因为评论有很多人说爬取不到,我强调几点 kv的格式应该是这样的: kv = {‘cookie':‘你复制的一长串cookie',‘user-agent':‘Mozilla/5.0'} 注意都应该用 ‘' ,然后还有个英文的 逗号, kv写完要
因为评论有很多人说爬取不到,我强调几点
kv的格式应该是这样的:
kv = {‘cookie':‘你复制的一长串cookie',‘user-agent':‘Mozilla/5.0'}
注意都应该用 ‘' ,然后还有个英文的 逗号,
kv写完要在后面的代码中添加
r = requests.get(url, headers=kv,timeout=30)
自己得先登录自己的淘宝账号才有自己登陆的cookie呀,没登录cookie当然没用
以下原博
本人是python新手,目前在看中国大学MOOC的嵩天老师的爬虫课程,其中一个实例是讲如何爬取淘宝商品信息
以下是代码:
import requests
import re
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price , title])
except:
print("")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1]))
def main():
goods = '书包'
depth = 3
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44*i)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)
main()
但是我们运行的时候会发现这个程序没有出错,但是爬取不到,原因是淘宝实施了反爬虫机制,r.text 时是登录界面,我们如何绕过登录界面进行爬取呢?
首先我们需要先在浏览器中登录我们的个人淘宝,然后搜索以书包为例的商品,打开开发者模式(我使用的是chrome)或者按F12
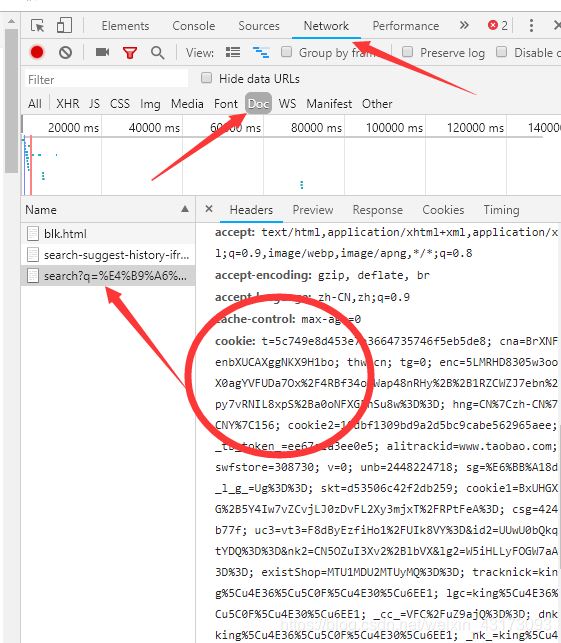
这里我们可以看到我们当前的cookie和user-agent(一般是Mozilla/5.0)(注意:如果没有出现这几个name,点击浏览器刷新就会出现了)
然后在代码中增加我们的cookie和user-agent
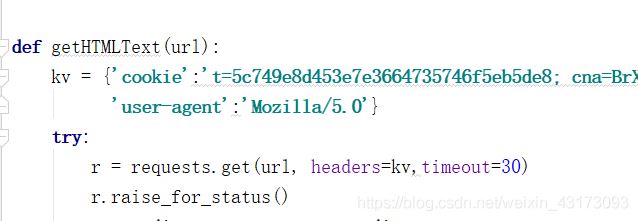
然后运行

我只是个初学者,学的时候视频给不了答案,百度了很多,才发现这个小技巧,
有问题百度就完事了
完整代码
import requests
import re
def getHTMLText(url):
kv = {'cookie':'t=5c749e8d453e7e3664735746f5eb5de8; cna=BrXNFDenbXUCAXggNKX9H1bo; thw=cn; tg=0; enc=5LMRHD8305w3oo8X0agYVFUDa7Ox%2F4RBf34oCWap48nRHy%2B%2B1RZCWZJ7ebn%2Fpy7vRNIL8xpS%2Ba0oNFXG5nSu8w%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156; cookie2=10dbf1309bd9a2d5bc9cabe562965aee; _tb_token_=ee67e1a3ee0e5; alitrackid=www.taobao.com; swfstore=308730; v=0; unb=2448224718; sg=%E6%BB%A18d; _l_g_=Ug%3D%3D; skt=d53506c42f2db259; cookie1=BxUHGXuG%2B5Y4Iw7vZCvjLJ0zDvFL2Xy3mjxT%2FRPtFeA%3D; csg=4246b77f; uc3=vt3=F8dByEzfiHo1%2FUIk8VY%3D&id2=UUwU0bQkq1tYDQ%3D%3D&nk2=CN5OZuI3Xv2%2BlbVX&lg2=W5iHLLyFOGW7aA%3D%3D; existShop=MTU1MDU2MTUyMQ%3D%3D; tracknick=king%5Cu4E36%5Cu5C0F%5Cu4E30%5Cu6EE1; lgc=king%5Cu4E36%5Cu5C0F%5Cu4E30%5Cu6EE1; _cc_=VFC%2FuZ9ajQ%3D%3D; dnk=king%5Cu4E36%5Cu5C0F%5Cu4E30%5Cu6EE1; _nk_=king%5Cu4E36%5Cu5C0F%5Cu4E30%5Cu6EE1; cookie17=UUwU0bQkq1tYDQ%3D%3D; lastalitrackid=login.taobao.com; mt=ci=5_1; x=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0%26__ll%3D-1%26_ato%3D0; uc1=cookie14=UoTZ5OXqJxXKdA%3D%3D&lng=zh_CN&cookie16=W5iHLLyFPlMGbLDwA%2BdvAGZqLg%3D%3D&existShop=false&cookie21=UIHiLt3xThH8t7YQouiW&tag=8&cookie15=UIHiLt3xD8xYTw%3D%3D&pas=0; JSESSIONID=F99B5E66516B99D5E7C9F431E402713F; l=bBNU0zKPvJ9oGfuLBOCNZuI8LN_OGIRYjuPRwCfMi_5B46JhzLQOllv3_FJ6Vj5RsK8B4z6vzNp9-etki; isg=BDg4VI5GkPAaMvx83RJGSPCNCeYKCZ0m9uCVOHKp6XNmjdh3GrU6uo2vQcWY5lQD; whl=-1%260%260%261550562673185',
'user-agent':'Mozilla/5.0'}
try:
r = requests.get(url, headers=kv,timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def parsePage(ilt, html):
try:
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"', html)
for i in range(len(plt)):
price = eval(plt[i].split(':')[1])
title = eval(tlt[i].split(':')[1])
ilt.append([price, title])
except:
print("")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号", "价格", "商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count, g[0], g[1]))
def main():
goods = '书包'
depth = 3
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = []
for i in range(depth):
try:
url = start_url + '&s=' + str(44 * i)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)
main()
到此这篇关于python爬虫爬取淘宝商品比价(附淘宝反爬虫机制解决小办法)的文章就介绍到这了,更多相关python爬取淘宝商品内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!