目录
- 前言
- 架构图
- 源码解析
- Fetch
- onBefore
- onRequest
- onSuccess
- onFinally
- onError
- 其它 API
- 小结
- plugins
- usePollingPlugin
- useRetryPlugin
- 小结
- useRequest
- 对自定义 hook 的思考
- 总结
前言
自从 React v16.8 推出了 Hooks API,前端框架圈并开启了新的逻辑复用的时代,不再需要在意 HOC 的无限套娃导致性能差的问题,也解决了 mixin 的可阅读性差的问题。当然对于 React 最大的变化是函数式组件可以有自己的状态,扁平化的逻辑组织方式,更加友好地支持 TS 类型声明。
除了 React 官方提供的一些 Hooks,也支持我们能根据自己的业务场景自定义 Hooks,还有一些通用的 Hooks,例如用于请求的 useRequest,用于定时器的 useTimeout,用于节流的 useThrottle 等。于是出现了大量的 Hooks 库,ahooks 是其中比较受欢迎的 Hooks 库之一,其提供了大量的 Hooks,基本满足了大多数场景的需求。又是国人开发,中文文档友好,在我们团队的一些项目中就使用了 ahooks。
其中最常用的 hooks 就是 useRequest,用于从后端请求数据的业务场景,除了简单的数据请求,它还支持:
- 轮询
- 防抖和节流
- 错误重试
- SWR(stale-while-revalidate)
- 缓存
等功能,基本上满足了我们请求后端数据需要考虑的大多数场景,当然还有 loading-delay、页面 foucs 重新刷新数据等这些功能,但是个人理解上面列的功能才是使用比较频繁的功能点。
一个 Hooks 实现这么多功能,我还是对其内部的实现比较好奇的,所以本文就从源码的角度带大家了解 useRequest 的实现。
架构图
我们从一张图开始了解其模块设计,对于一个功能复杂的 API,如果不使用合适的架构和方式组织代码,其扩展性和可维护性肯定比较差。功能点实现和核心代码混在一起,阅读代码的人也无从下手,也带来更大的测试难度。虽然 useRequest 只是一个 Hook,但是实际上其设计还是有清晰的架构,我们来看看 useRequest 的架构图:
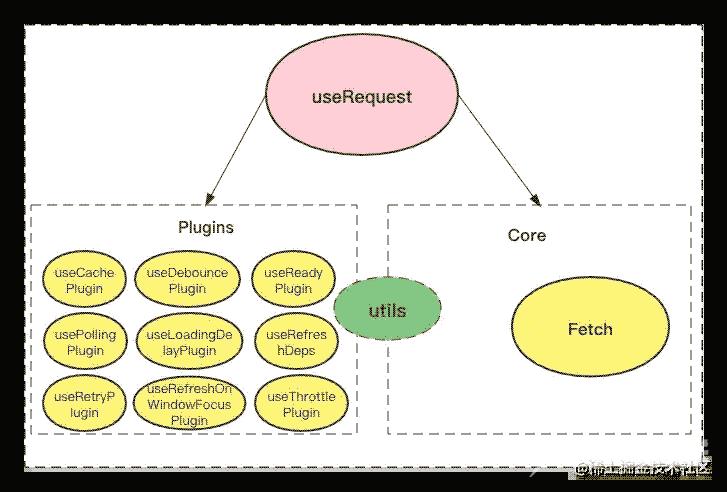
我把 useRequest 的模块划分为三大块:Core、Plugins、utils,然后 useRequest 将这些模块组合在一起实现核心功能。
先看插件部分,看到每个插件的命名,如果了解 useRequest 的功能就会发现,基本上每个功能点对应一个插件。这也是 useRequest 设计比较巧妙的一点,通过插件化机制降低了每个功能之间的耦合度,也降低了其本身的复杂度。这些点我们在分析具体的源码的时候会再详细介绍。
另外一部分核心的代码我将其归类为 Core(在 useRequest 的源码中没有这个名词),主要实现了一个 Fetch 类,这个类是 useRequest 的插件化机制实现和其它功能的核心实现。
下面我们深入源码,看下其实现原理。
源码解析
先看 Core 部分的源码,主要是 Fetch 这个类的实现。
Fetch
先贴代码:
export default class Fetch<TData, TParams extends any[]> {
pluginImpls: PluginReturn<TData, TParams>[];
count: number = 0;
state: FetchState<TData, TParams> = {
loading: false,
params: undefined,
data: undefined,
error: undefined,
};
constructor(
public serviceRef: MutableRefObject<Service<TData, TParams>>,
public options: Options<TData, TParams>,
public subscribe: Subscribe,
public initState: Partial<FetchState<TData, TParams>> = {},
) {
this.state = {
...this.state,
loading: !options.manual,
...initState,
};
}
setState(s: Partial<FetchState<TData, TParams>> = {}) {
// 省略一些代码
}
runPluginHandler(event: keyof PluginReturn<TData, TParams>, ...rest: any[]) {
// 省略一些代码
}
async runAsync(...params: TParams): Promise<TData> {
// 省略一些代码
}
run(...params: TParams) {
// 省略一些代码
}
cancel() {
// 省略一些代码
}
refresh() {
// 省略一些代码
}
refreshAsync() {
// 省略一些代码
}
mutate(data?: TData | ((oldData?: TData) => TData | undefined)) {
// 省略一些代码
}
}
Fetch 类 API 的设计还是比较简洁的,而且也不是特别多,实际上有些 API 就是直接从 useRequest 暴露给外部用户使用的,比如 run、runAsync、cancel、refresh、refreshAsync、mutate 等。像 runPluginHandler、setState 等 API 主要是给内部用的 API,不过它也没有做区分,从封装的角度上来说,这一点个人感觉设计得不够好。
重点关注下几个 Fetch 类的属性,一个是 state,它的类型是 FetchState<TData, TParams>,一个是 pluginImpls,它是 PluginReturn<TData, TParams> 数组,实际上这个属性就用来存所有插件执行后返回的结果。还有一个 count 属性,是 number 类型,不看具体源码,完全不知道这个属性是做什么用的。这点也是 useRequest 开发者做得感觉不是很好的地方,很少有注释,纯靠阅读者深入到源码,去看使用的地方,才能知道一些方法和属性的作用。
那我们先来看下 FetchState<TData, TParams> 的定义,它定义在 src/type.ts 里面:
export interface FetchState<TData, TParams extends any[]> {
loading: boolean;
params?: TParams;
data?: TData;
error?: Error;
}
它的定义还是比较简单,看起来是存一个请求结果的上下文信息,这些信息其实都是需要暴露给外部用户的,例如 loading、data、errors 等不就是我们使用 useRequest 经常需要拿到的数据信息:
const { data, error, loading } = useRequest(service);
而对应的 Fetch 封装了 setState API,实际上就是用来更新 state 的数据:
setState(s: Partial<FetchState<TData, TParams>> = {}) {
this.state = {
...this.state,
...s,
};
// ? 未知
this.subscribe();
}
除了更新 state,这里还调用了一个 subscribe 方法,这是初始化 Fetch 类的时候传进来的一个参数,它的类型是 Subscribe,等后面将到调用的地方再看这个方法是怎么实现的,以及它的作用。
再看下 PluginReturn<TData, TParams> 的类型定义:
export interface PluginReturn<TData, TParams extends any[]> {
onBefore?: (params: TParams) =>
| ({
stopNow?: boolean;
returnNow?: boolean;
} & Partial<FetchState<TData, TParams>>)
| void;
onRequest?: (
service: Service<TData, TParams>,
params: TParams,
) => {
servicePromise?: Promise<TData>;
};
onSuccess?: (data: TData, params: TParams) => void;
onError?: (e: Error, params: TParams) => void;
onFinally?: (params: TParams, data?: TData, e?: Error) => void;
onCancel?: () => void;
onMutate?: (data: TData) => void;
}
实际上都是一些回调钩子,从名字对应上来看,对应了请求的各个阶段,除了 onMutate 是其内部扩展的一个钩子。
也就是说 pluginImpls 里面存的是一堆含有各个钩子函数的对象集合,如果技术敏锐的同学,可能很容易就想到发布订阅模式,这不就是存了一系列的 subscribe 回调,这不过这是一个回调的集合,里面有各种不同请求阶段的回调。那么到底是不是这样,我们继续往下看。
要搞清楚 Fetch 的运作方式,我们需要看两个核心 API 的实现:runPluginHandler 和 runAsync,其它所有的 API 实际上都在调用这两个 API,然后做一些额外的特殊逻辑处理。
先看 runPluginHandler:
runPluginHandler(event: keyof PluginReturn<TData, TParams>, ...rest: any[]) {
// @ts-ignore
const r = this.pluginImpls.map((i) => i[event]?.(...rest)).filter(Boolean);
return Object.assign({}, ...r);
}
这个方法实现还是比较简单,只有两行代码。跟我们之前猜测的大致差不多,这个方法就是接收一个 event 参数,它的类型就是 keyof PluginReturn<TData, TParams>,也就是:onBefore | onRequest | onSuccess | onError | onFinally | onCancel | onMutate 的联合类型,以及其它额外的参数,然后从 pluginImpls 中找出所有对应的 event 回调钩子函数,然后执行回调函数,拿到结果并返回。
再看 runAsync 的实现:
async runAsync(...params: TParams): Promise<TData> {
this.count += 1;
const currentCount = this.count;
const {
stopNow = false,
returnNow = false,
...state
} = this.runPluginHandler('onBefore', params);
// stop request
if (stopNow) {
return new Promise(() => {});
}
this.setState({
loading: true,
params,
...state,
});
// return now
if (returnNow) {
return Promise.resolve(state.data);
}
this.options.onBefore?.(params);
try {
// replace service
let { servicePromise } = this.runPluginHandler('onRequest', this.serviceRef.current, params);
if (!servicePromise) {
servicePromise = this.serviceRef.current(...params);
}
const res = await servicePromise;
if (currentCount !== this.count) {
// prevent run.then when request is canceled
return new Promise(() => {});
}
// const formattedResult = this.options.formatResultRef.current ? this.options.formatResultRef.current(res) : res;
this.setState({
data: res,
error: undefined,
loading: false,
});
this.options.onSuccess?.(res, params);
this.runPluginHandler('onSuccess', res, params);
this.options.onFinally?.(params, res, undefined);
if (currentCount === this.count) {
this.runPluginHandler('onFinally', params, res, undefined);
}
return res;
} catch (error) {
if (currentCount !== this.count) {
// prevent run.then when request is canceled
return new Promise(() => {});
}
this.setState({
error,
loading: false,
});
this.options.onError?.(error, params);
this.runPluginHandler('onError', error, params);
this.options.onFinally?.(params, undefined, error);
if (currentCount === this.count) {
this.runPluginHandler('onFinally', params, undefined, error);
}
throw error;
}
}
看着代码挺多的,其实看下来很好理解。 这个函数实际上做的事就是调用我们传入的获取数据的方法,然后拿到成功或者失败的结果,进行一系列的数据处理,然后更新到 state,执行插件的各回调钩子,还有就是我们通过 options 传入的回调函数。
可能直接用文字直接描述比较抽象,下面我们分请求阶段分析代码。
首先前两行是对 count 属性的累加处理,之前我们不知道这个属性的作用,看到这里可能猜测大概是跟请求相关的,后面看到 currentCount 的使用的地方,我们再说。
onBefore
接下来 5~27 行实际上是对 onBefore 回调钩子的执行,然后拿到结果做的一些逻辑处理。这里调用的就是 runPluginHandler 方法,传入的参数是 onBefore 和外部用户定义的 params 参数。然后执行完所有的 onBefore 钩子函数,拿到最后的结果,如果 stopNow 的 flag 是 true,则直接返回没有结果的 Promise。看注释,我们知道这里实际上做的是取消请求的处理,当我们在 onBefore 的钩子里实现了取消的逻辑,符合条件后并会真正的阻断请求。
如果没有取消,然后接着更新 state 数据,如果立即返回的 returnNow flag 为 true,则立马将更新后的 state 返回,否则执行用户传入的 options 中的 onBefore 回调,也就是说在调用 useRequest 的时候,我们可以通过 options 参数传入 onBefore 函数,进行请求之前的一些逻辑处理。
onRequest
接下来后面的代码就是真正执行请求数据的方法了,这里就会执行所有的 onRequest 钩子。实际上,通过 onRequest 钩子我们是可以重写传入的获取数据的方法,因为最后执行的是 onRequest 回调返回的 servicePromise。
拿到最后执行的请求数据方法,就开始发起请求。在这里发现了前面的 currentCount 的使用,它会去对比当前最新的 count 和执行这个方法时定义的 currentCount 是否相等,如果不相等,则会做类似于取消请求的处理。这里大概知道 count 的作用类似于一个”锁“的作用,我的理解是,如果在执行这些代码过程有产生一些比这里优先级更高的处理逻辑或者请求操作,是需要 cancel 掉这次的请求,以最新的请求为准。当然,最后还是要看哪些地方可能会修改 count。
onSuccess
执行完请求后,如果请求成功,则拿到请求返回的数据,更新到 state,执行用户传入的成功回调和各插件的成功回调钩子。
onFinally
成功之后,执行 onFinally 钩子,这里也很严谨,也会比较 count 的值,确保一致之后,才会执行各插件的回调钩子,预发一些”竞态“情况的发生。
onError
如果请求失败,就会进入到 catch 分支,执行一些处理错误的逻辑,更新 error 信息到 state 中。同样这里也会有 count 的对比,然后执行 onError 的回调。执行完 onError 也会同样执行 onFinally 的回调,因为一个请求要么成功,要么失败,都会需要执行最后的 onFinally 回调。
其它 API
其它的例如 run、cancel、refresh 等 API,实际上调用的是 runPluginHandler 和 runAsync API,例如 run:
run(...params: TParams) {
this.runAsync(...params).catch((error) => {
if (!this.options.onError) {
console.error(error);
}
});
}
代码很容易看懂,就不过多介绍。
我们来看看 cancel 的实现:
cancel() {
this.count += 1;
this.setState({
loading: false,
});
this.runPluginHandler('onCancel');
}
最后的 runPluginHandler 调用我们已经很清楚它的作用了,这里值得注意的是对 count 的修改。前面我们提到每次 runAsync 一些核心阶段会判断 count 是否和 currentCount 能对得上,看到这里我们就彻底明白了 count 的作用了。实际上在我们执行了 run 的操作,如果在本次 runAsync 方法执行过程中,我们就调用了 cancel 方法,那么无论是在请求发起前还是后,都会把本次执行当做 cancel 处理,返回空的数据。也就是说,这个 count 就是为了实现请求取消功能的一个标识。
小结
看完了 runAsync 的实现,实际上就代表我们看完了 Fetch 的核心逻辑。从一个请求的生命周期角度来看,其实它的实现就很容易理解,主要做两件事:
- 执行各阶段的钩子回调;
- 更新数据到 state。
这归功于 useRequest 的巧妙设计,我们看这部分源码,只要看懂了类型和两个核心的方法,都不用关心具体每个插件的实现。它将每个功能点的复杂度和核心的逻辑通过插件机制隔离开来,从而每个插件只需要按一定的契约实现好自己的功能就行,然后 Fetch 不管有多少插件,只负责在合适的时间点调用插件钩子,做到了完全的解耦。
plugins
其实看完了 Fetch,还没看插件,你脑子里就大概知道怎么去实现一个插件。因为插件比较多,限于篇幅原因,这里就以 usePollingPlugin 和 useRetryPlugin 两个插件为例,进行详细的源码介绍。
usePollingPlugin
首先需要清楚一点每个插件实际也是一个 Hook,所以在它内部可以使用任何 Hook 的功能或者调用其它 Hook。先看 usePollingPlugin:
const usePollingPlugin: Plugin<any, any[]> = (
fetchInstance,
{ pollingInterval, pollingWhenHidden = true },
) => {
const timerRef = useRef<NodeJS.Timeout>();
const unsubscribeRef = useRef<() => void>();
const stopPolling = () => {
if (timerRef.current) {
clearTimeout(timerRef.current);
}
unsubscribeRef.current?.();
};
useUpdateEffect(() => {
if (!pollingInterval) {
stopPolling();
}
}, [pollingInterval]);
if (!pollingInterval) {
return {};
}
return {
onBefore: () => {
stopPolling();
},
onFinally: () => {
// if pollingWhenHidden = false && document is hidden, then stop polling and subscribe revisible
if (!pollingWhenHidden && !isDocumentVisible()) {
unsubscribeRef.current = subscribeReVisible(() => {
fetchInstance.refresh();
});
return;
}
timerRef.current = setTimeout(() => {
fetchInstance.refresh();
}, pollingInterval);
},
onCancel: () => {
stopPolling();
},
};
};
它接受两个参数,一个是 fetchInstance,也就是前面提到的 Fetch 实例,第二个参数是 options,支持传入 pollingInterval、pollingWhenHidden 两个属性。这两个属性从命名上比较容易理解,一个就是轮询的时间间隔,另外一个猜测应该是可以在某种场景下通过设置这个 flag 停止轮询。在真实的场景中,确实有比如要求用户在切换到其它 tab 页时停止轮询等这样的需求。所以这个配置,还比较好理解。
而每个插件的作用就是在请求的各个阶段进行定制化的逻辑处理,以轮询为例,其最核心的逻辑在于 onFinally 的回调,在每次请求结束后,设置一个 setTimeout,然后按用户传入的 pollingInterval 进行定时执行 Fetch 的 refresh 方法。
还有就是停止轮询的时机,每次用户主动取消请求,在 onCancel 的回调停止轮询。如果已经开始了轮询,在每次新的请求调用的时候先停止上一次的轮询,避免重复。当然包括,如果组件修改了 pollingInterval 等的时候,需要先停止掉之前的轮询。
useRetryPlugin
假设让你去设计一个 retry 的插件,那么你的设计思路是什么了?需要关注的核心逻辑是什么?还是前面那句话: 每个插件的作用就是在请求的各个阶段进行定制化的逻辑处理,那如果要实现 retry 肯定你首要关注的是,什么时候才需要 retry?答案显而易见,那就是请求失败的时候,也就是需要在 onError 回调实现 retry 的逻辑。考虑得周全一点,你还需要知道 retry 的次数,因为第二次也可能失败了。当然还有就是 retry 的时间间隔,失败后多久 retry?这些是外部使用者关心的,所以应该将它们设计成配置项。
分析好了需求,我们看下 retry 插件的实现:
const useRetryPlugin: Plugin<any, any[]> = (fetchInstance, { retryInterval, retryCount }) => {
const timerRef = useRef<NodeJS.Timeout>();
const countRef = useRef(0);
const triggerByRetry = useRef(false);
if (!retryCount) {
return {};
}
return {
onBefore: () => {
if (!triggerByRetry.current) {
countRef.current = 0;
}
triggerByRetry.current = false;
if (timerRef.current) {
clearTimeout(timerRef.current);
}
},
onSuccess: () => {
countRef.current = 0;
},
onError: () => {
countRef.current += 1;
if (retryCount === -1 || countRef.current <= retryCount) {
// Exponential backoff 指数补偿
const timeout = retryInterval ?? Math.min(1000 * 2 ** countRef.current, 30000);
timerRef.current = setTimeout(() => {
triggerByRetry.current = true;
fetchInstance.refresh();
}, timeout);
} else {
countRef.current = 0;
}
},
onCancel: () => {
countRef.current = 0;
if (timerRef.current) {
clearTimeout(timerRef.current);
}
},
};
};
第一个参数跟 usePollingPlugin 的插件一样,都是接收 Fetch 实例,第二个参数是 options,支持 retryInterval、retryCount 等选型,从命名上看跟我们刚开始分析需求的时候想的差不多。
看代码,核心的逻辑主要是在 onError 的回调中。首先前面定义了一个 countRef,记录 retry 的次数。执行了 onError 回调,代表新的一次请求错误发生,然后判断如果 retryCount 为 -1,或者当前 retry 的次数还小于用户自定义的次数,则通过一个定时器设置下次 retry 的时间,否则将 countRef 重置。
还需要注意的是其它的一些回调的处理,比如当请求成功或者被取消,需要重置 countRef,取消的时候还需要清理可能存在的下一次 retry 的定时器。
这里 onBefore 的逻辑处理怎么理解了?首先这里会有一个 triggerByRetry 的 flag,如果 flag 是 false。则会清空 countRef。然后会将 triggerByRetry 设置为 false,然后清理掉上一次可能存在的 retry 定时器。我个人的理解是这里设置一个 flag 是为了避免如果 useRequest 重新执行,导致请求重新发起,那么在 onBefore 的时候需要做一些重置处理,以防和上一次的 retry 定时器撞车。
小结
其它插件的设计思路是类似的,关键是要分析出你需要实现的功能是作用在请求的哪个阶段,那么就需要在这个钩子里实现核心的逻辑处理。然后再考虑其它钩子的一些重置处理,取消处理等,所以在优秀合理的设计下实现某个功能它的成本是很低的,而且也不需要关心其它插件的逻辑,这样每个插件也是可以独立测试的。
useRequest
分析了核心的两块源码,我们来看下,怎么组装最后的 useRequest。首先在 useRequest 之前,还有一层抽象叫 useRequestImplement,看下是怎么实现的:
function useRequestImplement<TData, TParams extends any[]>(
service: Service<TData, TParams>,
options: Options<TData, TParams> = {},
plugins: Plugin<TData, TParams>[] = [],
) {
const { manual = false, ...rest } = options;
const fetchOptions = {
manual,
...rest,
};
const serviceRef = useLatest(service);
const update = useUpdate();
const fetchInstance = useCreation(() => {
const initState = plugins.map((p) => p?.onInit?.(fetchOptions)).filter(Boolean);
return new Fetch<TData, TParams>(
serviceRef,
fetchOptions,
update,
Object.assign({}, ...initState),
);
}, []);
fetchInstance.options = fetchOptions;
// run all plugins hooks
// 这里为什么可以使用 map 循环去执行每个插件 hooks
fetchInstance.pluginImpls = plugins.map((p) => p(fetchInstance, fetchOptions));
useMount(() => {
if (!manual) {
// useCachePlugin can set fetchInstance.state.params from cache when init
const params = fetchInstance.state.params || options.defaultParams || [];
// @ts-ignore
fetchInstance.run(...params);
}
});
useUnmount(() => {
fetchInstance.cancel();
});
return {
loading: fetchInstance.state.loading,
data: fetchInstance.state.data,
error: fetchInstance.state.error,
params: fetchInstance.state.params || [],
cancel: useMemoizedFn(fetchInstance.cancel.bind(fetchInstance)),
refresh: useMemoizedFn(fetchInstance.refresh.bind(fetchInstance)),
refreshAsync: useMemoizedFn(fetchInstance.refreshAsync.bind(fetchInstance)),
run: useMemoizedFn(fetchInstance.run.bind(fetchInstance)),
runAsync: useMemoizedFn(fetchInstance.runAsync.bind(fetchInstance)),
mutate: useMemoizedFn(fetchInstance.mutate.bind(fetchInstance)),
} as Result<TData, TParams>;
}
前面两个参数如果使用过 useRequest 的都知道,就是我们通常传给 useRequest 的参数,一个是请求 api,一个就是 options。这里还多了个插件参数,大概可以知道,内置的一些插件应该会在更上层的地方传进来,做一些参数初始化的逻辑。
然后通过 useLatest 构造一个 serviceRef,保证能拿到最新的 service。接下来,使用 useUpdate Hook 创建了update 方法,然后再创建 fetchInstance 的时候作为第三个参数传递给 Fetch,这里就是我们前面提到过的 subscribe。那我们要看下 useUpdate 做了什么:
const useUpdate = () => {
const [, setState] = useState({});
return useCallback(() => setState({}), []);
};
原来是个”黑科技“,类似 class 组件的 $forceUpdate API,就是通过 setState,让组件强行渲染一次。
接着就是使用 useMount,如果发现用户没有设置 manual 或者将其设置为 false,立马会执行一次请求。当组件被销毁的时候,在 useUnMount 中进行请求的取消。最后返回暴露给用户的数据和 API。
最后看下 useRequest 的实现:
function useRequest<TData, TParams extends any[]>(
service: Service<TData, TParams>,
options?: Options<TData, TParams>,
plugins?: Plugin<TData, TParams>[],
) {
return useRequestImplement<TData, TParams>(service, options, [
...(plugins || []),
useDebouncePlugin,
useLoadingDelayPlugin,
usePollingPlugin,
useRefreshOnWindowFocusPlugin,
useThrottlePlugin,
useRefreshDeps,
useCachePlugin,
useRetryPlugin,
useReadyPlugin,
] as Plugin<TData, TParams>[]);
}
这里就会把内置的插件传入进去,当然还有用户自定义的插件。实际上 useRequest 是支持用户自定义插件的,这又突出了插件化设计的必要性。除了能降低本身自己的功能之间的复杂度,也能提供更多的灵活度给到用户,如果你觉得功能不够,实现自定义插件吧。
对自定义 hook 的思考
面向对象编程里面有一个原则叫职责单一原则, 我个人理解它的含义是我们在设计一个类或者一个方法时,它的职责应该尽量单一。如果一个类的抽象不在一个层次,那么这个类注定会越来越膨胀,难以维护。一个方法职责越单一,它的复用性就可能越高,可测试性也越好。
其实我们在设计一个 hooks,也是需要参照这个原则的。Hooks API 出现的一个重大意义,就是解决我们在编写组件时的逻辑复用问题。没有 Hooks,之前是使用 HOC、Render props或者 Mixin 等解决逻辑复用的问题,然而每一种方式在大量实践后都发现有明显的缺点。所以,我们在自定义一个 Hook 时,总是应该朝着提高复用性的角度出发。
光说太抽象,举个之前我在业务开发中遇到的一个例子。在一个项目中,我们封装了一个计算预算的 Hook 叫 useBudgetValidate,不方便贴所有代码,下面通过伪代码列下这个 Hook 做的事:
export default function useBudgetValidate({ id, dailyBudgetType, mode }: Options) {
const [dailyBudgetSetting, setDailyBudgetSetting] = useState<BudgetSetting | null>(null);
// 从后端获取某个数据
const { data: adSetCountRes } = useRequest(
(campaign: ReactText) => getSomeData({ params: { id } }));
// 从后端获取预算配置
useRequest(
() => {
return getBudgetSetting();
},
{
onSuccess: result => setDailyBudgetSetting(result),
},
);
/**
* 对于传入的预算的类型, 返回的预算设置
*/
const currentDailyBudgetSetting: DailyBudgetSetting | undefined = useMemo(() => {
if (dailyBudgetType === BudgetTypeEnum.AdSet) {
return dailyBudgetSetting?.adset;
}
if (dailyBudgetType === BudgetTypeEnum.Smart) {
return dailyBudgetSetting?.smart;
}
const campaignBudget = dailyBudgetSetting?.campaign;
// 这里有大量的计算逻辑,得到最后的 campaignBudget
return campaignBudget;
}, []);
return {
currentDailyBudgetSetting,
dailyBudgetSetting,
};
}
初一看,这个 Hook 没有太大的问题,不就是从后端获取数据,然后根据不同的传参进行预算计算,然后返回预算信息。但是现在有个问题,因为计算预算是项目通用的逻辑。在另外一个页面也需要这段计算逻辑,但是那个页面已经从后端其它的接口获取了预算信息,或者通过其它方式构造了计算预算需要的数据。所以这里的核心矛盾点在于很多页面依赖这段计算逻辑,但是数据来源是不一致的。将获取预算配置和其它信息的接口逻辑放在这个 Hook 里面就会导致它的职责不单一,所以没法很容易在其它场景复用。
重构的思路很简单,就是将数据请求的逻辑抽离,单独封装一个 Hook,或者把职责交给组件去做。这个 Hook 只做一件事,那就是接收配置和其它参数,进行预算计算,将结果返回给外面。
但是对于 useRequest 这样功能很复杂的 Hook 又怎么理解了?从功能上看,感觉它既做了一般请求数据的功能,又做了轮询,做了缓存,做了重试,做了。。。反正很多很多的职责。
但是,如果你认真思考,发现这些功能又是依赖请求这个关键点,也就是说从这个角度来看,它们的抽象是在同一层次上。而且 useRquest 是一个更加通用的 Hook,它作为一个 package 给大量的用户使用。如果你是一个使用者,你八成希望它是什么能力都有,你需要的它有,你暂时不需要的,它也帮你想好了。
在 Philosophy of Software Design 一书中提到一个概念叫:深模块,它的意思是:深模块是那些既提供了强大功能但又有着简单接口的模块。在设计一些模块或者 API 的时候,比如像 useRequest 这种,那么就要符合这个原则,用户只需要少量的配置,就能使用各插件带来的丰富功能。
所以最后,总结下:如果我们在日常业务开发封装一些 Hook,我们应该尽量保证职责单一,以提高其复用性。如果我们需要设计一个抽象程度很高,然后给多个项目使用的 Hook,那么在设计的时候,应该符合深模块的特点,接口尽量简单,又需要满足各需求场景,将功能复杂度隐藏在 Hook 内部。
总结
本文主要从 Fetch 类的实现和 plugins 的设计详细解析了 useRequest 的源码,看完源码,我们知道了:
- useRequest 核心源码主要在 Fetch 类的实现中,通过巧妙的将请求划分为各个阶段的设计,然后把丰富的功能交给每个插件去实现,解耦功能之间的关系,降低本身维护的复杂度,提高可测试性;
- useRequest 虽然只是一个代码千行左右的 Hook,但是通过插件化机制,使得各个功能之间完全解耦,提高了代码的可维护性和可测试性,同时也提供了用户自定义插件的能力;
- 职责单一的原则在任何场景下引用都不会过时,我们在设计一些 Hook 的时候应该也要考虑单一原则。但是在设计一些跨多项目通用的 Hook,应该朝着深模块的角度设计,提供简单的接口,把复杂度隐藏在模块内部。
以上就是ahooks useRequest源码精读解析的详细内容,更多关于ahooks useRequest源码的资料请关注易盾网络其它相关文章!