目录
- ⛄引言
- 一、使用Elastic Search 的好处
- 二、部署ES
- ⛅部署kibana
- ⚡部署分词器
- 三、词典扩展与停用
- ⛅扩展词典
- ⚡停用词典
- ⛵小结
⛄引言
本文参考黑马 分布式Elastic search
Elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容
一、使用Elastic Search 的好处
用数据库,也可以实现搜索的功能,为什么还需要搜索引擎呢?
数据库(理论上来讲,ES 也是数据库,这里的数据库,指的是关系型数据库),首先是存储,搜索只是顺便提供的功能,
而搜索引擎,首先是搜索,但是不把数据存下来就搜不了,所以只好存一存。
术业有专攻,专攻搜索的搜索引擎,必然会提供更强大的搜索能力。
ElasticSearch 的 优势
- 分布式的文件存储,每个字段都被索引且可用于搜索。
- 分布式的实时分析搜索引擎,海量数据下近实时秒级响应。
- 简单的restful api,天生的兼容多语言开发。
- 易扩展,处理PB级结构化或非结构化数据。(pb指petabyte,1PB=1024TB)
二、部署ES
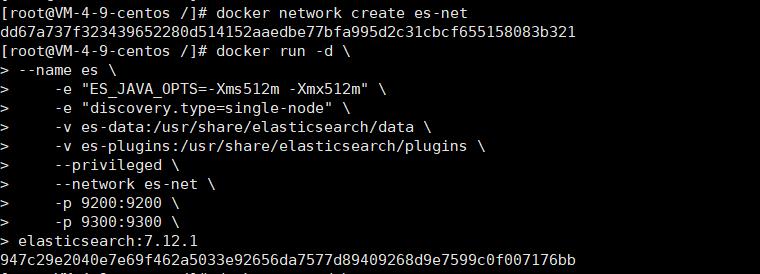
本案例通过云服务器 Docker 容器来进行部署 单点ES
创建Docker 网络
因为我们需要部署kibana容器,需要让es和kibana容器互联。这里先创建一个网络:
docker network create es-net
我们采用 ES 7.12.1 版本
安装 ES 镜像并运行
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
命令解释:
-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录--privileged:授予逻辑卷访问权--network es-net:加入一个名为es-net的网络中-p 9200:9200:端口映射配置
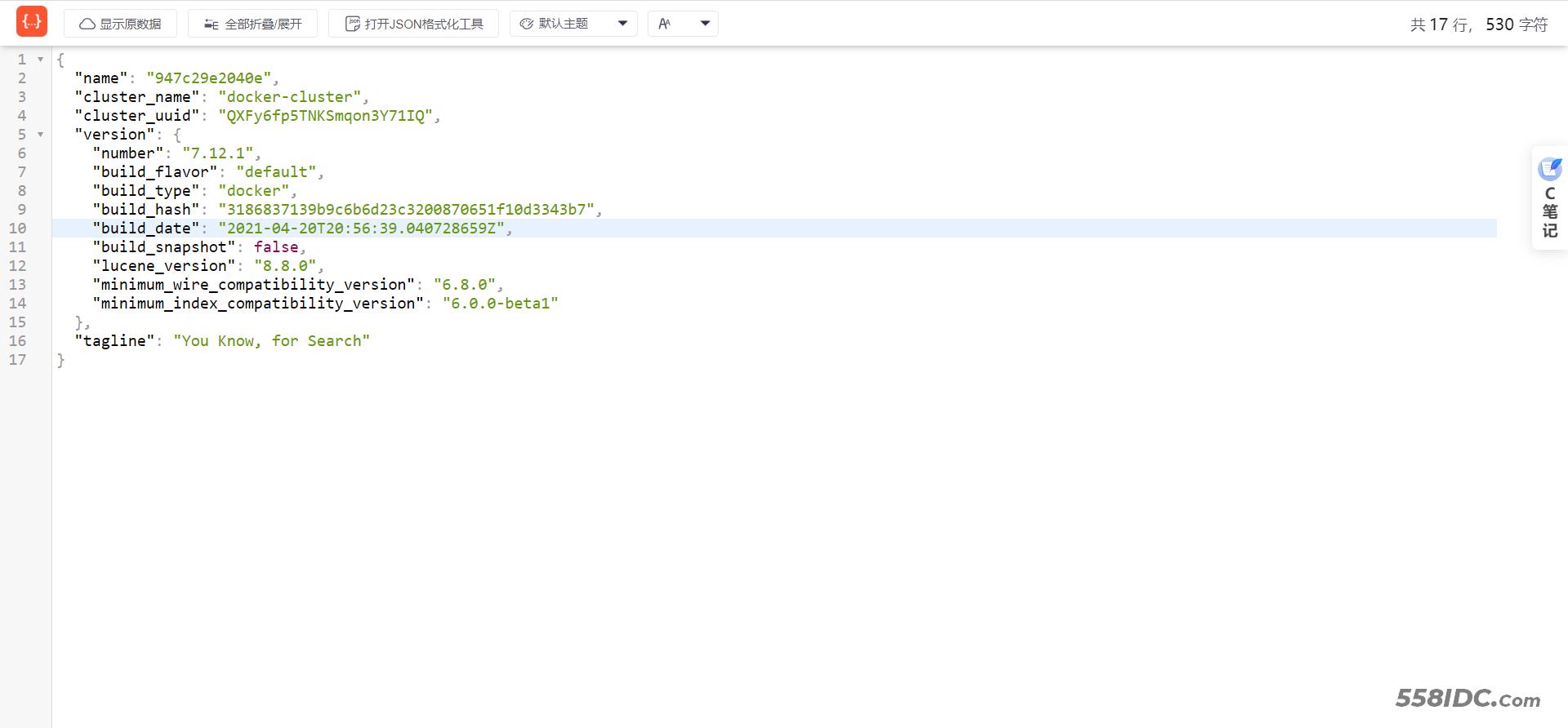
云服务器进行测试
我用的是腾讯云,所以需要 设置 腾讯云开放规则端口

输入ip地址+端口号 进行测试
http://ip地址:9200
⛅部署kibana
kibana是Elastic Stack 的技术栈,kibana为我们提供了一个可视化的界面,因此我们需要 部署kibana。
运行Docker 命令,部署kibana
docker run -d \ --name kibana \ -e ELASTICSEARCH_HOSTS=http://es:9200 \ --network=es-net \ -p 5601:5601 \ kibana:7.12.1
--network es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch-p 5601:5601:端口映射配置

kibana 启动会比较慢,可以通过docker 命令来查看执行日志
docker logs -f kibana
测试kibana
腾讯云服务器开放端口

进行测试
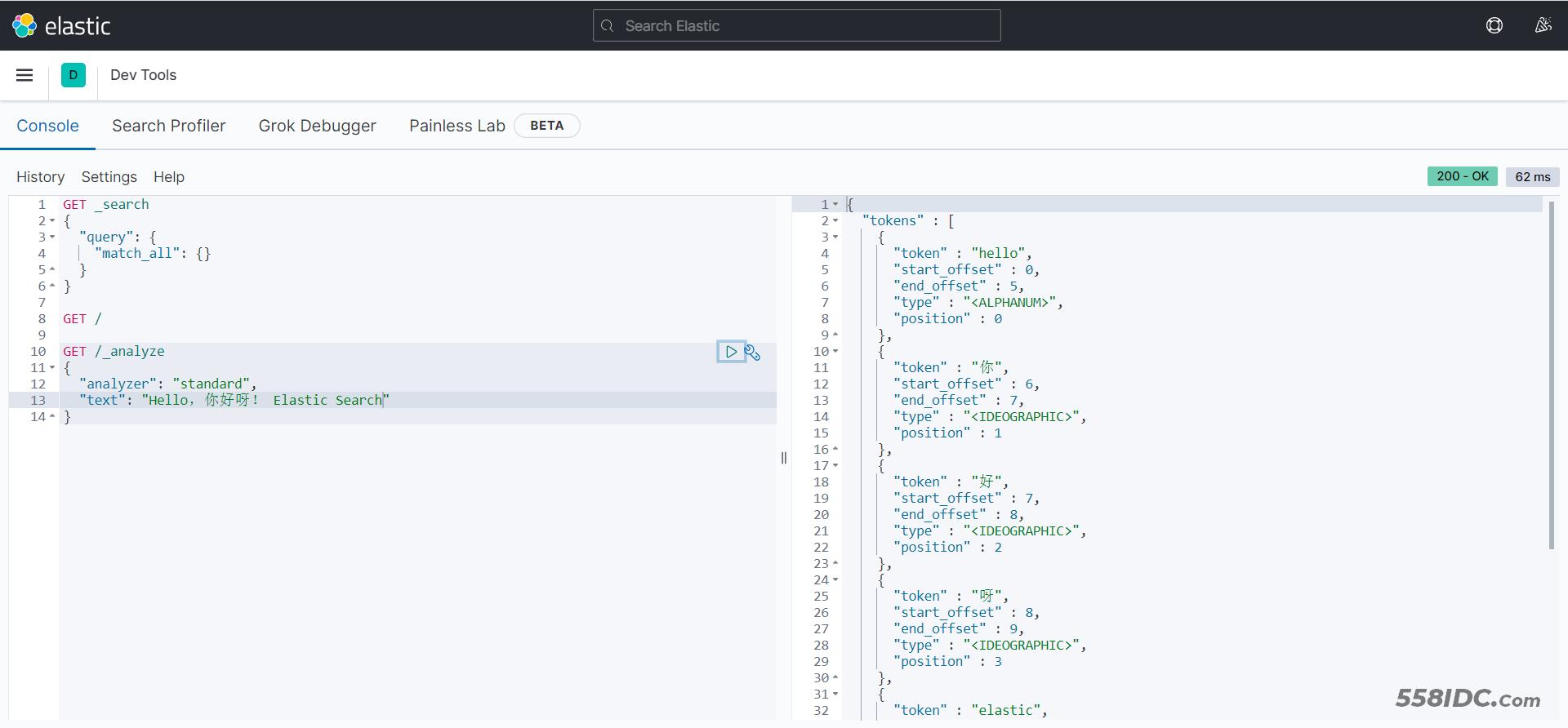
DevTools
kibana中提供了一个DevTools界面:
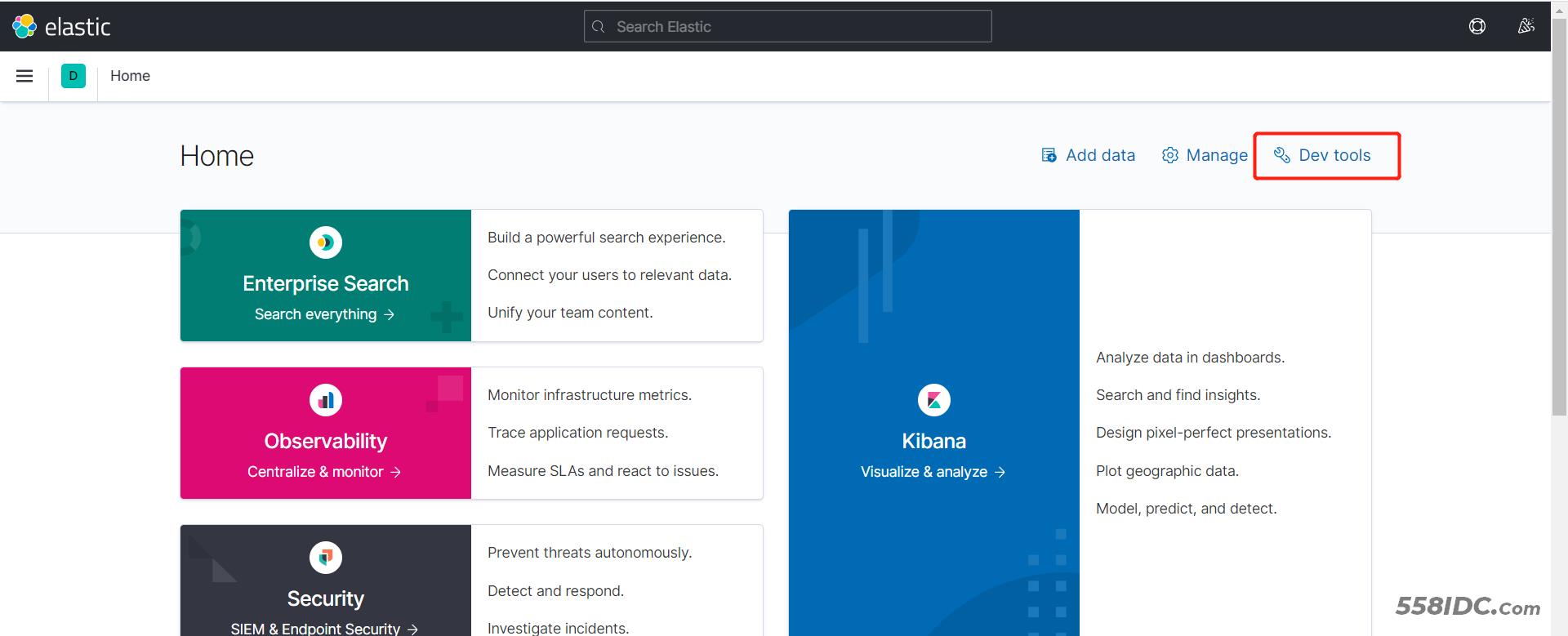
这个界面中可以编写DSL来操作elasticsearch。并且对DSL语句有自动补全功能。
测试DevTools
⚡部署分词器
离线安装分词器
由于在线安装比较慢,我就直接上传之前下载好的分词器到云服务器。
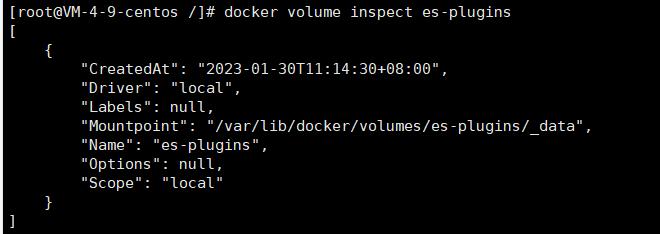
安装分词器需要知道 ElasticSearch 的 plugins 目录
通过docker命令查看挂载目录
docker volume inspect es-plugins
使用FileZilla上传ik分词器文件
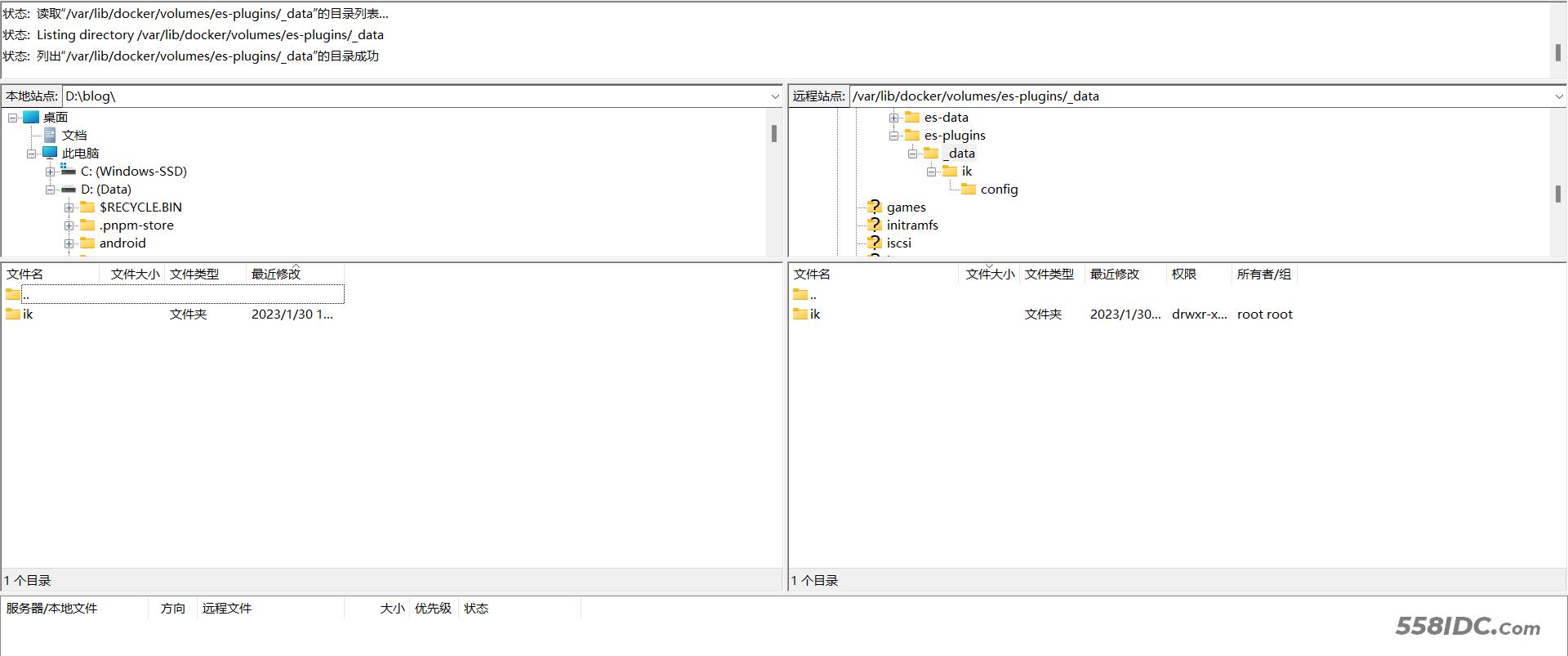
上传完成 重启生效
# 重启es docker restart es
进行测试
IK分词器包含两种模式:
ik_smart:最少切分ik_max_word:最细切分
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "你好,我是Bug 终结者"
}
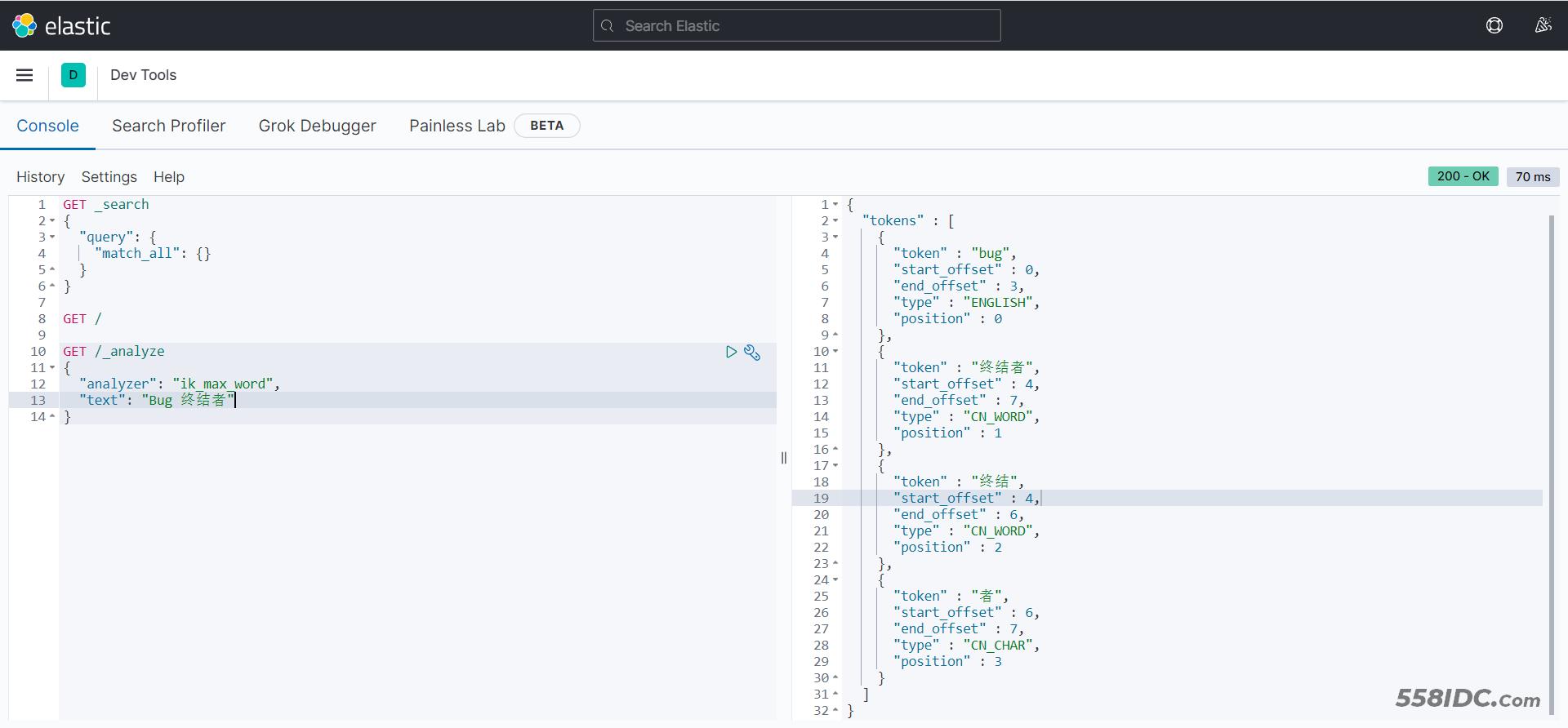
完成测试,但是我想要分出的词为Bug终结者,而不拆分,是一个词,该如何实现呢?
三、词典扩展与停用
⛅扩展词典
随着互联网的发展,“造词运动”也越发的频繁。出现了很多新的词语,在原有的词汇列表中并不存在。比如:“奥力给”,“传智播客” 等。
所以我们的词汇也需要不断的更新,IK分词器提供了扩展词汇的功能。
打开IK分词器 config 目录

在配置文件增加以下配置
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">ext.dic</entry> </properties>
新建 ext.dic 扩展字典文件
Bug 终结者
字节跳动
抖音集团
重启 es
# 重启服务 docker restart es
进行测试
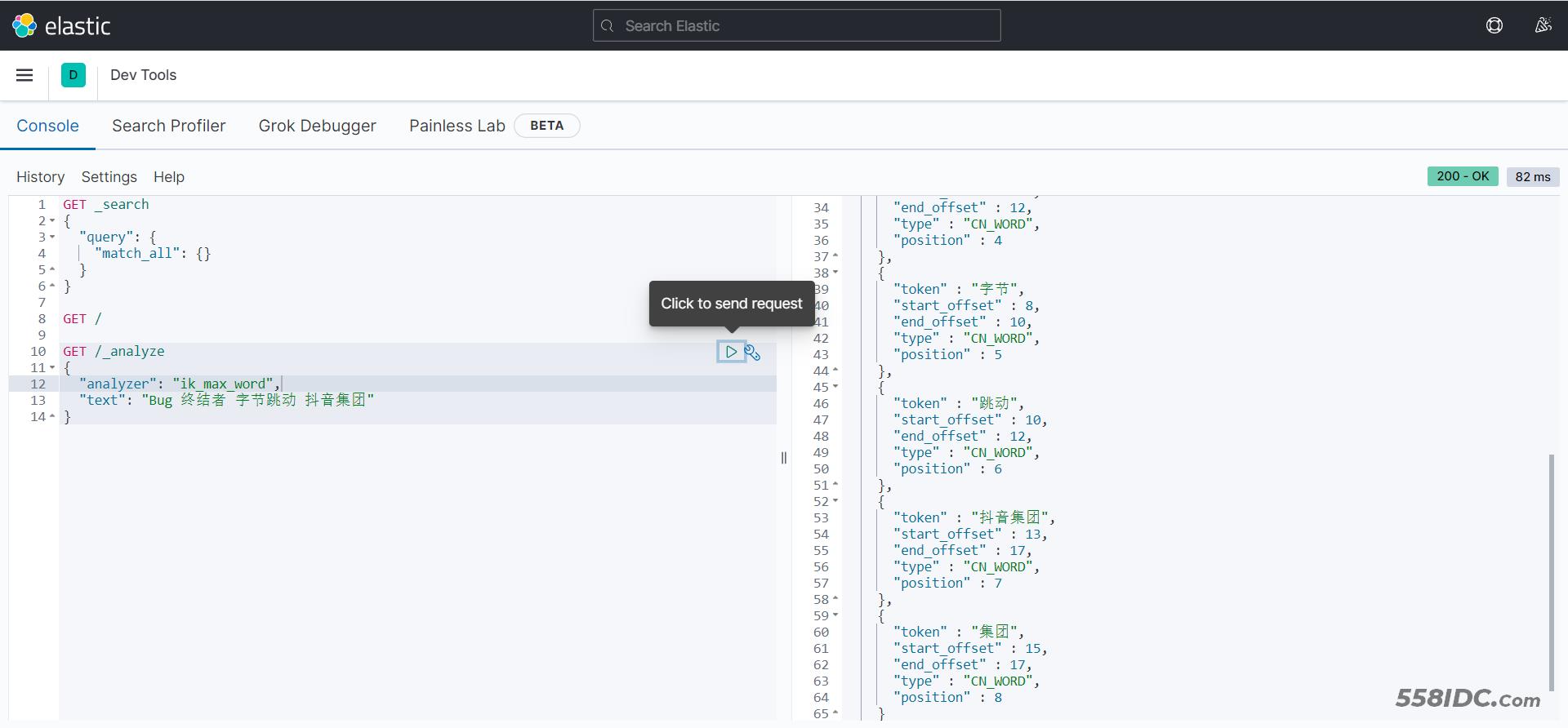
⚡停用词典
打开IK分词器 config 目录
图片10
在配置文件增加以下配置
图片13
新建 stopword.dic 扩展字典文件
的 啊 嗯 嘿 中
重启 es
# 重启服务 docker restart es docker restart kibana # 查看 日志 docker logs -f es

进行测试
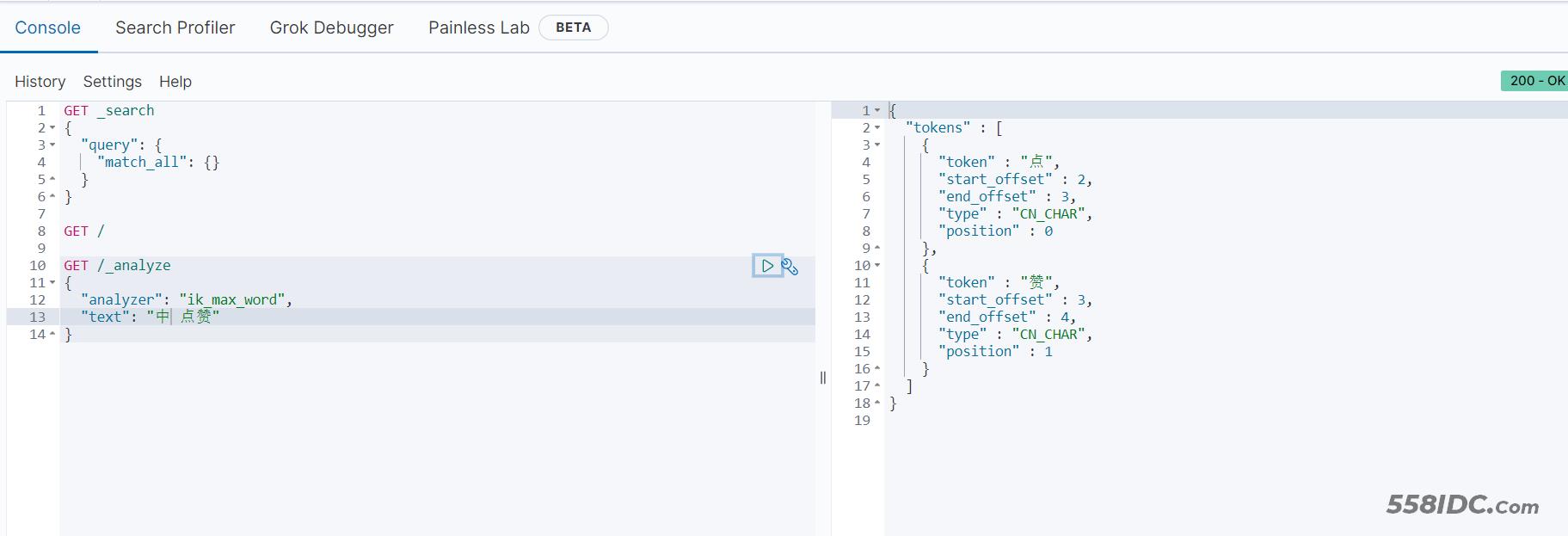
⛵小结
以上就是【Bug 终结者】对 Docker 部署 分布式搜索引擎 Elastic Search 的简单介绍,ES搜索引擎无疑是最优秀的分布式搜索引擎,使用它,可大大提高项目的灵活、高效性! 技术改变世界!!!
到此这篇关于Docker 部署 分布式搜索引擎 Elastic Search的文章就介绍到这了,更多相关分布式搜索引擎 Elastic Search内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!