,如图4-14所示:

图4-14 修改材料信息
对材料信息进行修改,及时更新材料信息,保证所有的信息都是最新状态,如图4-15所示:

图4-15 修改材料信息
材料模块关键代码实现:
public class ProductAction extends BaseAction{
添加:
public String addProduct() throws Exception{
TProduct product = new TProduct();
product.setProductname(productname);
product.setInputdate(inputdate);
product.setNum(num);
product.setCounts(counts);
product.setRemark(remark);
productServices.addProduct(product);
return "addProduct";
}
public String preupdateProduct() throws Exception{
TProduct product = productServices.getProduct(id);
setRequestAttribute("product",product);
return "preupdateProduct";
}
修改:
public String updateProduct() throws Exception{
TProduct product = productServices.getProduct(id);
product.setProductname(productname);
product.setInputdate(inputdate);
product.setNum(num);
product.setCounts(counts);
product.setRemark(remark);
productServices.updateProduct(product);
return "updateProduct";
}
删除:
public String delProduct() throws Exception{
productServices.delProduct(id);
return "delProduct";
}
public ProductServices getProductServices() {
return productServices;
}
public void setProductServices(ProductServices productServices) {
this.productServices = productServices;
}
4.1.6订单信息管理
本模块主要实现对订单进行操作。系统中共设计了多种状态的订单。分别是新建采购单,审批中的采购单,审批成功的采购单,审批失败的采购单,新建退货单,审批中的退货单,审批成功的退货单,审批失败的退换单,已完成订单。新建的如下图所示:
已完成订单信息查询:
当采购员采购完成之后,由仓库管理员进行质量检验,物品质量合格之后,由采购员确认收货,订单会变为完成状态。
已完成订单,如图4-16所示:

图 4-16 已完成订单
采购员专区:
采购员根据采购计划创建采购单,等待审批人员进行审批,如图4-17所示:

图4-17 采购专区
审批员专区:由审批员对采购单及退货单进行审批,审批员可以将订单置为两种状态,审批成功和审批失败,且一定要填写审批理由,如图4-18所示:

图4-18 审批专区
仓库管理:
仓库管理员对采购员采购的物品进行质量检验,如果合格则确认收货,如果不合格则申请退货,等待审批人员进行审批,如图4-19所示:

图4-19 仓库管理专区
快捷预览区域:
该区域只提供对订单的预览,不提供操作。包括未完成订单,已完成订单,未付款单,退货单。
未完成订单,包括待付款单,审批失败订单,未审批订单:
未完成订单如图4-20所示:

图 4-20 未完成订单
未付款订单,采购完成的订单,等待仓库管理员对物品质量进行检验:
待付款订单如图4-21所示:

图 4-21 待付款订单
退货单,仓库管理员对物品进行质量检验,不合格的产品进行退货申请,由审批人员进行审批,通过审批后的退货单进行退货,完成退货后。退货单可在快捷预览区域的退货单中进行查看。
退货单如图4-22所示:

图4-22 退货单
订单模块关键代码实现:
public class OrderAction extends BaseAction{
为采购员获取订单数据:
public String purchaseOrder() throws Exception{
PageInfo pageInfo0 =queryOrderByStatus("('0','3')");
PageInfo pageInfo2 =queryOrderByStatus("('2')");
setRequestAttribute("pageinfo0", pageInfo0);
setRequestAttribute("pageinfo2", pageInfo2);
setRequestAttribute("searchname", this.searchname);
return "purchaseOrder";
}
为审批员获得订单:
public String approveListOrder() throws Exception{
PageInfo pageInfo0 =queryOrderByStatus("('1')");
PageInfo pageInfo2 =queryOrderByStatus("('6')");
setRequestAttribute("pageinfo0", pageInfo0);
setRequestAttribute("pageinfo2", pageInfo2);
setRequestAttribute("searchname", this.searchname);
return "approveListOrder";
}
public String storeListOrder() throws Exception{
StringBuffer cond = new StringBuffer();
if(null!=searchname&&""!=searchname.trim()){
cond.append(" and a.ordername like '%"+searchname.trim()+"%' ");
}
if(null!=getRequestParameter("flag") &&""!=getRequestParameter("flag")){
setSessionAttribute("flag", getRequestParameter("flag"));
}
if(null!=getSessionAttribute("flag") &&""!=(String)getSessionAttribute("flag")){
cond.append(" and a.status = '"+(String)getSessionAttribute("flag")+"' ");
}
int curpage = Integer.parseInt(this.getCurrentpage(ServletActionContext.getRequest()));
int pageunit = Integer.parseInt(this.getPageunit(ServletActionContext.getRequest(), "querypageunit"));
String url = "order_storeListOrder?a=a";
PageInfo pageInfo = this.orderServices.queryOrder(curpage,
pageunit, ServletActionContext.getRequest(), url, cond.toString());
setRequestAttribute("pageinfo", pageInfo);
setRequestAttribute("searchname", this.searchname);
return "storeListOrder";
}
public String addOrderForPurchase(){
try {
TOrder order = new TOrder();
order.setNum(num);
order.setOrdername(ordername);
order.setStatus("0");
TProduct product = productServices.getProduct(productid);
order.setTProduct(product);
TSupplier supplier = supplierServices.getSupplier(supplierid);
order.setTSupplier(supplier);
order.setNumb(numb);
order.setPrice(price);
order.setRemark(remark);
order.setAllprice(allprice);
order.setUsername(username);
orderServices.addOrder(order);
} catch (RuntimeException e) {
e.printStackTrace();
}
return "addOrderForPurchase";
}
public String updateOrderForPurchase() {
try {
TOrder order = this.getOrderServices().getOrder(id);
order.setNum(num);
order.setOrdername(ordername);
TProduct product = productServices.getProduct(productid);
order.setTProduct(product);
TSupplier supplier = supplierServices.getSupplier(supplierid);
order.setTSupplier(supplier);
order.setNumb(numb);
order.setPrice(price);
order.setRemark(remark);
order.setAllprice(allprice);
order.setUsername(username);
this.getOrderServices().updateOrder(order);
} catch (RuntimeException e) {
e.printStackTrace();
}
return "updateOrderForPurchase";
}
public String approveOrder() throws Exception{
TOrder order = this.getOrderServices().getOrder(id);
order.setStatus("1");
this.getOrderServices().updateOrder(order);
return "approveOrder";
}
采购申请:
public String applyOrder() throws Exception{
TOrder order = this.getOrderServices().getOrder(id);
order.setStatus("1");
this.getOrderServices().updateOrder(order);
return "applyOrder";
}
采购:
public String buyOrder() throws Exception{
TOrder order = this.getOrderServices().getOrder(id);
order.setStatus("4");
this.getOrderServices().updateOrder(order);
return "buyOrder";
}
合格检查:
public String TestOrder() throws Exception{
TOrder order = this.getOrderServices().getOrder(id);
order.setStatus("5");
this.getOrderServices().updateOrder(order);
return "TestOrder";
}
退货检查:
public String returnOrder() throws Exception{
TOrder order = this.getOrderServices().getOrder(id);
order.setStatus("6");
this.getOrderServices().updateOrder(order);
return "returnOrder";
}
审批:
public String approveOrderForApproveList() throws Exception{
TOrder order = this.getOrderServices().getOrder(id);
order.setRemark(remark);
order.setStatus(status);
this.getOrderServices().updateOrder(order);
return "approveOrderForApproveList";
}
}
}
4.1.7信息查询
该功能提供对信息的快速查询,分别针对用户信息,供应商信息,材料信息,订单信息设计了不同的关键词检索,提高检索效率:
用户信息查询,根据账号进行查询,如图4-23所示:

图 4-23 用户信息查询
public String queryUser() throws Exception{
if (getSessionAttribute("querypageunit") == null) {
setSessionAttribute("querypageunit",this.pageunit);
}
StringBuffer cond = new StringBuffer();
if(null!=searchname&&""!=searchname.trim()){
cond.append(" and a.username like '%"+searchname.trim()+"%' ");
}
//cond.append(" and a.power =1 ");
int curpage = Integer.parseInt(this.getCurrentpage(ServletActionContext.getRequest()));
int pageunit = Integer.parseInt(this.getPageunit(ServletActionContext.getRequest(), "querypageunit"));
String url = "user_queryUser?a=a";
PageInfo pageInfo = this.userServices.queryUser(curpage,
pageunit, ServletActionContext.getRequest(), url, cond.toString());
setRequestAttribute("pageinfo", pageInfo);
setRequestAttribute("searchname", this.searchname);
return "queryUser";
}
供应商信息查询,根据名称进行查询,如图4-24所示:
图4-24 供应商信息查询
供应商信息查询关键代码实现:
public String querySupplier() throws Exception{
if (getSessionAttribute("querypageunit") == null) {
setSessionAttribute("querypageunit",this.pageunit);
}
StringBuffer cond = new StringBuffer();
if(null!=searchname&&""!=searchname.trim()){
cond.append(" and a.suppliername like '%"+searchname.trim()+"%' ");
}
int curpage = Integer.parseInt(this.getCurrentpage(ServletActionContext.getRequest()));
int pageunit = Integer.parseInt(this.getPageunit(ServletActionContext.getRequest(), "querypageunit"));
String url = "supplier_querySupplier?a=a";
PageInfo pageInfo = this.supplierServices.querySupplier(curpage,
pageunit, ServletActionContext.getRequest(), url, cond.toString());
setRequestAttribute("pageinfo", pageInfo);
setRequestAttribute("searchname", this.searchname);
return "querySupplier";
}
材料信息查询,根据材料名称进行查询,如图4-25所示:
图4-25 材料信息查询
材料查询代码实现:
public String queryProduct() throws Exception{
if (getSessionAttribute("querypageunit") == null) {
setSessionAttribute("querypageunit",this.pageunit);
}
StringBuffer cond = new StringBuffer();
if(null!=searchname&&""!=searchname.trim()){
cond.append(" and a.productname like '%"+searchname.trim()+"%' ");}
int curpage = Integer.parseInt(this.getCurrentpage(ServletActionContext.getRequest()));
int pageunit = Integer.parseInt(this.getPageunit(ServletActionContext.getRequest(), "querypageunit"));
String url = "product_queryProduct?a=a";
PageInfo pageInfo = this.productServices.queryProduct(curpage,
pageunit, ServletActionContext.getRequest(), url, cond.toString());
setRequestAttribute("pageinfo", pageInfo);
setRequestAttribute("searchname", this.searchname);
return "queryProduct";}
订单信息查询,根据订单名称进行查询,如图4-26所示:

图 4-26 订单信息查询
public String queryOrder() throws Exception{
if (getSessionAttribute("querypageunit") == null) {
setSessionAttribute("querypageunit",this.pageunit);
}
StringBuffer cond = new StringBuffer();
if(null!=searchname&&""!=searchname.trim()){
cond.append(" and a.ordername like '%"+searchname.trim()+"%' ");
}
if(null!=getRequestParameter("flag") &&""!=getRequestParameter("flag")){
setSessionAttribute("flag", getRequestParameter("flag"));
}
if(null!=getSessionAttribute("flag") &&""!=(String)getSessionAttribute("flag")){
cond.append(" and a.status = '"+(String)getSessionAttribute("flag")+"' ");
}
int curpage = Integer.parseInt(this.getCurrentpage(ServletActionContext.getRequest()));
int pageunit = Integer.parseInt(this.getPageunit(ServletActionContext.getRequest(), "querypageunit"));
String url = "order_queryOrder?a=a";
PageInfo pageInfo = this.orderServices.queryOrder(curpage,
pageunit, ServletActionContext.getRequest(), url, cond.toString());
setRequestAttribute("pageinfo", pageInfo);
setRequestAttribute("searchname", this.searchname);
return "queryOrder";
}
第五章 系统测试
5.1系统调试
5.1.1 程序调试
在设计系统的过程中,存在一些错误是必然的。对于语句的语法错误,在程序运行时自动提示,并请求立即纠正,因此,这类错误比较容易发现和纠正。但另一类错误是在程序执行时由于不正确的操作或对某些数据的计算公式的逻辑错误导致的错误结果。这类错误隐蔽性强,有时会出现,有时又不出现,因此,对这一类动态发生的错误的排查是耗时费力的。
5.2 程序测试
5.2.1 测试的重要性及目的
(1)测试的重要性
对于软件来讲,不论采用什么技术和什么方法,软件中仍然会有错。采用新的语言、先进的开发方式、完善的开发过程,可以减少错误的引入,但是不可能完全杜绝软件中的错误,这些引入的错误需要测试来找出,软件中的错误密度也需要测试来进行估计。测试是所有工程学科的基本组成单元,是软件开发的重要部分。自有程序设计的那天起测试就一直伴随着。统计表明,在典型的软件开发项目中,软件测试工作量往往占软件开发总工作量的40%以上。而在软件开发的总成本中,用在测试上的开销要占30%到50%。如果把维护阶段也考虑在内,讨论整个软件生存期时,测试的成本比例也许会有所降低,但实际上维护工作相当于二次开发,乃至多次开发,其中必定还包含有许多测试工作。
在实践中,软件测试的困难常常使人望而却步或敷衍了事,这是由于对测试仍然存在一些不正确的看法和错误的态度,这包括:
① 认为测试工作不如设计和编码那样容易取得进展难以给测试人员某种成就感;
② 以发现软件错误为目标的测试是非建设性的,甚至是破坏性的,测试中发现错位是对责任者工作的一种否定;
③ 测试工作枯燥无味,不能引起人们的兴趣;
④ 测试工作是艰苦而细致的工作;
⑤ 对自己编写的程序盲目自信,在发现错误后,顾虑别人对自己的开发能力的看法。
这些观点对软件测试工作是极为不利的,必须澄清认识、端正态度,才可能提高软件产品的质量。
(2)测试的目的
如果测试的目的是为了尽可能多地找出错误,那么测试就应该直接针对软件比较复杂的部分或是以前出错比较多的位置。
① 软件测试是为了发现错误而执行程序的过程;
② 测试是为了证明程序有错,而不是证明程序无错误;
③ 一个好的测试用例是在于它能发现至今未发现的错误;
④ 一个成功的测试是发现了至今未发现的错误的测试。
这种观点可以提醒人们测试要以查找错误为中心,而不是为了演示软件的正确功能。但是仅凭字面意思理解这一观点可能会产生误导,认为发现错误是软件测试的唯一目,查找不出错误的测试就是没有价值的,事实并非如此。
首先,测试并不仅仅是为了要找出错误。通过分析错误产生的原因和错误的分布特征,可以帮助项目管理者发现当前所采用的软件过程的缺陷,以便改进。同时,这种分析也能帮助我们设计出有针对性地检测方法,改善测试的有效性。其次,没有发现错误的测试也是有价值的,完整的测试是评定测试质量的一种方法。
5.2.2 测试的步骤
与开发过程类似,测试过程也必须分步骤进行,每个步骤在逻辑上是前一个步骤的继续。大型软件系统通常由若干个子系统组成,每个子系统又由若干个模块组成。因此,大型软件系统的测试基本上由下述几个步骤组成:
(1)模块测试 在这个测试步骤中所发现的往往是编码和详细设计的错误。
(2)系统测试 在这个测试步骤中发现的往往是软件设计中的错误,也可能发现需求说明中的错误。
(3)验收测试 在这个测试步骤中发现的往往是系统需求说明书中的错误。
5.2.3 测试的主要内容
为了保证测试的质量,将测试过程分成几个阶段,即:代码审查、单元测试、集成测试、确认测试和系统测试。
(1)单元测试
单元测试集中在检查软件设计的最小单位—模块上,通过测试发现实现该模块的实际功能与定义该模块的功能说明不符合的情况,以及编码的错误。
(2)集成测试
集成测试是将模块按照设计要求组装起来同时进行测试,主要目标是发现与接口有关的问题。如一个模块与另一个模块可能有由于疏忽的问题而造成有害影响;把子功能组合起来可能不产生预期的主功能;个别看起来是可以接受的误差可能积累到不能接受的程度;全程数据结构可能有错误等。
(3)确认测试
确认测试的目的是向未来的用户表明系统能够像预定要求那样工作。经集成测试后,已经按照设计把所有的模块组装成一个完整的软件系统,接口错误也已经基本排除了,接着就应该进一步验证软件的有效性,这就是确认测试的任务,即软件的功能和性能如同用户所合理期待的那样。
(4)系统测试
软件开发完成以后,最终还要与系统中其他部分配套运行,进行系统测试。包括恢复测试、安全测试、强度测试和性能测试等。
单独对系统的测试主要从以下几方面入手:
① 功能测试:测试是否满足开发要求,是否提供设计所描述的功能,是否用户的需求都得到满足。功能测试是系统测试最常用和必须的测试,通常还会以正式的软件说明书为测试标准。
② 强度测试及性能测试:测试系统能力最高实际限度,即软件在一些超负荷情况下功能实现的情况。
③ 安全测试:验证安装在系统内的保护机构确实能够对系统进行保护,使之不受各种非常的干扰。针对本系统主要是对权限系统的测试和对无效数据、错数据、和非法数据干扰的能力的测试。
(1) 测试案例的内容
周期:测试时间域。
层次:测试的层面。
类型:测试的分类。
系统:测试何系统。
分系统: 测试何分系统。
模块: 测试何模块。
平台: 测试的环境。
描述: 对测试问题说明与叙述。
目的: 测试的目标与期望。
此外,还包括测试文档号、测试设置、输入条件、测试结果和期望结果。
(2) 测试案例与脚本
1)测试案例与脚本设计主要包括以下内容:
检查集成测试策略
制定测试数据目的和性能目标
找出关键测试条件
检查已有的在线测试脚本
输入或抓取在线测试脚本
检查已有的用于测试的数据
生成测试数据
检查重要的数据
执行测试数据和测试脚本
2)本系统测试案例如下:
方 法: 功能模块测试方法
目 的: 测试录入功能的正确性
预期结果: 有出错警告
过 程: 在用户管理中,没有选择任何选项,直接提交
输 入: 无输入
测试结果: 无法保存,有出错警告
比 较: 与预期结果相当
结 论: 正确
方 法: 功能模块测试方法
目 的: 测试录入功能的正确性
预期结果: 有出错警告
过 程: 在提交信息中,不输入任何数据,直接提交
输 入: 无输入
测试结果: 无法保存,有出错警告
比 较: 与预期结果相当
结 论: 正确
方 法: 功能模块测试方法
目 的: 测试录入功能的正确性
预期结果: 有出错警告
过 程: 在系统操作中,不输入任何信息,直接提交
输 入: 无输入
测试结果: 无法保存,有出错警告
比 较: 与预期结果相当
结 论: 正确
表5-1 测试用例描述
只有系统的测试工作在用户的协助下,不断的修改,才能达到完善的预期目标。本企业采购信息管理系统系统经过初步测试,基本上达到目标。
结束语
几个月来忙碌紧张而又有条不紊的毕业设计,使我有机会对本专业的基本理论、专业知识和基本技术有了更深入的了解和体会,使我在四年中所学到的知识得到了系统的复习和升华,真正达到了学以致用。
管理信息系统是一门融管理科学、信息科学、系统科学、计算机科学与现代通信技术为一体的一门综合性学科。它是运用系统的方法以计算机和现代通信技术为基本信息处理手段和工具的,能为管理决策提供信息服务的人—机系统.它可以实现数据处理功能、预测功能、计划功能、控制功能和辅助决策功能。管理信息系统的开发是一项复杂的系统工程,必须严格的按照系统规划、系统分析、系统设计、系统实施、系统运行与评价的开发步骤来进行。
在系统开发之前,必须了解该系统的特点、适用范围以及使用者需要一个什么样的系统,以此作为基础为开发系统准确定位,然后对使用者所需实现的功能进行分析总结,根据使用者的实际要求来给系统设计一个初步方案。系统的开发不仅是要实现对数据处理的及时与正确,而且要考虑系统是否具有控制功能,及时将数据反馈给操作者,以进行监测和协调,保证系统的正常运行;也要考虑是否具有预测功能,运用一定的数学方法利用历史的数据对未来进行预测的工作。
在设计的过程中,我掌握了很多JSP的编程知识,并对这种成熟并广泛应用的技术进行了深入的学习。设计的过程也是一个再学习的过程,在遇到问题的时候我尽量自己想办法解决,这在很大程度上激发了我们的自学能力;在没有办法解决的情况下,认真的向老师请教,从老师那里我学到了很多的知识,老师对我的指导起到了画龙点睛的作用。
以往我们曾经有过多次设计的体会,但只是设计一个模块或一个小系统,而这一次毕业设计是综合所学的管理和计算机的知识来设计一个适合运行管理的企业采购信息管理系统。要想设计使用户满意,就需要我们付出更多的努力。我在设计中经常出现一些问题不知该如何解决,在此时许多同学给予了我帮助。在设计的过程中增加了于实际接触的机会,不仅培养了我的自学和编程能力,让我在即将离开学校进入社会之前有了一定的资本,提高了我与人沟通的能力。
在我的程序设计过程中,我充分的体会到了“实践出真知”这一点,书本上的知识是不够的,只有把理论与实践相结合才能够真正的学到知识。一个管理信息系统的设计,不可能一步到位,还需要不断的完善和补充。同时,系统中还存在许多问题,有待在日后的使用中发现和解决。编程前的深思熟虑是减少程序调试工作量的重要方法,只有进行充分考虑,才会减少调试过程中的工作量。虽然在开始写程序之前我们做了多的准备工作,但在真正的写程序时仍然发现许多问题,有些问题是分析时的疏漏,有些则是如果不做无论如何也想不到的。所以我需要在日后进行更多的经验积累。
毕业设计是我人生一笔宝贵的财富。我会把它当做人生的成功基石,日后不断的进行努力,提高自己,逐步走向成功。
参考文献
[1]孙卫琴,李洪成.《Tomcat 与 Java Web 开发技术详解》.电子工业出版社,2010年6月:1-205
[2]BruceEckel.《Java编程思想》. 机械工业出版社,2003年10月:1-378
[3]FLANAGAN.《Java技术手册》. 中国电力出版社,2012年6月:1-465
[4]杜轩华 袁方 《Web开发技术》.上海大学出版社, 2005年7月:1-300
[5]LEE ANNE PHILLIPS.《巧学活用HTML4》.电子工业出版社,2004年8月:1-319
[6]《数据库系统原理》. 光明日报出版社,2010年:30-475
[7]萨师煊,王珊.《数据库系统概论》.高等教育出版社,2008年2月:3-460
[8]Brown等.《JSP编程指南(第二版)》. 电子工业出版社,2013年3月:1-268
[9]清宏计算机工作室.《JSP编程技巧》. 机械工业出版社,2009年5月:1-410
[10]赛奎春.《JSP工程应用与项目实践》. 机械工业出版社,2012年8月:23-294
[11]冯博琴等 《面向对象分析与设计》.机械工业出版社,2005年8月:40-100
[12]张海藩 《软件工程导论》.清华大学出版社,2009年9月:45-90
致 谢
在本次毕业设计过程中,得到了指导老师的指导与支持。在此特别感谢指导老师的大力帮助。指导老师的悉心指导和大力支持,在总体结构、功能的把握上给予了非常大的帮助,同时提供了非常优越的设计环境,并对我在编程、数据库设计等细节工作上给予了耐心的指导,对于我顺利完成这次毕业设计起到了关键性的作用。
此次毕业设计对提高我的编程技术、沟通能力等方面都有许多益处。在此我一并向他们表示感谢。我还要感谢我的母校,以及在大学四年生活中给予我关心和帮助的老师和同学,是他们教会了我专业的知识和做人的道理。通过这次毕业设计我还明白了作为一名计算机专业的大学生,我不仅仅是编写代码,更重要的是要有整体把握系统设计的能力。我会在以后的工作和学习中不断完善自己,为我最热爱的母校争光,为自己翻开辉煌的新篇章。
转眼间,大学生活即将结束,回首过去四年的大学生活,真是有苦也有乐,然而更多的则是收获,感谢母校的各位老师不但无私地传授给我们知识,也教会了我们如何做人。采购管理信息系统的毕业设计任务繁重,但正是在这几个月紧张而充实的设计中,我感到自己的知识得到了一次升华,我相信:我的毕业设计会给我的四年大学画上一个圆满的句号。
21世纪已经到来了,在新的世纪里,人们自然对未来有许多美好的愿望和设想。现代科学技术的飞速发展,改变了世界,也改变了世界的生活。作为新世纪的大学生,应当站在世界的发展前列,掌握现代科学技术知识,调整自己的知识结构和能力结构,以适应社会发展的要求。新世纪需要具有丰富现代科学知识、能够独立解决面临任务、有创新意识的新型人才。
外文原文
Java Server Programming: Principles and Technologies
By Subrahmanyam Allamaraju , Ph.D.
1.Summary
Building and managing server-side enterprise applications has always been a challenge. Over the last two decades, the role and importance of server-side applications has increased. The twenty-first century economy dictates that ecommerce and other enterprise applications
are transparent, networked, adaptable, and service-oriented. These demands have significantl-y altered the nature of applications. As enterprises migrate from closed and isolated applications to more transparent, networked, and service-oriented applications to enable electronic business transactions, server-side technologies occupy a more prominent place. Despite the disparity of applications that exist in any enterprise, server-side applications are what power twenty-first century enterprises!
The purpose of this article is two-fold. Firstly, this article attempts to highlight the tecnical needs for server-side applications, and thereby establish a set of programming models. Sc-ondly, based on these programming models, this article introduces the reader to the Java 2, E-nterprise Edition (J2EE).
If you are a beginner to server-side programming, or the J2EE, this article will help you gain an overall perspective of what this technology is about. If you are familiar with one or more J2EE technologies, this article will provide the basic principles behind server-side programming, and help you relate these principles to specific J2EE technologies.
Introduction
Building and managing server-side enterprise applications1 has always been a challenge. Over the last two decades, the role and importance of server-side applications has increased. The twenty-first century economy dictates that ecommerce and other enterprise applications are transparent, networked, adaptable, and service oriented. These demands have significant-ly altered the nature of applications. As enterprises migrate from closed and isolated applications to more transparent, networked, and service-oriented applications to enable electronic business transactions, server-side technologies become more prominent. Despite the disparity of applications that exist in any enterprise, server-side applications are the ones that power twenty-first century enterprises.
The history of server-side applications dates back to the mainframe era, an era during which only mainframes roared across enterprises. They were centralized in nature, with all the computing—from user interfaces, to complex business process execution, to transactions—performed centrally. The subsequent introduction of minis, desktops, and relational databases fueled a variety of client-server style applications. This contributed to a shift in the way applications could be built, leading to various architectural styles, such as two-, three-, and multi-tier architectures. Of all the styles, database-centric client-server architecture was one of the most widely adapted. Other forms of client-server applications include applications developed using remoteprocedure calls (RPC), distributed component technologies, such as Common Object .
Request Broker Architecture (CORBA), and Distributed Component Object Model (DCOM), etc. Just as these technologies and architectures were diverse, so too were the nature of clients for such applications. The most commonly used client types for these applications were desktop based (i.e., those developed using Visual Basic or other similar languages). Other types of clients included other applications (viz., as in enterprise application integration) and even Web servers.
Subsequently, what we see today are Internet-enabled server-side applications. The underlying technologies for building Internet-enabled server-side applications have evolved significantly and are more mature and less complex to deal with, as you will see later in this article. Apart from providing more flexible programming models, today’s server-side technologies are infrastructure intensive.
2.What is server-side programming?
The terms server and server-side programming are very commonly used. But what is a
server? Generally speaking, a server is an application hosted on a machine that provides some services to the other applications (clients) requesting the services. As is obvious from the definition, a server typically caters to several clients, often concurrently. The services offered by a server application can be very diverse— ranging from data, and other information, management to the execution of specialized business logic. Although several types of server applications are possible, you can quickly recognize the following two kinds of servers:
1. Commercial Database Servers (or Database Management Systems): Servers that manage data, which come from vendors, such as Oracle, Sybase, and Microsoft. Client applications use standard APIs, such as Open Data Base Connectivity (ODBC) or Java Data Base Connectivity (JDBC), in combination with SQL (Structured Query Language) to access/manipulate the data. In addition to these standard APIs, you may use vendor-specific client access APIs to communicate with the database server. These servers are responsible for consistently managing data such that multiple clients can manipulate the data without loss of consistency.
2. Web Servers: The other easily recognizable types of servers are Web servers. A Web server hosts content, such as HTML files. Clients (Web browsers) access this content by submitting requests using Hyper Text Transfer Protocol (HTTP). In its basic mode, a Web server maps a client request to a file in the file system, and then sends the content of the file to the client making the request. Similar to database servers, Web servers can deal with concurrent requests—often several thousands. Because we are accustomed to working with these types of servers, we often tend to overlook the fact that they are server-side applications, albeit standardized. However, when I use the term server-side programming, I do not mean developing such databases or Web servers. Such applications were commodified years ago. These general-purpose server-side applications provide standard, predefined functionality. In the case of server-side programming, we are more interested in developing specialpurpose applications to implement specific business-use cases.Why is it important or relevant to consider server-side applications? Why is it necessary to build applications that can provide services to several client applications? Following are some common scenarios that illustrate the need for server-side applications:
1. Execute some logic available with a different application.
This is one of the reasons that prompted development of early distributed technologies, such as the RPC.17 Consider that you are developing an application implementing certain new business-use cases. Suppose that there is some business logic already implemented in a different application. In cases where such functionality is available as separate/isolated class or function libraries, you might consider reusing the same code in the new application. But, what if such logic (and code) depends heavily on some data being managed by the existing application? In such a case, the class/function library cannot be reused as these class/function libraries may fail to execute without the availability of such data. Alternatively, what if such code is dependent on several other parts of the existing application, making it difficult to reuse the code in the new application? One possible solution to deal with this is by executing this logic in the existing application; that is, instead of reusing the code from the existing application, the new application can send a request (with any required data) to the existing application to execute this logic and obtain any results
2. Access information/data maintained by another application. This is yet another scenario that mandates server-side applications and clients. Database servers and other applications maintain information in a persistent storage fall under this category; however, database servers, such as relational database management systems, typically manage raw data (rows of data in various tables). Such data may or may not be directly usable (in the business sense) by other applications that rely on the data. For instance, consider a database holding various accounts of all customers in a bank. A common requirement in such systems is to consolidate all the accounts of a given customer and present a summarized view of all accounts. Depending on that customer’s account types, the process of generating the summarized view may involve performing some complex calculations including evaluating some business rules.
Now consider several applications within the bank performing other banking tasks some of which require a summarized view of all accounts of a customer. For instance, an application responsible for calculating monthly account charges may require the value of the consolidated account balance. When there are several such applications that require this data, it is appropriate to let one of the applications handle this calculation for all other applications.
3. Integrate applications. In any given enterprise, it is not uncommon to find several applications developed over years that are used for executing different business tasks. You may even find that such stand-alone applications are maintained by different departments of enterprises and developed using different programming languages and technologies. To some extent, such applications were a result of the drive to decentralize businesses from mainframe-based applications. However, as we discussed earlier, one of the requirements encountered by almost all enterprises today is the ability to internetwork such applications so that business workflows can be established across the enterprise.
To elaborate further, let us take the case of a traditional retail business collecting orders for products via a call center, surface mail, etc. Let us assume that an order-entry application is used to record all orders (in a database) captured via these channels. Let us also assume that the company has developed an in-house order-fulfillment application, which takes the orders recorded in the database and conducts whatever tasks are need to fulfill each order. These two applications are stovepiped because each of these applications addresses specific business tasks in a decoupled manner without any knowledge of the overall business flow. In this case, the overall business flow is to receive (and enter) orders, and then to fulfill each of the orders. Such stovepiped applications cannot, individually, implement the end-to-end business flow. In order to implement this, you need to integrate the applications such that the order-entry application can automatically trigger the fulfillment application, directly or indirectly. This is the enterprise application integration18 problem, but there are several ways to achieve such integration. One way is to make the order-entry application invoke (or notify) the fulfillment application directly after an order has been captured. The fulfillment application can then start the fulfillment activities thereby streamlining a business flow across these applications.
2.Synchronous Request-Response Model
The fundamental idea behind this model is that it allows client applications to invoke methods/functions executing on remote applications. Technologies, such as CORBA, Java Remote Method Invocation (RMI), and Enterprise JavaBeans (EJB) follow this model. The following features characterize the synchronous request-response model approach:
1. The contract between clients and servers is interface based. The interface between client and server is the remote interface. It specifies the operations/methods that clients can invoke on servers.
2. The communication between the client and the server is synchronous. This is no different from local method calls. Upon invoking a method, the client thread waits until the server responds. This also implies that the server should be up and running for the client to invoke methods on the server.
3. The communication is connectionful. The application contract can maintain various requests and responses between the client and the server.
These two features narrow the line between invoking a method on a local object and invoking a method on a remote object.
3.Basic Requirements
What are the technical requirements for implementing such an approach? Before we can identify the technical requirements, let us study this approach in more detail. The following Figure 4 shows as application (client) invoking a method in a different process. In object-oriented languages, such as Java, methods exist on interfaces or classes. Therefore, in a Java environment, this approach involves a client invoking a method on an object that exists in a different process (possibly on a different machine).
4.Java RMI
Let us now illustrate how to develop client and server objects, and generate proxy and skeleton classes with Java RMI.
Java RMI is the CORBA alternative in a pure Java environment. Java RMI defines a framework for specifying remote interfaces, which is specified in the java.rmi package. The J2SE also includes the runtime support for remote objects and clientserver communication.
You can specify remote interfaces by making your interface extend the java.rmi.Remote interface (this indicates the Java runtime that it is a remote interface) as follows:
public interface Process extends java.rmi.Remote {
public void process(String arg) throws java.rmi.RemoteExcetion; }
This code snippet defines a remote interface with one method. The exception clause is required to denote that this method can throw communication-related exceptions.
The next step is to implement a class that implements the remote interface. This is the server object.
public class ProcessImpl extends UnicastRemoteServer implements Process {
public ProcessImpl() { super(); }
public void process(String arg) throws java.rmi.RemoteExcetion {
// Implement the method here } }
Once you have the remote interface, the next step is to use the rmic compiler on the implementation class to generate the proxy and skeleton classes. You will find this compiler under the J2SE distribution. This compiler has options to create source filesfor the proxy and skeleton classes.Other technologies, such as CORBA or EJB, use similar approaches to specify remote interfaces and generate proxies and skeleton.
Although proxies and skeletons eliminate the need for network-level programming, the following two questions should be considered:
1. How does the skeleton maintain instances of object B? Should the server application create an instance initially, for each request, or should it share one instance for all requests? What are the threading/concurrency implications of any strategy?
2. Location transparency: How do you indicate the location of the server to the proxy object? Can you predetermine this and force the proxy to invoke a specific implementation of the remote interface available at a given network location? If so, the client application would be dependent on the location of the server. But, is it possible to achieve location transparency? 5.Instance Management
Once the remote interface, and its implementation are available, the next question is how to make instances of the implementation class available in a runtime (process). Creating a new instance of an implementation object is not adequate to make this implementation available via a remote interface. In order for the server implementation object to be available and be able to process requests coming from client applications over the network, the following additional steps are required:
1. The process hosting the instance should be reachable via network. Typically, this boils down to a server socket listening for requests over the network (i.e., the server process should have the necessary infrastructure to do so).
2. The server process should allocate a thread for processing each incoming request. Servers are generally required to be multi-threaded.
3. The server process may host implementations of several remote interfaces. Depending on some of the information contained in the incoming network request, the server process should be capable of identifying the correct implementation object. For instance, the name of the interface could specify the implementation object for the server. In this case, the server should have knowledge of which class implements which remote interface.
4. Once the server identifies the correct interface, it should invoke the associated skeleton class. This class can unmarshall the request parameters and invoke the appropriate method for the implementation class.
In the above list, the task of creating instances depends on whether the clientserver communication is required to be stateful or stateless. Address this question when you expect more than one client to invoke methods on a remote object. The main difference between stateful and stateless communication is whether the remote instance can maintain and rely on instance variable between multiple method calls from a client. For instance, consider that client A is invoking methods on a remote object B. Let’s also assume that the remote interface has several methods. The client may invoke these methods one after the other. While implementing a method, the remote object may store data in its instance variables. For instance, it may store some calculation results in an instance variable. If subsequent methods on this object depend on the value stored in the instance variable, the communication is stateful; that is, the server should make sure that the same instance is being used for all requests from a given client. This also means that, while an instance is serving a client, the server should not use the same instance for other client requests. One important ramification of statefulness is that the server will maintain a separate instance for each client. In systems that have a very large number of clients, statefulness may affect performance.
On the other hand, stateless communication does not require the same instance for a given client (i.e., invoking methods). In this case, the server may be able to use ten objects for these ten clients. As a result, stateless communication is more efficient as it converses memory on the server side.
A general practice is to implement remote objects using the stateless approach. Technologies, such as RMI, CORBA, and COM/DCOM provide for stateless remote objects alone. On the other hand, the EJB technology allows for stateful server-side objects, too. We shall discuss more about this later. Figure 10 summarizes the instance management.
中文翻译
Java服务器程序设计:原理和技术
作者:Subrahmanyam Allamaraju
版权所有©2001年Subrahmanyam Allamaraju 保留所有权利
出版MightyWords公司 2550
95051 书号0-7173-0642-9
1.综述
建立和管理服务器端企业应用一直是挑战。在过去的二十年中,作用和服务器端的重要性应用有所增加。二十一世纪的经济决定了电子商务和其他企业应用是透明的,网络化,适应性强,服务至上。这些要求已大大改变了应用程序的性质。随着企业的迁移从封闭和孤立的应用程序更加透明,网络化,面向服务的应用,使电子业务交易,服务器端技术占据更加突出的位置。尽管在任何的应用程序的企业存在差距,服务器端应用程序是什么 电力二十一世纪的企业!
本文的目的有两个方面。首先,本文试图以突出服务器端应用的技术需求,从而建立一套编程模型。其次,根据这些编程模型,本文介绍了到Java 2企业版(J2EE)的读者。如果你是一个服务器端编程初学者,或J2EE,本文将帮助你获得一个什么样这项技术是对整体的观点。如果你是 与一个或多个J2EE技术的熟悉,本文将提供基本的后面的服务器端编程的原则,并帮助您联系这些原则特定的J2EE技术。
2.简介
建立和管理服务器端企业应用一直是 挑战。在过去的二十年中,作用和服务器端的重要性应用有所增加。二十一世纪的经济决定了电子商务和其他企业应用是透明的,网络化,适应性强,服务为本。这些要求已大大改变了应用程序的性质。随着企业的迁移从封闭和孤立的应用程序更加透明,网络化,面向服务的应用,使电子业务 交易,服务器端技术变得更加突出。尽管差距在任何的应用程序的企业的生存,服务器端应用程序是那些电力二十一世纪的企业。对于服务器端应用程序的历史可以追溯到大型机时代,一个时代 在此期间只大型机吼道跨企业。他们被集中在自然,所有的计算,从用户界面,到复杂的业务流程执行中,把交易,集中执行。此后推出的迷你合约,台式机,和关系数据库这一事件引起了客户的各种应用服务器风格。这有助于建立一个可以应用的方式转变,导致各建筑风格,如两,三年,多层次架构。在所有的样式,数据库为中心的客户机服务器体系结构是最广泛适应之一。其他客户机服务器应用形式包括:应用开发使用remoteprocedure 调用(RPC),分布式组件技术,如通用对象,请求代理架构(CORBA)和分布式组件对象模型 (DCOM)的,等等,正如这些技术和体系结构是多种多样的,因此也被为这类客户申请的性质。最常用的客户类型 这些应用程序是基于桌面(即那些使用Visual Basic或开发其他类似的语言)。其他类型的客户包括其他应用程序(即,如企业应用集成),甚至Web服务器。 随后,我们今天看到的是互联网功能的服务器端的应用。该建设互联网基础技术功能的服务器端应用程序进化显着,而且更成熟,不太复杂的处理,你会后面看到这篇文章。除了提供更灵活的编程模型,当今的服务器端技术是基础设施密集。
3.什么是服务器端的编程?
术语服务器和服务器端编程是非常普遍的。但什么是服务器?一般来说,服务器是一个应用程序的机器上托管 提供一些服务,(客户)要求的其他应用程序的服务。正如明显的自定义,服务器通常迎合了几个客户,往往同时进行。由服务器应用程序提供的服务可以是非常多样, 从数据和其他信息,管理到专门的执行业务逻辑。尽管服务器应用程序可能有几种类型,你可以快速识别的服务器以下两种:
1.商业数据库服务器(或数据库管理系统):服务器管理数据,如Oracle,SYBASE的是从厂商要来, 微软。客户端应用,如开放数据库标准的API,连接(ODBC)或Java数据库连接(JDBC),结合与SQL(结构化查询语言)来访问/操纵的数据。此外这些标准的API,你可以使用供应商特定的客户端访问API与数据库服务器通信。这些服务器负责坚持管理数据,使得多个客户端可以操作数据没有一致性的损失。
2.Web服务器:其他容易辨认类型的服务器是Web服务器。Web服务器主机的内容,如HTML文件。客户端(Web浏览器)访问本内容提交请求使用超文本传输协议(HTTP)。在其基本模式下,Web服务器映射一个客户端请求中的一个文件系统的文件,然后发送到客户端的请求文件的内容作出。类似数据库服务器,Web服务器可以处理并发请求,往往数千名。因为我们习惯使用这些类型的服务器的工作,我们常常忽视了这个事实,他们虽然标准化的服务器端应用程序。然而,当我使用这个词的服务器端编程,我不是指发展这样的数据库或Web服务器。这样的应用程序进行商品化年前。这些通用服务器端应用提供标准的,预定义的功能。在对服务器端编程的情况下,我们更感兴趣的specialpurpose发展应用程序实现具体的业务用例。
为什么是很重要的或相关的考虑服务器端的应用程序?为什么要构建应用程序,可以提供服务的几个客户端应用程序?下面是一些说明服务器端需要共同方案应用:
1.执行一些逻辑,用不同的申请。这是一原因促使分布式技术发展的早期,如RPC.17想想看,你正在开发一些新的应用程序实施业务用例。假定有一些业务逻辑已经实施在不同的应用程序。在这种情况下,可作为功能单独的/隔离类或函数库,你可以考虑重用相同在新的应用程序代码。但是,如果这种逻辑(和代码)在很大程度上取决于一些数据被管理的现有的应用程序?在这种情况下,类/函数库不能被重用,因为这些类/函数库,可能无法执行没有这些数据的可用性。另外,如果这样的代码依赖于现有的应用程序若干其它地区,因此很难重用在新的应用程序代码?一种可能的解决办法来处理,这是由在现有执行此应用程序逻辑,这就是,而不是重用代码从现有的应用程序,新的应用程序可以发送一个请求(与任何 所需的数据),以现有的应用程序来执行这个逻辑,并取得任何的结果。
2.获取信息的另一个应用程序维护/数据。这又是一个场景,任务服务器端应用程序和客户端。数据库服务器和其他应用程序保持在一本属于持久存储信息范畴;但是,数据库服务器,如关系数据库管理系统,通常管理的原始数据(数据行各表)。这些数据可能会或可能不会直接使用(在商业意义上)的其他应用程序依靠这些数据。例如,考虑一个数据库持有的所有各个账户客户在一家银行。在这种系统的共同要求,是巩固所有给定客户的帐户并提交所有帐户总结的看法。根据该客户的帐户类型,产生过程总结观点可能涉及一些复杂的计算,包括表演 评估一些业务规则。现在考虑在其他银行的银行执行多个应用程序其中一些任务需要概括了客户所有账户的看法。对于例如,一个应用程序负责计算每月账户费可需要综合帐目收支平衡的价值。当有几个这样的应用程序需要此数据,它是适当的,让其中一个应用程序处理这对所有其他应用程序的计算。
3.整合应用。在任何特定的企业,是不难发现几个经过多年开发的应用程序可用于执行不同的业务使用任务。你甚至可能发现这种独立的应用程序维护 企业不同部门和不同的编程开发利用语言和技术。从某种程度上说,这种应用是一种结果的开车从分散基于大型机的应用程序的需求。然而,由于我们前面讨论的要求之一,几乎所有的企业所遇到的今天是互联网络的能力,这样的应用,使业务工作流程可以建立整个企业。为了进一步说明,让我们以传统的零售商业案例 收集通过呼叫中心,平邮等产品的订单,让我们假设 ,一个订单输入应用程序是用来记录所有的订单(在一个数据库)抓获通过这些渠道。我们还假设该公司已经开发了一个内部为了实现的应用程序,它发生在数据库中记录的命令,进行任何任务需要完成每一张订单。这两个应用程序stovepiped因为这些应用程序的每个地址的特定业务任务一个没有任何业务流程的整体知识脱钩的方式。在这情况下,整体业务流程接收(和输入)命令,然后履行每个订单。这种stovepiped应用程序无法单独地,实施最终的端到端业务流程。为了实现这一点,你需要整合应用,例如,订单输入应用程序可以自动触发实现应用程序,直接或间接的影响。这是企业应用integration18问题,但有几种方法来实现这种一体化。一方法是使订单输入应用程序调用(或通知)的实现申请后,直接的命令已抓获。实现应用程序的然后可以启动一个业务流程,从而简化整个履约活动这些应用程序。
4.同步请求响应模型
这种模式背后的基本思想是,它允许客户端应用程序调用方法/功能上执行远程应用程序。技术,如CORBA,Java远程方法调用(RMI)和企业JavaBeans(EJB)的跟进这模型。
以下功能特点的同步请求响应模型方法:
1.客户端和服务器之间的合同是基于接口。该接口客户端和服务器之间的远程接口。它指定操作/方法,客户端可以调用服务器上。
2.之间的客户端和服务器之间的通信是同步的。这是没有本地方法调用不同的。当调用一个方法,客户端线程等待,直到服务器响应。这也意味着该服务器应和 运行客户端来调用服务器方法。
3.通信是connectionful。应用程序可以维护合同各种请求和响应之间的客户端和服务器。这两个特点拉近方法调用本地对象的行和调用远程对象的方法。 基本要求什么是实施这种做法的技术要求?在我们可以识别的技术要求,让我们更详细地研究这种方法。该下面的图4显示了作为应用程序(客户端)调用在一个不同的方法过程。在面向对象的语言,如Java,接口或方法存在类。因此,在Java环境中,这种方法涉及到一个客户端调用对一个对象,在不同的过程中存在的方法(可能在不同的机器上)。
5.Java RMI
现在让我们说明如何开发客户端和服务器对象,并生成代理和与Java的RMI骨架类。
Java RMI的是一个纯Java环境CORBA的选择。 Java RMI的定义用于指定远程接口框架,它是在特定的java.rmi包。 J2SE的还包括用于远程对象和运行时支持clientserver沟通。您可以指定让您的远程接口扩展接口java.rmi.Remote接口(这表明了Java运行时,它是一个远程接口)如下:
public interface Process extends java.rmi.Remote {
public void process(String arg) throws java.rmi.RemoteExcetion; }
此代码片段定义了一个方法的远程接口。唯一的例外子句是必需来表示,这种方法可以抛出通信相关例外。接下来的一步是实现一个类,实现了远程接口。这是服务器对象。
public class ProcessImpl extends UnicastRemoteServer implements Process {
public ProcessImpl() { super(); }
public void process(String arg) throws java.rmi.RemoteExcetion {
// Implement the method here } }
一旦你的远程接口,下一步是使用rmic编译器上实现类生成代理和skeleton类。你会发现这编译器下的J2SE分布。此编译器选项来创建源文件为代理和骨架类。其他技术如CORBA或EJB,使用类似的方法来指定和远程接口生成代理和骨架。虽然代理和骨骼消除了网络层次的需要编程,以下两个问题应予以考虑:
1.如何保持骨骼对象B的实例?如果服务器应用程序创建一个实例开始,对于每个请求,还是应该共享一个例如对所有的要求?什么是线程的任何/并发影响策略?
2.位置透明:你如何显示服务器的位置的 代理对象?你能预先确定这一点,迫使代理来调用特定实施远程接口可在一个给定的网络位置?如果因此,客户端应用程序将在服务器的位置而定。但是,是有可能实现了位置透明性?
6.实例管理
一旦远程接口,其实现的情况下,接下来的问题是如何让实现类在运行时(进程)可用实例。创建一个执行对象的新实例不足以使这个通过实施远程接口。在服务器的命令实施对象可用,并且能够处理请求来自网络客户端应用程序,下面的附加步骤是必需的:
1.申办的过程实例应该可以通过网络访问。通常情况下,这可以归结为一个服务器套接字通过网络(即监听请求的服务器进程应该有必要的基础设施,这样做)。
2.服务器进程应分配一个线程来处理每请求。服务器通常需要是多线程的。
3.服务器进程可承办多个远程接口的实现。对一些信息的不同包含在传入的网络请求,服务器进程应该是能够识别的正确实施对象。例如,该接口的名称可以指定执行对象服务器。在这种情况下,服务器应该有知识,即类实现该远程接口。
4.一旦服务器识别正确的接口,它应该调用相关骨架类。这个类可以和解组请求参数,并调用适当的方法的实现类。在上面的列表,创建实例的任务,取决于是否clientserver通讯须有状态或无状态的。解决这一问题当你希望多个客户端来调用远程对象的方法。有状态和无状态之间沟通的主要区别在于是否 远程实例可以维持,靠的实例变量之间的多个方法从客户端调用。例如,考虑一个是客户端上调用一个方法远程对象B让我们也假设远程接口有几种方法。该客户端可以调用这些后,其他的方法之一。在实施方法,远程对象可以存储在它的实例变量的数据。例如,它可以存储在一个实例变量的一些计算结果。如果这个对象后续方法依赖于实例变量中存储的值,通讯状态,这,服务器应该确保相同的实例将被用于为所有请求从一个给定的客户端。这也意味着,当一个实例正在服刑的客户端,服务器不应该使用其他客户端请求相同的实例。其中一个重要 有状态衍生物的是,服务器将保持每个单独的实例客户端。在系统的客户有非常大的数字,有状态可能会影响性能。另一方面,无国籍沟通并不需要同样的实例一个给定的客户端(即,调用方法)。在这种情况下,服务器可能能够使用十对象为这十个客户。因此,无国籍的沟通更为有效,因为它交谈在服务器端的内存。一个一般的做法是使用无状态的方法实现远程对象。技术如RMI,CORBA和COM / DCOM技术,提供远程无状态单独的对象。在另一方面,有状态的EJB技术使服务器端对象了。我们将讨论这个更详细说明。