
写这篇文章的目的是为了记录一下自己对scrapy源码的阅读分析及重写过程,文章若有错误的地方,欢迎各位大佬阅读指正!☀️
特别声明:本公众号文章只作为学术研究,不用于其它用途。
目录
① 问题思考
② 源码分析
③ 源码重写
④ 心得分享
一、问题思考
1. 什么是Robots协议?
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
2. Scrapy的Robots协议定义在哪里?
定义在settings.py文件中。
参数:ROBOTSTXT_OBEY = True
说明:Robots协议默认是开启状态,网站管理员在网站域名的根目录下放一个robots.txt文本文件,里面可以指定不同的网络爬虫能访问的页面和禁止访问的页面,指定的页面由正则表达式表示。网络爬虫在采集这个网站之前,首先获取到这个文件,然后解析到其中的规则,然后根据规则来采集网站的数据。
3. 如何关闭Robots协议遵守?有哪些方法?
1)ROBOTSTXT_OBEY = True 将该参数的值改为False。
2)?
4. 源码如何实现Robots协议检测?
暂时还不知道,带着这些问题?我们直接阅读源码吧!
二、源码阅读
说明:本次源码分析使用的是scrapy2.6.1版本,大家不要迷路了!
1. 先构建一个小的demo,代码如下:
# spiders目录# -*- coding: utf-8 -*-import scrapyclass BaiduSpider(scrapy.Spider): name = "baidu" allowed_domains = ["baidu.com"] start_urls = ['http://baidu.com/'] def parse(self, response): print(response.text)settings.py文件:
# settings目录# -*- coding: utf-8 -*-BOT_NAME = 'scrapy_demo'SPIDER_MODULES = ['scrapy_demo.spiders']NEWSPIDER_MODULE = 'scrapy_demo.spiders'# Crawl responsibly by identifying yourself (and your website) on the user-agent#USER_AGENT = 'scrapy_demo (+http://www.yourdomain.com)'# Obey robots.txt rulesROBOTSTXT_OBEY = True # 先使用默认的True# Configure maximum concurrent requests performed by Scrapy (default: 16)#CONCURRENT_REQUESTS = 322. 运行代码后,结果如下:
2022-03-16 18:50:01 [scrapy.utils.log] INFO: Scrapy 2.6.1 started (bot: scrapy_demo)2022-03-16 18:50:01 [scrapy.utils.log] INFO: Versions: lxml 4.8.0.0, libxml2 2.9.12, cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0, Twisted 22.2.0, Python 3.7.9 (v3.7.9:13c94747c7, Aug 15 2020, 01:31:08) - [Clang 6.0 (clang-600.0.57)], pyOpenSSL 22.0.0 (OpenSSL 1.1.1n 15 Mar 2022), cryptography 36.0.2, Platform Darwin-21.3.0-x86_64-i386-64bit2022-03-16 18:50:01 [scrapy.crawler] INFO: Overridden settings:{'BOT_NAME': 'scrapy_demo', 'NEWSPIDER_MODULE': 'scrapy_demo.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['scrapy_demo.spiders']}2022-03-16 18:50:01 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor2022-03-16 18:50:01 [scrapy.extensions.telnet] INFO: Telnet Password: 90a5b28dfa1da5932022-03-16 18:50:01 [scrapy.middleware] INFO: Enabled extensions:['scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.telnet.TelnetConsole', 'scrapy.extensions.memusage.MemoryUsage', 'scrapy.extensions.logstats.LogStats']2022-03-16 18:50:02 [scrapy.middleware] INFO: Enabled downloader middlewares:['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware', 'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware', 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware', 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware', 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware', 'scrapy.downloadermiddlewares.retry.RetryMiddleware', 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware', 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware', 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware', 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware', 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware', 'scrapy.downloadermiddlewares.stats.DownloaderStats']2022-03-16 18:50:02 [scrapy.middleware] INFO: Enabled spider middlewares:['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware', 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware', 'scrapy.spidermiddlewares.referer.RefererMiddleware', 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware', 'scrapy.spidermiddlewares.depth.DepthMiddleware']2022-03-16 18:50:02 [scrapy.middleware] INFO: Enabled item pipelines:[]2022-03-16 18:50:02 [scrapy.core.engine] INFO: Spider opened2022-03-16 18:50:02 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)2022-03-16 18:50:02 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:60232022-03-16 18:50:02 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://baidu.com/robots.txt> (referer: None)2022-03-16 18:50:02 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET http://baidu.com/>2022-03-16 18:50:02 [scrapy.core.engine] INFO: Closing spider (finished)2022-03-16 18:50:02 [scrapy.statscollectors] INFO: Dumping Scrapy stats:{'downloader/exception_count': 1, 'downloader/exception_type_count/scrapy.exceptions.IgnoreRequest': 1, 'downloader/request_bytes': 219, 'downloader/request_count': 1, 'downloader/request_method_count/GET': 1, 'downloader/response_bytes': 2702, 'downloader/response_count': 1, 'downloader/response_status_count/200': 1, 'elapsed_time_seconds': 0.261867, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2022, 3, 16, 10, 50, 2, 381648), 'log_count/DEBUG': 3, 'log_count/INFO': 10, 'memusage/max': 64581632,从上面的代码中我们可以看到Robots协议已经生效了,截图如下:

3. 从上图我们可以看到机器人协议的下载中间件处理了该请求,为了方便大家了解整个流程,我需要粘贴一张scrapy流程图,如下:
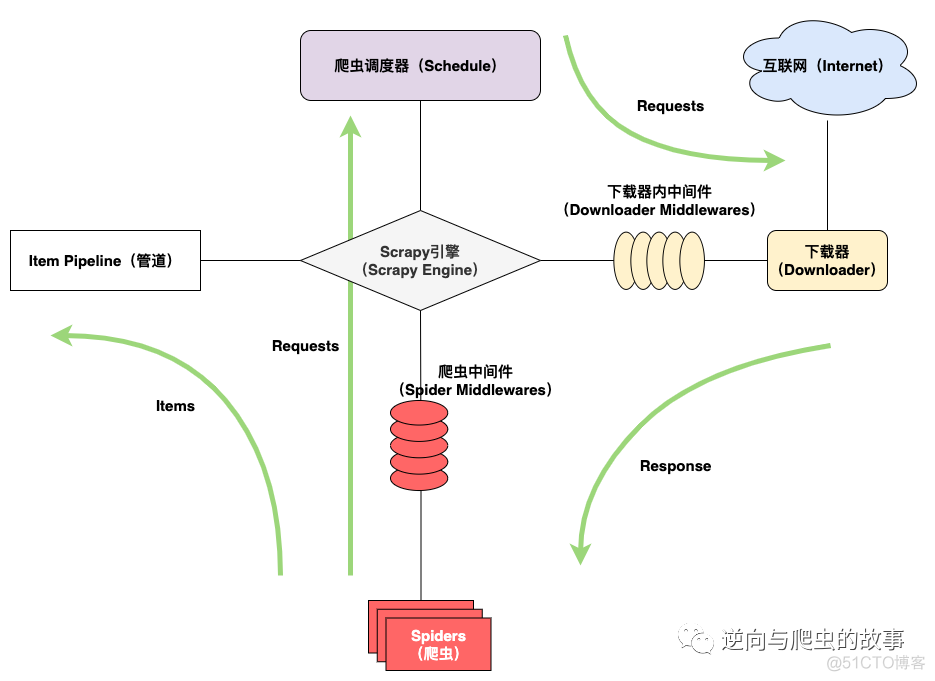
总结:观察这张图,结合我们刚刚启动的scrapy代码,能够清楚的分析出Engine从Spiders里拿出第一个Requests交给Scheduler去调度处理,Scheduler将获取的Requests按一定规则入队列处理后,分发给Downloader去下载;而在这个环节中,还会有一个下载中间件Downloader Middlewares。在Scheduler将请求下发给Downloader去下载过程中,下载中间件Downloader Middlewares会对该请求进行二次加工处理,确保这个请求到下载器中执行了一定的规则和逻辑。
通过上面的总结讲解后,我们应该可以确定这个Robots协议就是在Robots协议下载中间件中执行了一定操作,才能满足是否遵循Robots协议。
4. 直接上RobotsTxtMiddleware源代码如下:
"""This is a middleware to respect robots.txt policies. To activate it you mustenable this middleware and enable the ROBOTSTXT_OBEY setting."""import loggingfrom twisted.internet.defer import Deferred, maybeDeferredfrom scrapy.exceptions import NotConfigured, IgnoreRequestfrom scrapy.http import Requestfrom scrapy.utils.httpobj import urlparse_cachedfrom scrapy.utils.log import failure_to_exc_infofrom scrapy.utils.misc import load_objectlogger = logging.getLogger(__name__)class RobotsTxtMiddleware: DOWNLOAD_PRIORITY = 1000 def __init__(self, crawler): if not crawler.settings.getbool('ROBOTSTXT_OBEY'): raise NotConfigured self._default_useragent = crawler.settings.get('USER_AGENT', 'Scrapy') self._robotstxt_useragent = crawler.settings.get('ROBOTSTXT_USER_AGENT', None) self.crawler = crawler self._parsers = {} self._parserimpl = load_object(crawler.settings.get('ROBOTSTXT_PARSER')) # check if parser dependencies are met, this should throw an error otherwise. self._parserimpl.from_crawler(self.crawler, b'') @classmethod def from_crawler(cls, crawler): return cls(crawler) def process_request(self, request, spider): if request.meta.get('dont_obey_robotstxt'): return d = maybeDeferred(self.robot_parser, request, spider) d.addCallback(self.process_request_2, request, spider) return d def process_request_2(self, rp, request, spider): if rp is None: return useragent = self._robotstxt_useragent if not useragent: useragent = request.headers.get(b'User-Agent', self._default_useragent) if not rp.allowed(request.url, useragent): logger.debug("Forbidden by robots.txt: %(request)s", {'request': request}, extra={'spider': spider}) self.crawler.stats.inc_value('robotstxt/forbidden') raise IgnoreRequest("Forbidden by robots.txt") def robot_parser(self, request, spider): url = urlparse_cached(request) netloc = url.netloc if netloc not in self._parsers: self._parsers[netloc] = Deferred() robotsurl = f"{url.scheme}://{url.netloc}/robots.txt" robotsreq = Request( robotsurl, priority=self.DOWNLOAD_PRIORITY, meta={'dont_obey_robotstxt': True} ) dfd = self.crawler.engine.download(robotsreq) dfd.addCallback(self._parse_robots, netloc, spider) dfd.addErrback(self._logerror, robotsreq, spider) dfd.addErrback(self._robots_error, netloc) self.crawler.stats.inc_value('robotstxt/request_count') if isinstance(self._parsers[netloc], Deferred): d = Deferred() def cb(result): d.callback(result) return result self._parsers[netloc].addCallback(cb) return d else: return self._parsers[netloc] def _logerror(self, failure, request, spider): if failure.type is not IgnoreRequest: logger.error("Error downloading %(request)s: %(f_exception)s", {'request': request, 'f_exception': failure.value}, exc_info=failure_to_exc_info(failure), extra={'spider': spider}) return failure def _parse_robots(self, response, netloc, spider): self.crawler.stats.inc_value('robotstxt/response_count') self.crawler.stats.inc_value(f'robotstxt/response_status_count/{response.status}') rp = self._parserimpl.from_crawler(self.crawler, response.body) rp_dfd = self._parsers[netloc] self._parsers[netloc] = rp rp_dfd.callback(rp) def _robots_error(self, failure, netloc): if failure.type is not IgnoreRequest: key = f'robotstxt/exception_count/{failure.type}' self.crawler.stats.inc_value(key) rp_dfd = self._parsers[netloc] self._parsers[netloc] = None rp_dfd.callback(None)5. 源码阅读分析
1. 查看源代码__init__函数,我们可以发现:ROBOTSTXT_OBEY参数设置为Flase,这个中间件就触发异常不继续执行了,代码如下:
def __init__(self, crawler): if not crawler.settings.getbool('ROBOTSTXT_OBEY'): raise NotConfigured self._default_useragent = crawler.settings.get('USER_AGENT', 'Scrapy') self._robotstxt_useragent = crawler.settings.get('ROBOTSTXT_USER_AGENT', None) self.crawler = crawler self._parsers = {} self._parserimpl = load_object(crawler.settings.get('ROBOTSTXT_PARSER')) # check if parser dependencies are met, this should throw an error otherwise. self._parserimpl.from_crawler(self.crawler, b'') class NotConfigured(Exception): """Indicates a missing configuration situation""" pass说明:触发异常后,也不会报错,scrapy的源码将该错误进行了忽略,这也是为什么我们看不到报错的原因!
2. 我们继续往下说,当ROBOTSTXT_OBEY参数设置为True时,代码将会往下执行,检测访问的该请求是否含有机器人协议。代码如下:
def process_request(self, request, spider): if request.meta.get('dont_obey_robotstxt'): return d = maybeDeferred(self.robot_parser, request, spider) d.addCallback(self.process_request_2, request, spider) return ddef robot_parser(self, request, spider): url = urlparse_cached(request) netloc = url.netloc if netloc not in self._parsers: self._parsers[netloc] = Deferred() robotsurl = f"{url.scheme}://{url.netloc}/robots.txt" robotsreq = Request( robotsurl, priority=self.DOWNLOAD_PRIORITY, meta={'dont_obey_robotstxt': True} ) dfd = self.crawler.engine.download(robotsreq) dfd.addCallback(self._parse_robots, netloc, spider) dfd.addErrback(self._logerror, robotsreq, spider) dfd.addErrback(self._robots_error, netloc) self.crawler.stats.inc_value('robotstxt/request_count')当一个请求经过下载中间件,首先会过process_request函数,在这个函数中,由于我们并没有在meta参数中设置dont_obey_robotstxt属性!所以这段代码会继续执行到下面,执行twisted.internet.defer的异步方法maybeDeferred去处理。在robot_parser函数中对该请求进行特殊处理,查看指定域名的网站下面是否含有robots.txt文件,这也是我们前面提到的内容。如果指定域名的服务器根目录有这个文件,则会去发送该请求,此时:
meta={'dont_obey_robotstxt': True}是为了保证该请求只执行一次。引擎最后将该请求交给下载器去下载,如果下载成功stats统计中间件会将:
obotstxt/request_count参数value递增1。
robotstxt/response_count参数value递增1。
robotstxt/response_status_count/{response.status} 参数递增1。
如果该请求响应结果为异常或者错误,是下面的统计结果:
'robotstxt/exception_count/{failure.type}'参数的value递增1。
最后执行下面的代码:
def process_request_2(self, rp, request, spider): if rp is None: return useragent = self._robotstxt_useragent if not useragent: useragent = request.headers.get(b'User-Agent', self._default_useragent) if not rp.allowed(request.url, useragent): logger.debug("Forbidden by robots.txt: %(request)s", {'request': request}, extra={'spider': spider}) self.crawler.stats.inc_value('robotstxt/forbidden') raise IgnoreRequest("Forbidden by robots.txt")
发现和我们运行的log几乎一致吧,这就是整个代码的运行流程!
三、源码重写
我们对scrapy作者的代码阅读完毕后,即可进行魔性玩法,如下:
方案一:
# -*- coding: utf-8 -*-import scrapyclass BaiduSpider(scrapy.Spider): name = "baidu" allowed_domains = ["baidu.com"] start_urls = ['http://baidu.com/'] def start_requests(self): yield scrapy.Request(url=self.start_urls[0], callback=self.parse, meta={'dont_obey_robotstxt': True}) def parse(self, response): print(response.text)""" 此方案为 ROBOTSTXT_OBEY = True时,即可跳过robots协议中间件检测。 需要将:dont_obey_robotstxt = True."""方案二:
DOWNLOADER_MIDDLEWARES = { 'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': None,}方案三:
class RobotsTxtMiddleware: DOWNLOAD_PRIORITY = 1000 def __init__(self, crawler): raise NotConfigured @classmethod def from_crawler(cls, crawler): return cls(crawler)四、心得分享
需要对scrapy的运行机制有所了解,感谢大家阅读,欢迎大家多多交流指正☀️

我是TheWeiJun,有着执着的追求,信奉终身成长,不定义自己,热爱技术但不拘泥于技术,爱好分享,喜欢读书和乐于结交朋友,欢迎加我微信与我交朋友。
分享日常学习中关于爬虫、逆向和分析的一些思路,文中若有错误的地方,欢迎大家多多交流指正☀️
