若是博客,即非博客,是名博客
第一次写这么系统的博客,如果逻辑有需要调整的话,望大家不吝赐教
简介:
通过对 滴滴的tinyid(https://github.com/didi/tinyid.git)、
美团的Leaf(https://github.com/Meituan-Dianping/Leaf)、
百度的uid-genetator(https://github.com/baidu/uid-generator)的学习,自己做了一些总结和实践。
后面会分3篇文章来分析自己对这3个开源项目的理解和小小实践。
本篇主要是写下自己的使用建议。
实践:
一.我们的实践分为 号码段(1/3分享) 和 雪花算法(2/3分享) 两种类型:
1.对于号码段的实践使用的是滴滴tinyid项目基础上做了几个类的改造来实现的。
2.对于雪花算法参考了leaf和uid-genetator的代码通过本地生成的方式来实现的。
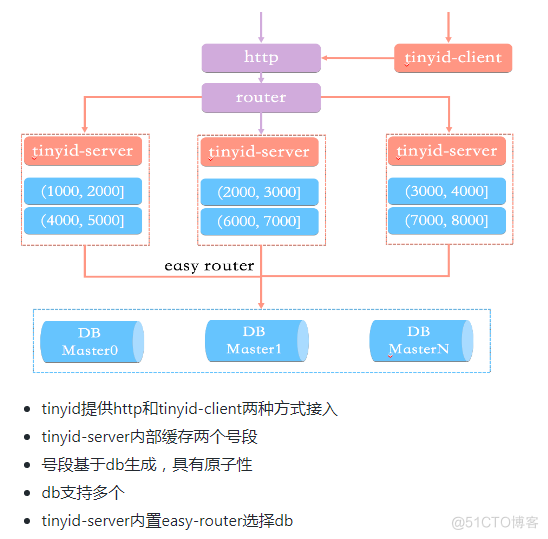
二.号码段:
这里直接clone的滴滴tinyid的代码使用,通过tinyid-client的方式来使用的。平时看文档即可,但是通过笔者自己的学习,发现其实 tinyid原理地址 才是真正的使用指南。
tinyid的文档地址:https://github.com/didi/tinyid/wiki
tinyid原理地址:https://github.com/didi/tinyid/wiki/tinyid原理介绍
这里说下需要注意的地方:
一.场景说明
适用场景:
1.只关心id是数字;
2.趋势递增的系统(因为分布式的多节点号码段不同的原因,所以不保证下一个id一定比上一个大,只能保证趋势递增);
3.可以容忍id不连续;
4.可容忍浪费的场景。
不适用场景:
类似订单id的业务(因为生成的id大部分是连续的,容易被扫库、或者测算出订单量),这里可以考虑使用雪花算法的方案。
二.特性
1.全局唯一的long型id
2.趋势递增的id,即不保证下一个id一定比上一个大
3.非连续性
4.提供http和java client方式接入(tinyid-client方式)
5.支持批量获取id
6.支持生成1,3,5,7,9...序列的id
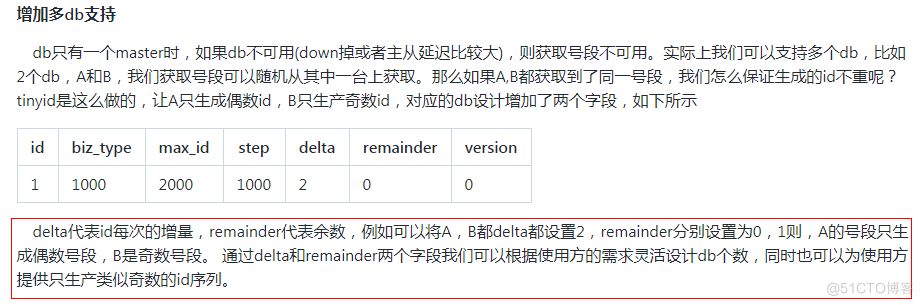
7.支持多个db的配置,无单点(这个方式比较特殊,下面会特别说明)
8.因为是号段生成,因此是有id缓存的,这里面一方面会对于db或者server掉线的时候,增加一段时间的可用性,另一方面也可以减少http访问的频次,但是缺点是如果部署频次较多会引起号段的浪费。
三.使用
因为非tinyid-client的方式是在tinyid-server的启动后,通过http方式访问号段接口获取id,其实和tinyid-client方式类似,因此这里只按tinyid-client方式讲解。
1.快速构建:
1.1.启动tinyid-server:
tinyid-server分为两个offline,online环境,分别对应tinyid\tinyid-server\src\main\resources\offline,tinyid\tinyid-server\src\main\resources\online的配置信息。
1.1.1.可以通过下面两种方式打包:
1.1.1.1tinyid\tinyid-server\build.sh方式打包:
build.sh offline/online(默认oline)1.1.1.2.mvn方式打包:
mvn clean package -Dmaven.test.skip=true(默认offline)1.1.2.创建数据库tinyid-server,导入tinyid\tinyid-server\db.sql
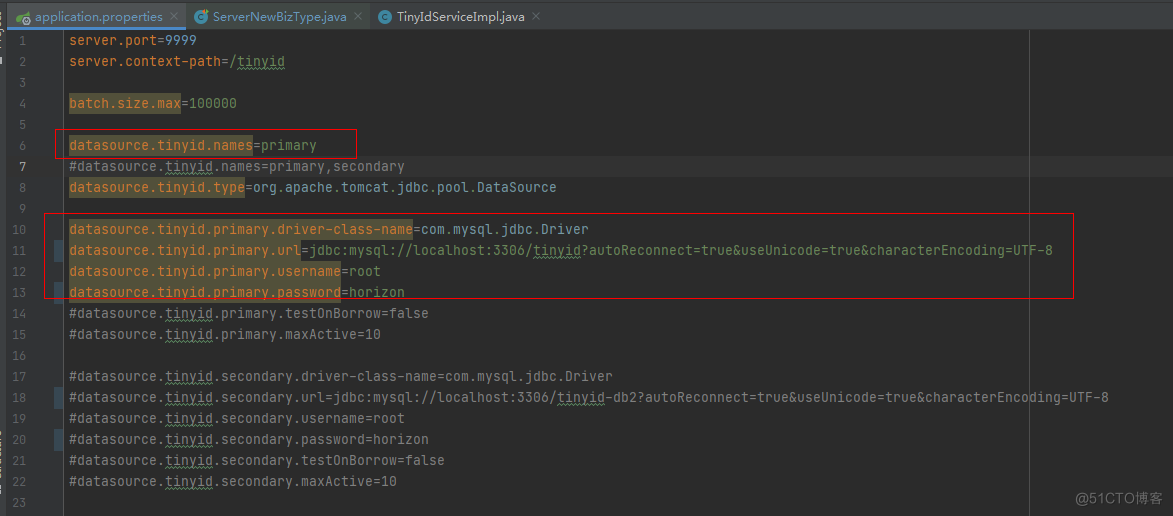
1.1.3.更改tinyid-server的offline或者online的application.properties配置
datasource.tinyid.names=primarydatasource.tinyid.primary.driver-class-name=com.mysql.jdbc.Driverdatasource.tinyid.primary.url=jdbc:mysql://ip:port/tinyid-?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8datasource.tinyid.primary.username=rootdatasource.tinyid.primary.password=horizon1.1.4.启动tinyid-server
测试rest请求:
nextId:curl 'http://localhost:9999/tinyid/id/nextId?bizType=test&token=0f673adf80504e2eaa552f5d791b644c'response:{"data":[2],"code":200,"message":""}nextId Simple:curl 'http://localhost:9999/tinyid/id/nextIdSimple?bizType=test&token=0f673adf80504e2eaa552f5d791b644c'response: 3with batchSize:curl 'http://localhost:9999/tinyid/id/nextIdSimple?bizType=test&token=0f673adf80504e2eaa552f5d791b644c&batchSize=10'response: 4,5,6,7,8,9,10,11,12,13Get nextId like 1,3,5,7,9...bizType=test_odd : delta is 2 and remainder is 1curl 'http://localhost:9999/tinyid/id/nextIdSimple?bizType=test_odd&batchSize=10&token=0f673adf80504e2eaa552f5d791b644c'response: 3,5,7,9,11,13,15,17,19,211.2.项目整合配置tinyid-client:
1.2.1.增加maven依赖
<dependency> <groupId>com.xiaoju.uemc.tinyid</groupId> <artifactId>tinyid-client</artifactId> <version>${tinyid.version}</version></dependency>1.2.2.增加tinyid_client.properties文件
tinyid.server=localhost:9999tinyid.token=0f673adf80504e2eaa552f5d791b644c注意:对于不通bizType的不同token的方式,可以通过调整 com.xiaoju.uemc.tinyid.client.factory.impl.IdGeneratorFactoryClient 的配置方式 和 配置文件 来实现,如下:
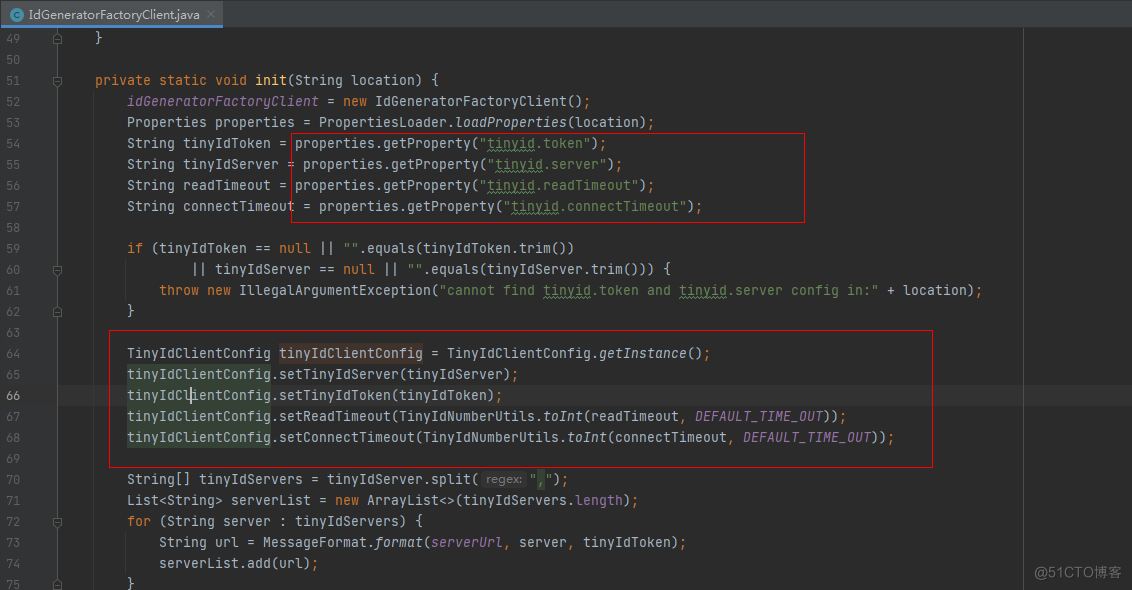
1.2.3.执行代码
// test为bizType,单独获取方式Long id = TinyId.nextId("test");// 批量id获取方式List<Long> ids = TinyId.nextId("test", 10);1.3.创建自定义的bizType
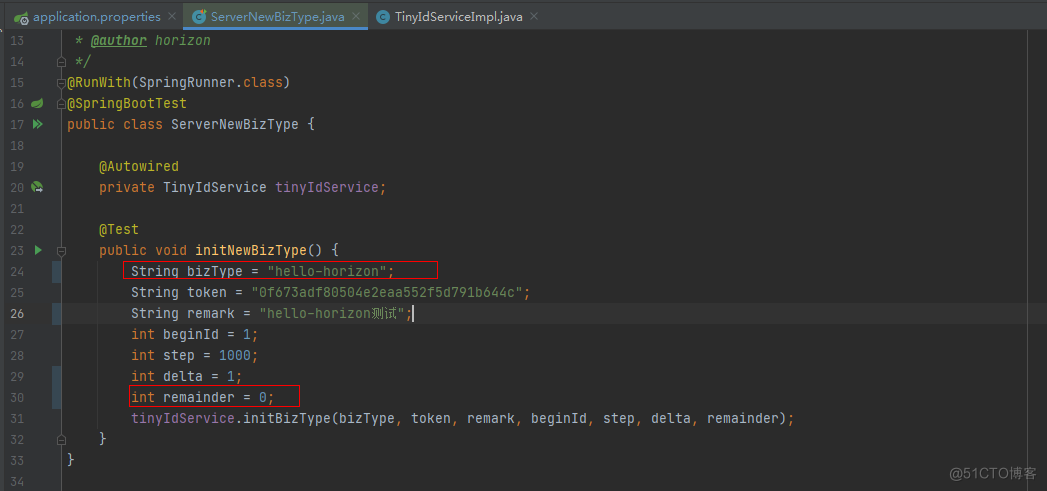
1.3.1.这里需要写入tiny_id_token,tiny_id_info
tiny_id_token:配置 bizType 和 token 访问权限;
tiny_id_info:增加 bizType 的 id 规则。
参数说明:
bizType:业务类型;
token:安全访问token;
beginId:号段开始id;
step:号段跨度,每次号段的生成跨度;
delta:id递增单位(对id取余的单位,为了对齐id的开始值);
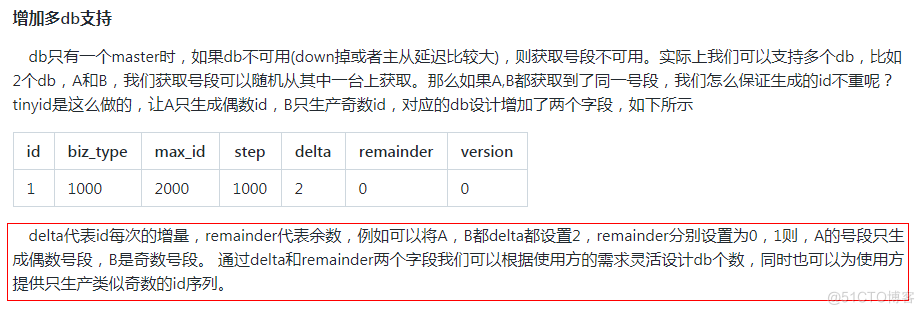
remainder: (这里主要为了对齐id的开始值,解决多数据源的功能)对于规律号码数组的每个数的递增余数, 比如delta为要生成奇数号段,是设置beginId为0,在delta为2的基础上,remainder设置为1,则数组为1,3,5,7,9的生成是在 0,2,4,6,8 的基础上加1
1.3.2.这里自己增加了一个初始化方法:
可以参考代码仓库:
https://gitee.com/horizon_546262445/cn-tinyid
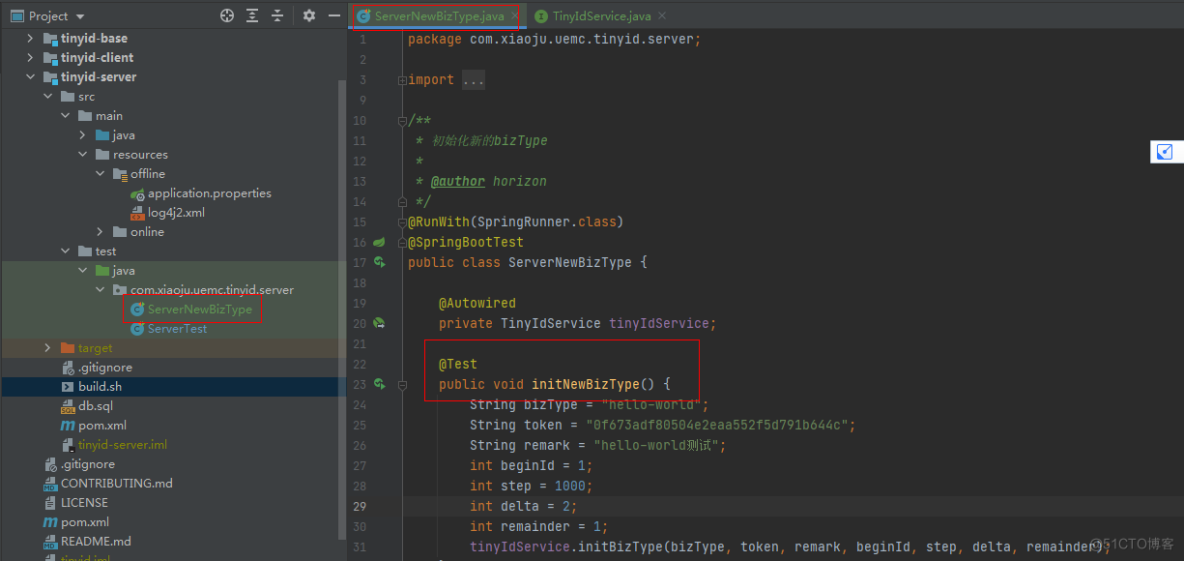
相关的代码类:
2.使用推荐:
2.1.tinyid-server只提供了简单的token验证,因此,该服务尽量保证在内网访问范围内;
2.2.tinyid-server推荐部署到多个机房的多台机器:
多机房部署可用性更高,http方式访问需使用方考虑延迟问题
2.3.推荐使用tinyid-client来获取id,好处如下:
id为本地生成(调用AtomicLong.addAndGet方法),性能大大增加;
client对server访问变的低频,减轻了server的压力,因为低频,即便client使用方和server不在一个机房,也无须担心延迟 ,即便所有server挂掉,因为client预加载了号段,依然可以继续使用一段时间
注:使用tinyid-client方式,如果client机器较多频繁重启,可能会浪费较多的id,这时可以考虑使用http方式。
2.4.推荐db配置两个或更多:
db配置多个时,只要有1个db存活,则服务可用 多db配置,如配置了两个db,则每次新增业务需在两个db中都写入相关数据,这个db配置多个。
注:这里的db个人感觉可以不用配置,因为配置的话,数据源是随机选择的,这样的话,出现的id不连续性会比较多,如果部署频繁的话,也会增加号段的浪费,但是对于可用性还是可以的,这里说下相关的配置以及可以自定义的方法。
2.4.1.初始化业务数据:
2.4.1.1.配置tinyid数据库
执行:
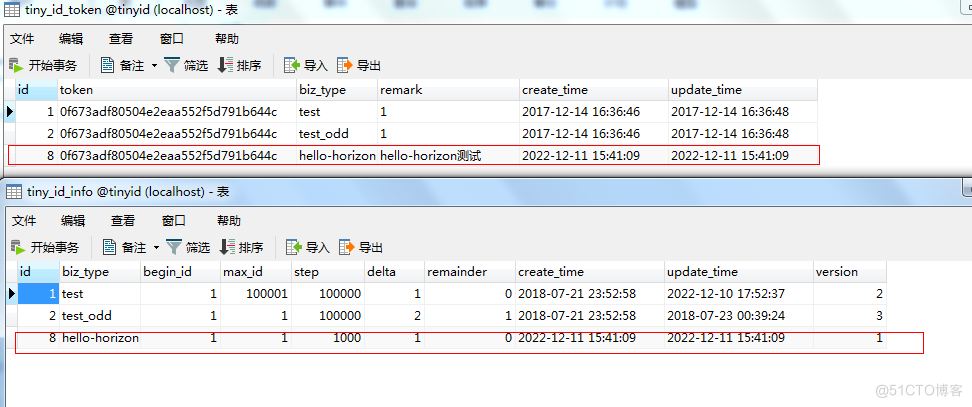
2.4.1.2.配置tinyid-db2数据库
执行:
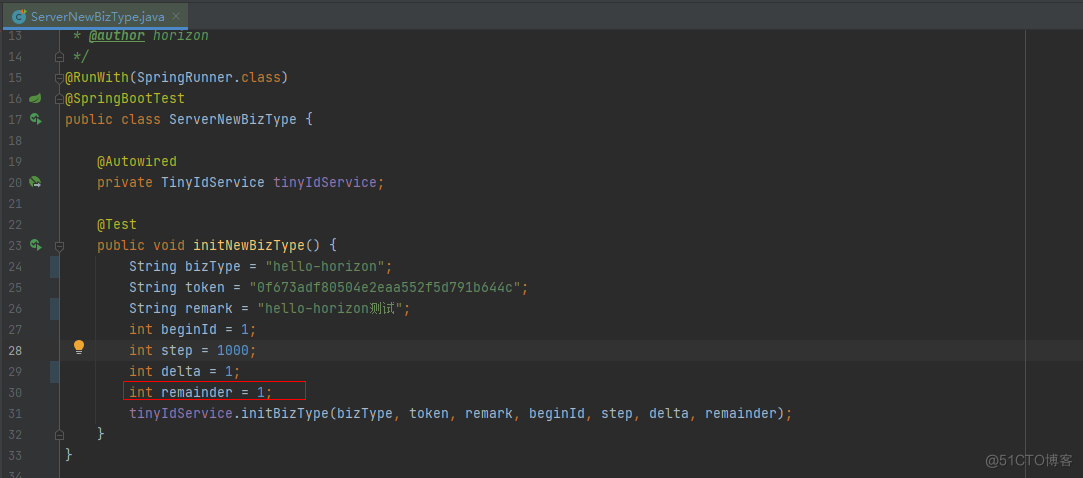
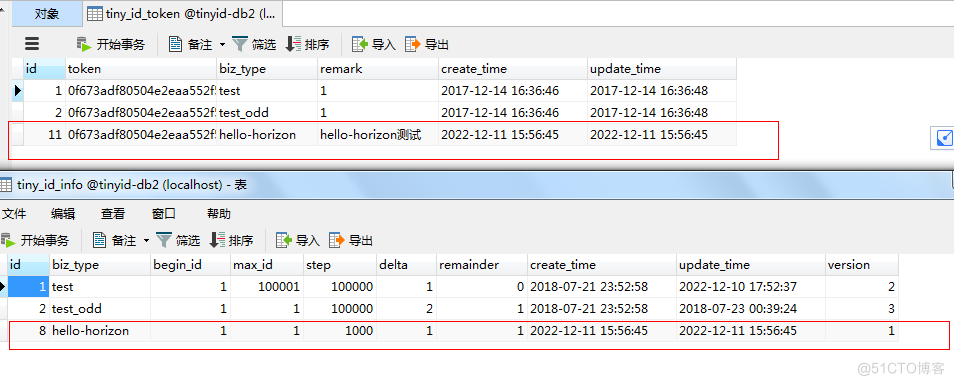
note:这里2.4.1.1到2.4.1.2是初始化多数据源bizType的方法,如果有新的bizType创建的话,就按这个方法创建即可,当然,自己insert语句也可以的。
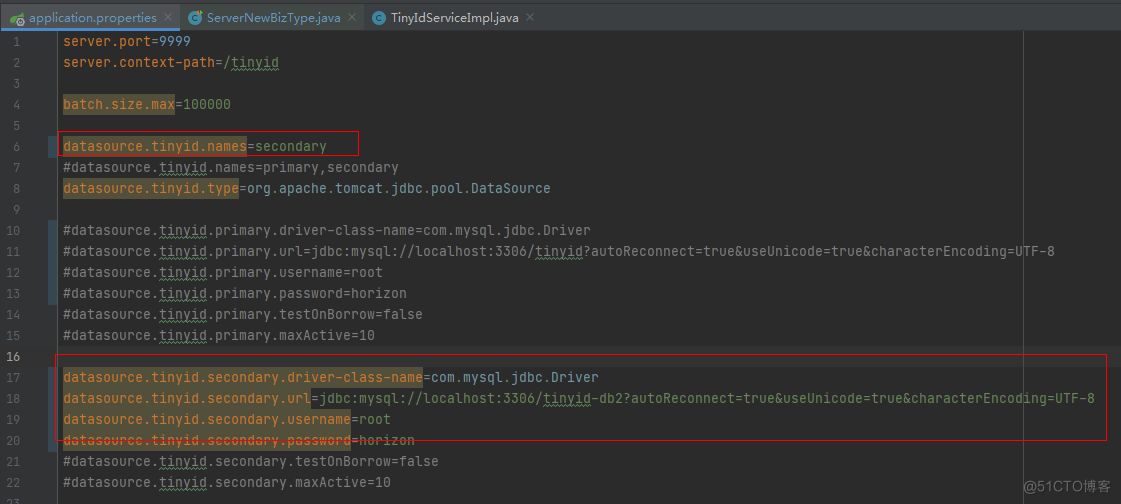
2.4.1.3.配置tinyid\tinyid-server\src\main\resources\offline,tinyid\tinyid-server\src\main\resources\online的配置信息
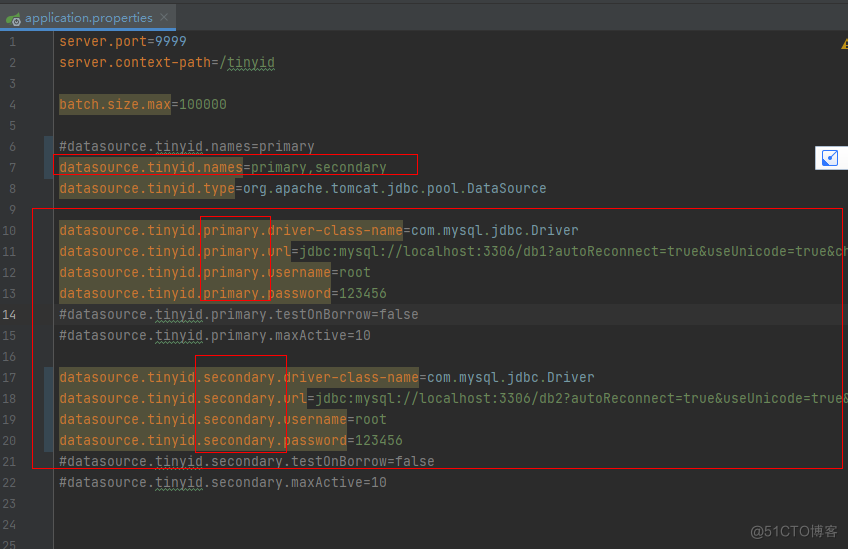
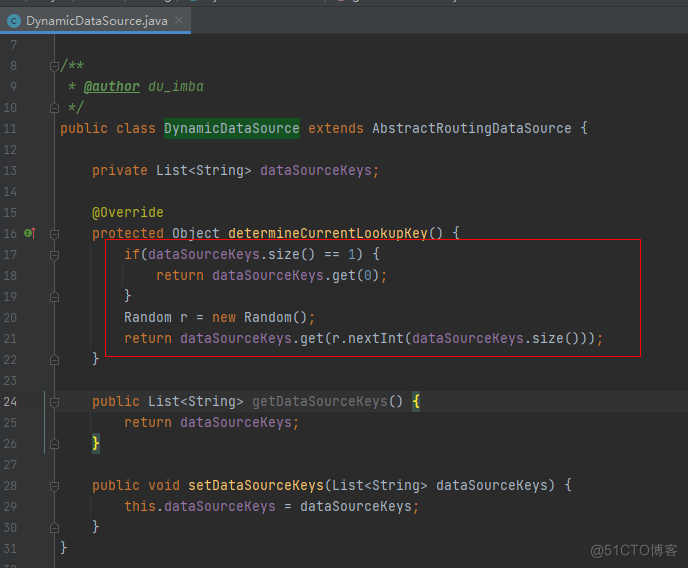
note:动态数据源的选择规则可以通过更改com.xiaoju.uemc.tinyid.server.config.DynamicDataSource类的获取方法:
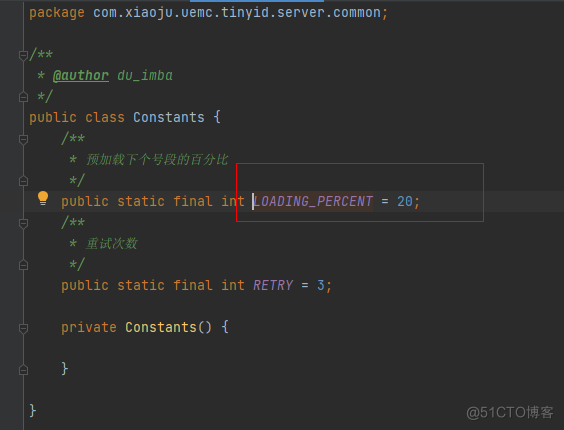
对于双号段配置可以调整如下:
最终的访问结构: