(1)以这张表为例:
CREATE TABLE `test` ( `id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '注解id', `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '名字', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact; INSERT INTO test (id,`name`) VALUES (replace(uuid(),'-',''),'张三'),(replace(uuid(),'-',''),'张三');
表里有两条数据,然后名字是相同的,但是id是不同的,现在要求是只留一条数据:

(2)查询name值重复的数据:
现实开发当中可能一个字段无法锁定重复值,可以采取group by多个值!利用多个值来锁定重复的行数据!
SELECT name FROM test GROUP BY `name` HAVING count( name ) > 1
(3)查询重复数据里面每个最小的id:
SELECT min(id) as id FROM test GROUP BY `name` HAVING count( name ) > 1
(4)查询去掉重复数据最小id的其他数据:也就是要删除的数据!
SELECT * FROM test WHERE name IN ( SELECT name FROM test GROUP BY `name` HAVING count( name ) > 1 ) AND id NOT IN (SELECT min( id ) FROM test GROUP BY `name` HAVING count( NAME ) > 1)
(5)删除去掉重复数据最小id的其他数据:
可能这时候有人该说了,有了查询,直接改成delete不就可以了,真的是这样吗?其实不是的,如下运行报错:
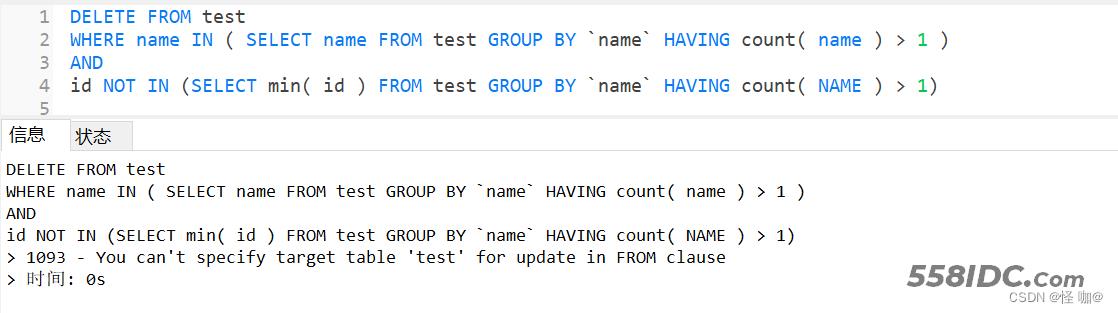
首先明确一点这个错误只会发生在delete语句或者update语句,拿update来举例 : update A表 set A列 = (select B列 from A表); 这种写法就会报这个错误,原因:你又要修改A表,然后又要从A表查数据,而且还是同层级。Mysql就会认为是语法错误!
嵌套一层就可以解决,update A表 set A列 = (select a.B列 from (select * from A表) a); 当然这个只是个示例,这个示例也存在一定的问题,比如(select a.B列 from (select * from A表) a)他会查出来多条,然后赋值的时候会报 1242 - Subquery returns more than 1 row。
嵌套一层他就可以和update撇清关系,会优先查括号里面的内容,查询结果出来过后会给存起来,类似临时表,可能有的人该好奇了,update A表 set A列 = (select B列 from A表); 我明明加括号了呀,难道不算嵌套吗,当然不算,那个括号根本没有解决他们之间的层次关系!
详解看这篇文章:https://www.jb51.net/article/274025.htm
(6)正确的写法:
方式一:
DELETE FROM test WHERE name IN ( select a.name from (SELECT name FROM test GROUP BY `name` HAVING count( name ) > 1) a) AND id NOT IN (select a.id from (SELECT min(id) as id FROM test GROUP BY `name` HAVING count( name ) > 1) a)
注意:删除之前一定要先查询,然后再删除,否则一旦语法有问题导致删了不想删除的数据,想要恢复很麻烦!或者删除前备份好数据,不要嫌麻烦,一旦出问题,才是真正的大麻烦!
方式二:
DELETE FROM test WHERE id NOT IN ( SELECT t.id FROM ( SELECT MIN(id) as id FROM test GROUP BY NAME ) t)
(7)错误的写法: 这块我吃过一次亏,所以专门写出来,避免踩坑!
千万千万不能这么搞,下面这个语法相当于是先按name分组,然后查出来大于1的,这时候假如大于1的有很多,然后外面嵌套的那一层,只取了最小的一条数据,然后再加上使用的是
NOT IN,最终会导致数据全部被删除!!!

执行前有四条数据,实际上我们要的是张三留下来一条,然后李四留下来一条
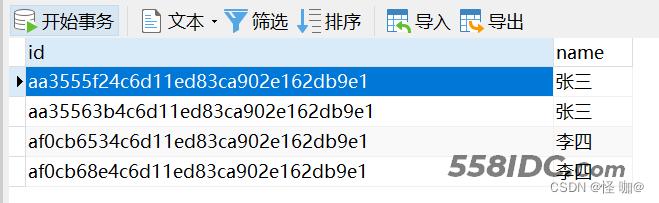
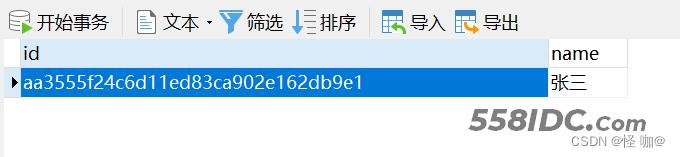
执行结果:只留下了一条!
总结
到此这篇关于Mysql删除重复数据并且只保留一条的文章就介绍到这了,更多相关Mysql删除重复数据只保留一条内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!