作者:京东零售 刘世杰
本文结合京东监控埋点场景,对解决样板代码的技术选型方案进行分析,给出最终解决方案后,结合理论和实践进一步展开。通过关注文中的技术分析过程和技术场景,读者可收获一种样板代码思想过程和解决思路,并对Java编译器底层有初步了解。
一、背景
监控是服务端应用需要具备的一个非常重要的能力,通过监控可以直观的看到核心业务指标、服务运行质量等,而要做到可监控就需要进行相应的监控埋点。大家在埋点过程中经常会编写大量重复代码,虽能实现基本功能,但耗时耗力,不够优雅。根据“DRY(Don't Repeat Yourself)"原则,这是代码中的“坏味道”,对有代码洁癖的人来讲,这种重复是不可接受的。
那有什么方法解决这种“重复”吗?经过综合调研,基于前端编译器插桩技术,实现了一个埋点组件,通过织入埋点逻辑,让Java 编译器帮我们写代码。经过不断打磨,已经被包括京东APP主站服务端在内的很多团队广泛使用。
本文主要是结合监控埋点这个场景分享一种解决样板化代码的思路,希望能起到抛砖引玉的作用。下面将从组件介绍、技术选型过程、实现原理及部分源码实现逐步展开讲解。
二、组件介绍
京东内部监控系统叫UMP,与所有的监控系统一样,核心部分有埋点、上报、分析整合、报警、看板等等,本文讲的组件主要是为对监控埋点原生能力的增强,提供一种更优雅简洁的实现。
下面先来看下传统硬编码的埋点方式,主要分为创建埋点对象、可用率记录、提交埋点 3 个步骤:
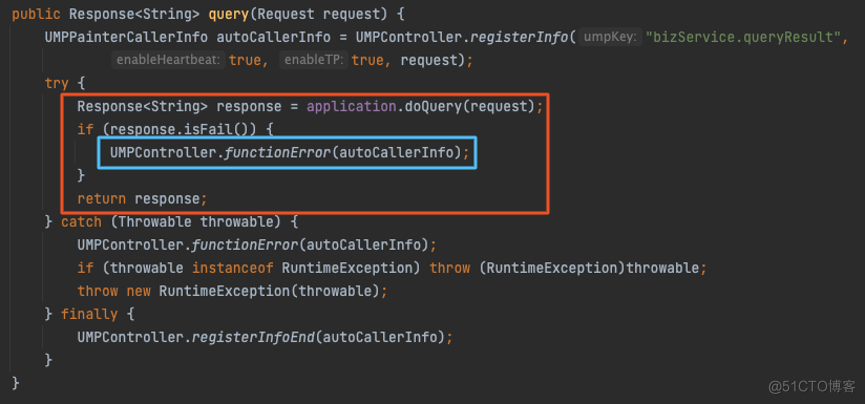
通过上图可以看到,真正的逻辑只有红框中的范围,为了完成埋点要把这段代码都围绕起来,代码层级变深,可读性差,所有埋点都是这样的样板代码。
下面来看下使用组件后的埋点方式:

通过对比很容易看到,使用组件后的方式只要在方法上加一个注解就可以了,代码可读性有明显的提升。
组件由埋点封装API和AST操作处理器 2 部分组成。
埋点API封装:在运行时被调用,对原生埋点做了封装和抽象,方便使用者进行监控KEY的扩展。
AST操作处理器:在编译期调用,它将根据注解@UMP把埋点封装API按照规则织入方法体内。
(注:结合京东实际业务场景,组件实现了fallback、自定义可用率、重名方法区分、配套的IDE插件、监控key自定义生成规则等细节功能,由于本文主要是讲解底层实现原理,详细功能不在此赘述)
三、技术选型过程
通过上面的示例代码,相信很多人觉得这个功能很简单,用 Spring AOP 很快就能搞定了。的确很多团队也是这么做的,不过这个方案并不是那么完美,下面的选型分析中会有相关的解释,请耐心往下看。如下图,从软件的开发周期来看,可织入埋点的时机主要有 3 个阶段:编译期、编译后和运行期。

3.1 编译前
这里的编译期指将Java源文件编译为class字节码的过程。Java编译器提供了基于 JSR 269 规范[1]的注解处理器机制,通过操作AST (抽象语法树,Abstract Syntax Tree,下同)实现逻辑的织入。业内有不少基于此机制的应用,比如Lombok 、MapStruct 、JPA 等;此机制的优点是因为在编译期执行,可以将问题前置,没有多余依赖,因此做出来的工具使用起来比较方便。缺点也很明显,要熟练操作 AST并不是想的那么简单,不理解前后关联的流程写出来的代码不够稳定,因此要花大量时间熟悉编译器底层原理。当然这个过程对使用者来讲是没有感知的。
3.2 编译后
编译后是指编译成 class 字节码之后,通过字节码进行增强的过程。此阶段插桩需要适配不同的构建工具:Maven、Gradle、Ant、Ivy等,也需要使用方增加额外的构建配置,因此存在开发量大和使用不够方便的问题,首先要排除掉此选项。可能只有极少数场景下才会需要在此阶段插桩。
3.3 运行期
运行期是指在程序启动后,在运行时进行增强的过程,这个阶段有 3 种方式可以织入逻辑,按照启动顺序,可以分为:静态 Agent、AOP 和动态 Agent。
3.3-1 静态 Agent
JVM 启动时使用 -javaagent 载入指定 jar 包,调用 MANIFEST.MF 文件里的 Premain-Class 类的 premain 方法触发织入逻辑。是技术中间件最常使用的方式,借助字节码工具完成相关工作。应用此机制的中间件有很多,比如:京东内部的链路监控 pfinder、外部开源的 skywalking 的探针、阿里的 TTL 等等。这种方式优点是整体比较成熟,缺点主要是兼容性问题,要测试不同的 JDK 版本代价较大,出现问题只能在线上发现。同时如果不是专业的中间件团队,还是存在一定的技术门槛,维护成本比较高;
3.3-2 Spring AOP
Spring AOP大家都不陌生,通过 Spring 代理机制,可以在方法调用前后织入逻辑。AOP 最大的优点是使用简单,同样存在不少缺点:
1) 同一类内方法A调用方法B时,是无法走到切面的,这是Spring 官方文档的解释[2] “However, once the call has finally reached the target object (the SimplePojo reference in this case), any method calls that it may make on itself, such as this.bar() or this.foo(), are going to be invoked against the this reference, and not the proxy”。这个问题会导致内部方法调用的逻辑执行不到。在监控埋点这个场景下就会出现丢数据的情况;
2) AOP只能环绕方法,方法体内部的逻辑没有办法干预。靠捕捉异常判断逻辑是不够的,有些场景需要是通过返回值状态来判断逻辑是否正常,使用介绍里面的示例代码就是此种情况,这在 RPC 调用解析里是很平常的操作。
3) 私有方法、静态方法、final class和方法等场景无法走切面
3.3-3 动态 Agent
动态加载jar包,调用MANIFEST.MF文件中声明的Agent-Class类的agentmain方法触发织入逻辑。这种方式主要用来线上动态调试,使用此机制的中间件也有很多,比如:Btrace、Arthas等,此方式不适合常驻内存使用,因此要排除掉。
3.4 最终方案选择
通过上面的分析梳理可知,要实现重复代码的抽象有 3 种方式:基于JSR 269 的插桩、基于 Java Agent 的字节码增强、基于Spring AOP的自定义切面。接下来进一步的对比:
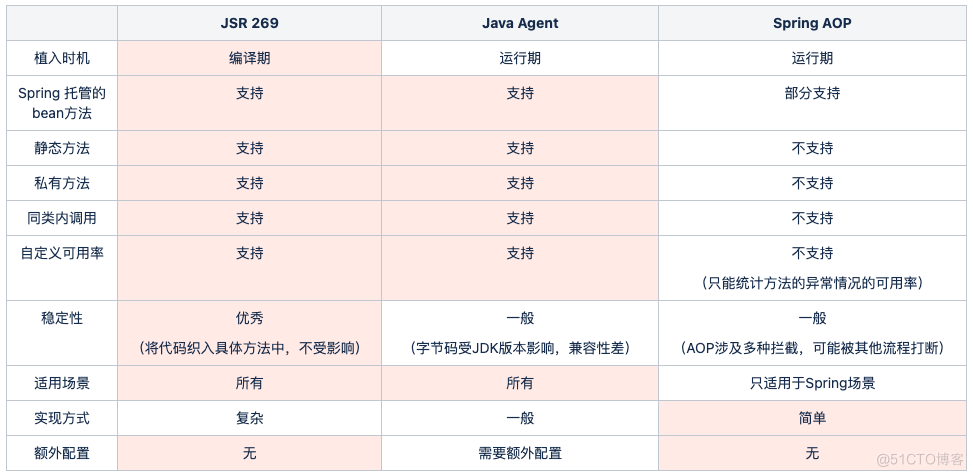
如上表所示,从实现成本上来看,AOP 最简单,但这个方案不能覆盖所有场景,存在一定的局限性,不符合我们追求极致的调性,因此首先排除。Java Agent 能达到的效果与 JSR 269 相同,但是启动参数里需要增加 -javaagent 配置,有少量的运维工作,同时还有 JDK 兼容性的坑需要趟,对非中间件团队来说,这种方式从长久看会带来负担,因此也要排除。基于 JSR 269 的插桩方式,对Java编译器工作流程的理解和 AST 的操作会带来实现上的复杂性,前期投入比较大,但是组件一旦成型,会带来一劳永逸的解决方案,可以很自信的讲,插桩实现的组件是监控埋点场景里的银弹(事实证明了这点,不然也不敢这么吹)。
冰山之上,此组件给使用者带来了简洁优雅的体验,一个jar包,一行代码,妙笔生花。那冰山之下是如何实现的呢?那就要从原理说起了。
四、插桩实现原理
简单来讲,插桩是在编译期基于 JSR 269的注解处理器中操作AST的方式操纵语法节点,最终编译到class文件中。要做好插桩理解相关的底层原理是必要的。大多数读者对编译器相关内容比较陌生,这里会用较大的篇幅做个相对系统的介绍。
Java编译器是将源码翻译成 class 字节码的工具,Java编译器有多种实现:Open JDK的javac、Eclipse的ecj和ajc、IBM的jikes等,javac是公司内主要的编译器,本文是基于Open JDK 1.8 讲解。
作为一款工业级编译器内部实现比较复杂,其涵盖的内容足够写一本书了。结合本人对javac源码的理解,尝试通俗易懂的讲清楚插桩涉及到的知识,有不尽之处欢迎指正。有兴趣进一步研究的读者建议阅读 javac源码[6]。
下面将讲解编译器执行流程,相关javac源码导航,以及注解处理器如何运作。
4.1 编译器执行流程
根据官网资料[3]javac 处理流程可以粗略的分为 3个部分:Parse and Enter、Annotation Processing、Analyse and Generate,如下图:

Parse and Enter
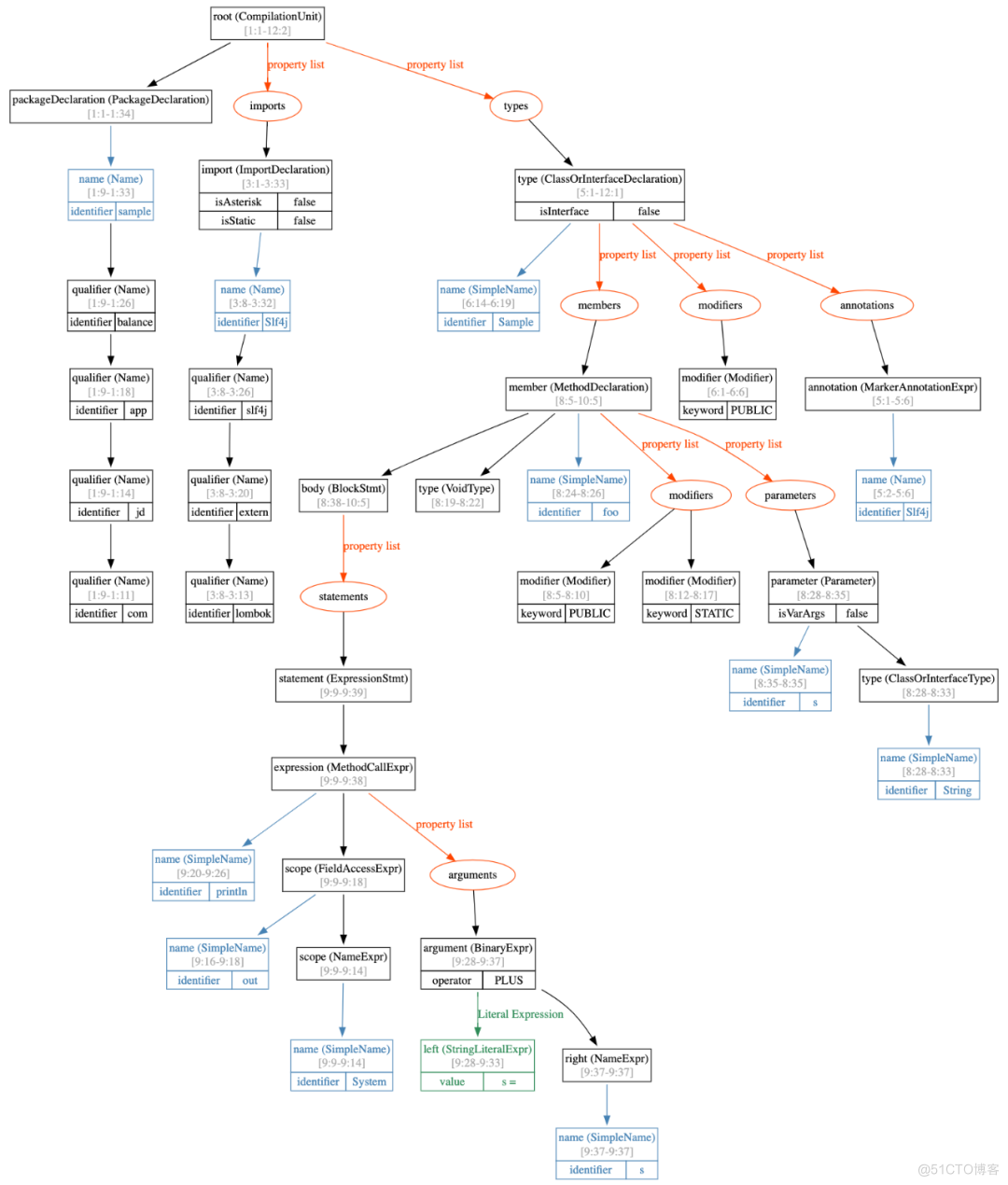
Parse阶段主要通过词法分析器(Scanner)读取源码生产 token 流,被语法分析器(JavacParser)消费构造出AST,Java代码都可以通过AST表达出来,读者可以通过JCTree查看相关的实现。为了让读者能更直观的理解AST,本人做了一个源码解析成AST后的图形化展示:
(注:AST图形生成通过IDEA插件JavaParser-AST-Inspector生成dot格式文本,并使用线上工具GraphvizOnline转换为图片,见参考资料5、7)
示例源码:
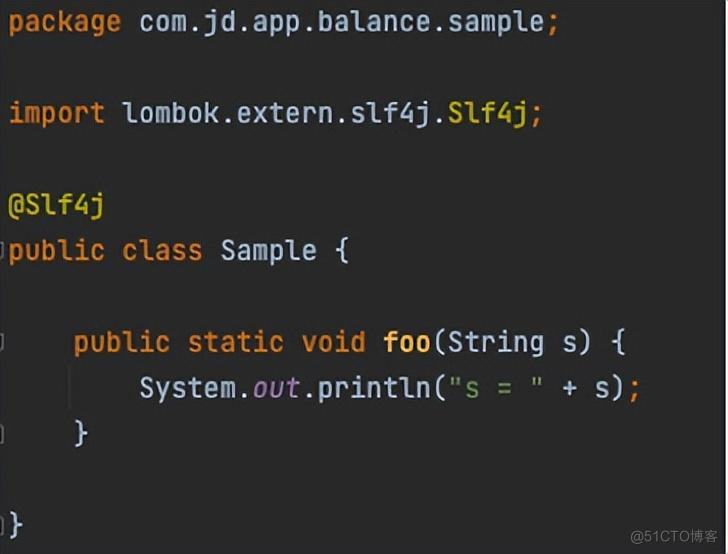
token流:
[ package ] <- [ com ] <- [ . ] <- …... <- [ } ]
解析成AST后如下:
Enter阶段主要是根据AST填充符号表,此处为插桩之后的流程,因此不再展开。
Annotation Processing
注解处理阶段,此处会调用基于 JSR269 规范的注解处理器,是javac对外的扩展。通过注解处理器让开发者(指非javac开发者,下同)具备自定义执行逻辑的能力,这就是插桩的关键。在这个阶段,可以获取到前一阶段生成的AST,从而进行操作。
Analyse and Generate
分析AST并生成class字节码,此处为插桩之后的流程,不再展开。
4.2 相关javac源码导航
javac触发入口类路径是:com. sun. tools. javac. Main,代码如下:
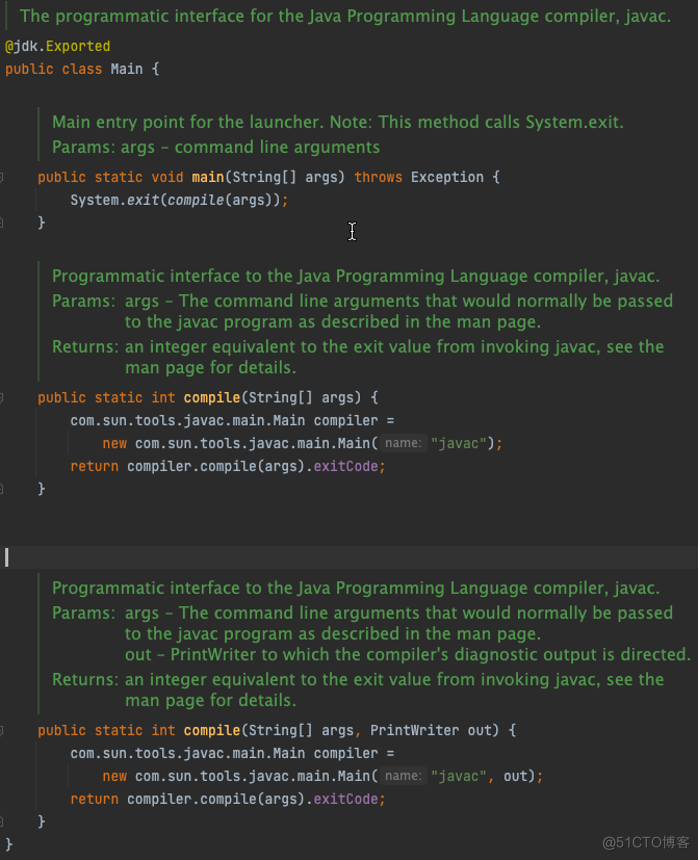
经验证Maven 执行构建调的是此类中的main方法。其他构建工具未做验证,猜测类似的。在JDK内部也提供了javax. tools. Tool Provider# get System Java Compiler的入口,实际上内部实现也是调的这个类里的compile方法。
经过一系列的命令参数解析和初始化操作,最终调到真正的核心入口,方法是com. sun. tools. javac. main. Java Compiler# compile,如下图:
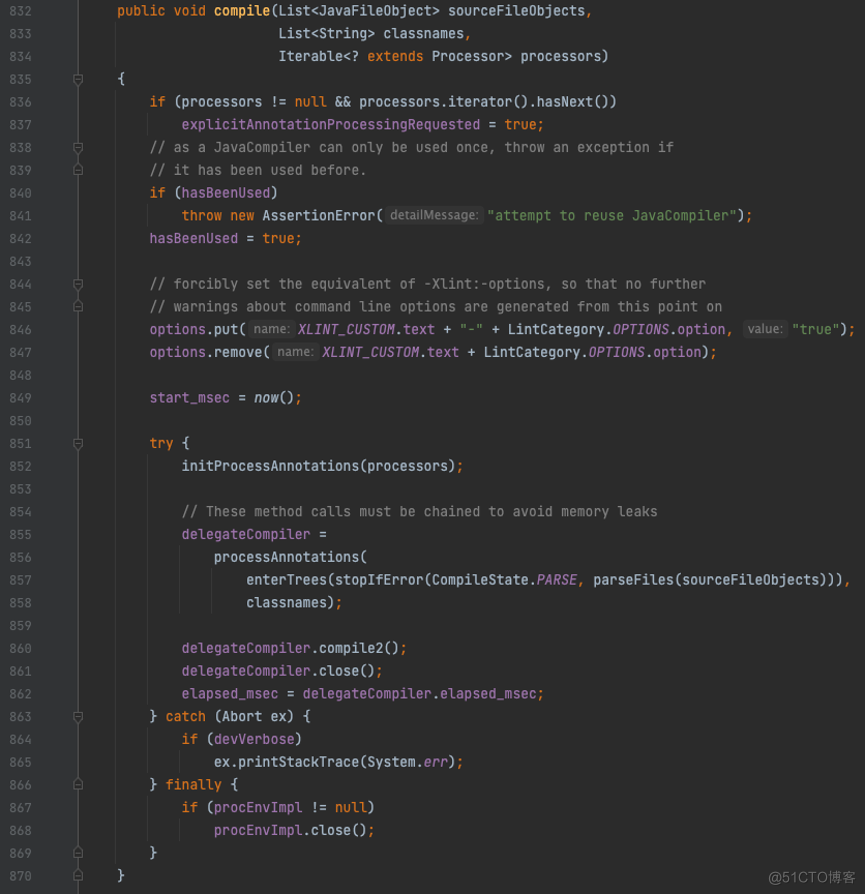
这里有3个关键调用:
852行:初始化注解处理器,通过Main入口的调用是通过JDK SPI的方式收集。
855–858行:对应前面流程图里的Parse and Enter和Annotation Processing两个阶段的流程,其中方法processAnnotations便是执行注解处理器的触发入口。
860行:对应Analyse and Generate阶段的流程。
4.3 注解处理器
Java从JDK 1.6 开始,引入了基于JSR 269 规范的注解处理器,允许开发者在编译期间执行自己的代码逻辑。如本文讲的UMP监控埋点插桩组件一样,由此衍生出了很多优秀的技术组件,如前面提到的Lombok、Mapstruct等。注解处理器使用比较简单,后面示例代码有注解处理器简单实现也可以参考。这里重点讲一下注解处理器整体执行原理:
1、编译开始的时候,会执行方法init Process Annotations (compile的截图852行),以SPI的方式收集到所有的注解处理器,SPI对应接口:javax. annotation. processing. Processor。
2、在方法process Annotations中执行注解处理器调用方法Javac Processing Environment# do Processing。
3、所有的注解处理器处理完毕一次,称为一轮(round),每轮开始会执行一次Processor# init方法以便开发者自定义初始化信息,如缓存上下文等。初始化完成后,javac会根据注解、版本等条件过滤出符合条件的注解处理器,并调用其接口方法Processor# process,即开发者自定义的实现。
4、在开发者自定义的注解处理器里,实现AST操作的逻辑。
5、一轮执行完成后,发现新的Java源文件或者class文件,则开启新的一轮。直到不再产生Java或者class文件为止。有的开源项目实现注解处理器时,为了保证自身可以继续执行,会通过这个机制创建一个空白的Java文件达到目的,其实这也是理解原理的好处。
6、如果在一轮中未发现新的Java源文件和class文件产生则执行最后一轮(last Round)。最后一轮执行完毕后,如果有新的Java源文件生成,则进行Parse and Enter 流程处理。到这里,整个注解处理器的流程就结束了。
7、进入Analyse and Generate阶段,最终生成class,完成整体编译。
接下来将通过UMP监控埋点功能来展示怎么在注解处理器中操作AST。
五、源码示例
关于AST 操作的探索,早在2008年就有相关资料了[4],Lombok、Mapstruct都是开源的工具,也可以用来参考学习。这里简单讲一个示例,展示如何插桩。
注解处理器使用框架
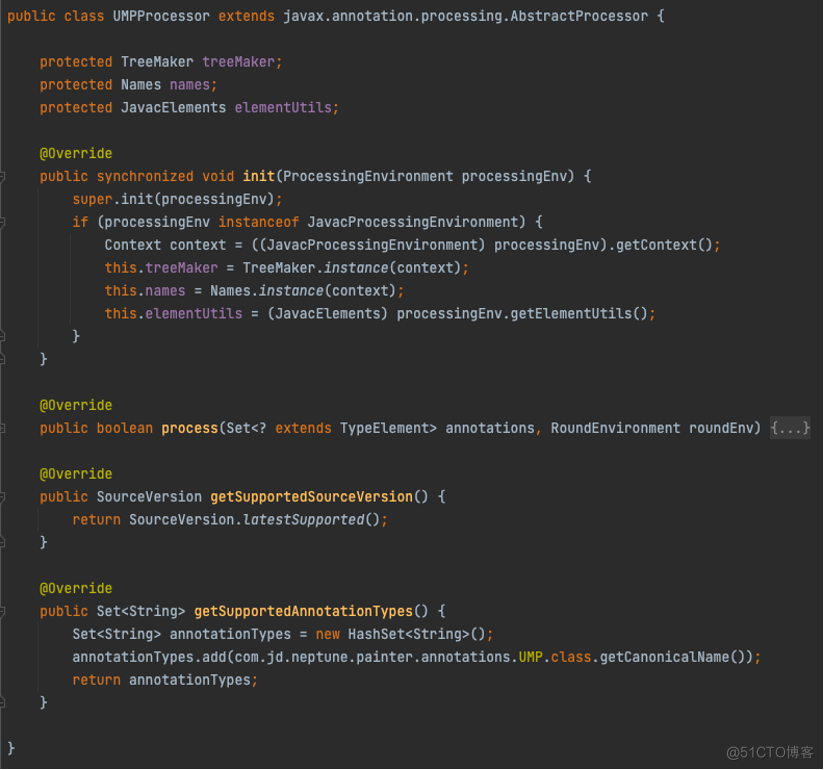
上图展示了注解处理器具体的基本使用框架,init、process是注解处理器的核心方法,前者是初始化注解处理器的入口,后者是操作AST的入口。javac还提供了一些有用的工具类,比如:
TreeMaker:创建AST的工厂类,所有的节点都是继承自JCTree,并通过TreeMaker完成创建。
JavacElements:操作Element的工具类,可以用来定位具体AST。
向类中织入一个import节点
这里举一个简单场景,向类中织入一个import节点:

为方便理解对代码实现做了简化,可以配合注释查看如何织入:
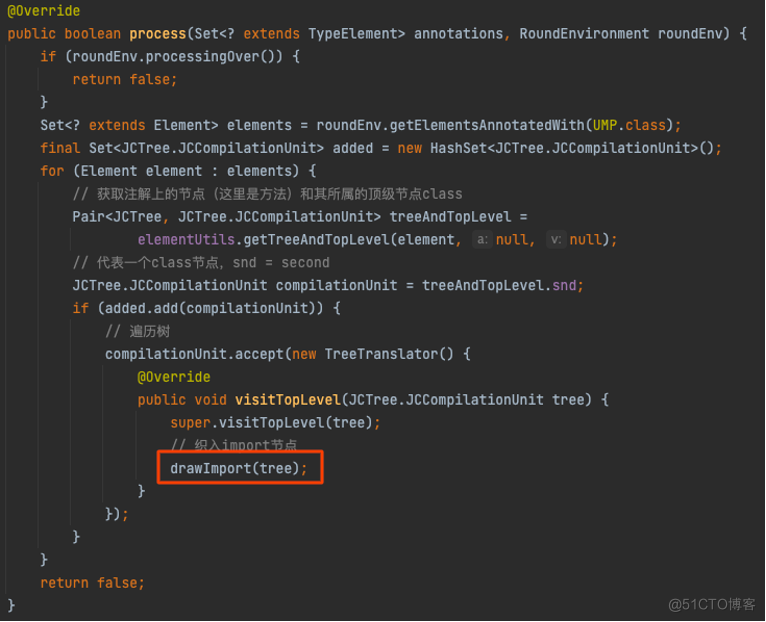
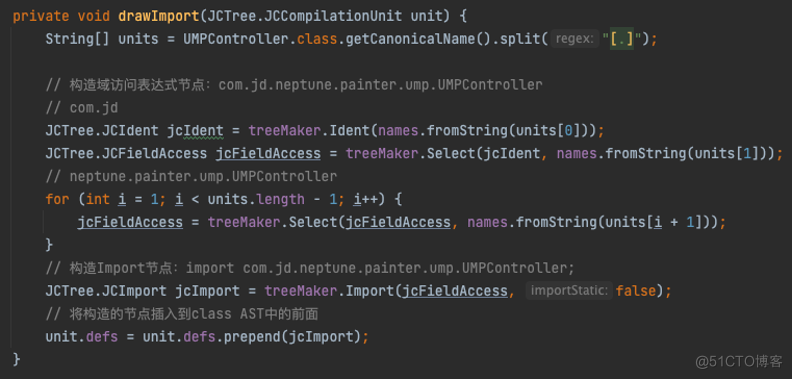
总的来说,织入逻辑是通过TreeMaker创建AST 节点,并操作现有AST织入创建的节点,从而达到了织入代码的目的。
六、反思与总结
到这里,讲了埋点组件的使用、技术选型、以及插桩相关的内容,最终开发出来的组件在工作中也起到了很好的效果。但是在这个过程中有一些反思。
1、插桩门槛高
通过前面的内容不难得出一个事实,要实现一个小小的功能,需要开发者花费大量的精力去学习理解编译器底层的一些原理。从ROI角度看,投入和产出是严重不成正比的。为了能提供可靠的实现,个人花费了大量业余时间去做技术选型分析和编译器相关知识,可以说是纯靠个人的兴趣和一股倔劲一点点搭建起来的,细节是魔鬼,这个踩坑的过程比较枯燥。实际上插桩机制有很多通用的场景可以探索,之所以一直很少见到此类机制的应用。主要是其门槛较高,对大多数开发者来说比较陌生。因此降低开发者使用门槛才能让一些想法变成现实。做一把好用的锤子,比砸入一个钉子要更有价值。
在监控埋点插桩组件真正落地时,在项目内做了一定抽象,并支持了一些开关、自定义链路跟踪等功能。但从作用范围来讲是不够的,所以下一步计划做一个插桩方面的技术框架,从易用性、可维护性等方面做好进一步的抽象,同时做好可测试性相关工作,包含验证各版本JDK的支持、各种Java语法的覆盖等。
2、插桩是把双刃剑
javac官方对修改AST的方式持保守态度,也存在一些争议。然而时间是最好的验证工具,从Lombok 等组件的发展看出,插桩机制是能经住长久考验的。如何合理利用这种能力是非常重要的,合理使用可使系统简洁优雅,使用不当就等于在代码里下毒了。所以要有节制的修改AST,要懂前后运行机制,围绕通用的场景使用,避免滥用。
3、认识当前上下文环境的局限性
遇到问题时,如果在当前的上下文环境里找不到合适的解决方案,从这个环境跳出来换个维度也许能看到不同的风景。就像物理机到虚拟机再到现在的容器,都是打破了原来的规则逐步发展出新的技术生态。大多数的开发工作都是基于一个高层次的封装上面进行,而突破往往都是从底层开始的,适当的时候也可以向下做一些探索,可能会产生一些有价值的东西。
参考文献
[1] JSR 269:
https://www.jcp.org/en/jsr/detail?id=269
[2] Understanding AOP Proxies:
https://docs.spring.io/spring-framework/docs/current/reference/html/core.html#aop-understanding-aop-proxies
[3] Compilation Overview:
https://openjdk.org/groups/compiler/doc/compilation-overview/index.html
[4] The Hacker’s Guide to Javac:
http://scg.unibe.ch/archive/projects/Erni08b.pdf
[5] JavaParser-AST-Inspector:
https://github.com/MysterAitch/JavaParser-AST-Inspector
[6] OpenJDK source:
http://hg.openjdk.java.net/jdk8u/jdk8u60/langtools/
[7] Graphviz Online:
https://dreampuf.github.io/GraphvizOnline/#digraph%20G%20%7B%7D