目录
- 前言
- 本次爬虫思路
- urllib库
- 1.urllib库的介绍
- 2.urllib库的使用模板
- 3.使用urllib库获取数据
- 4.urllib库一些个人总结
- requests库
- 5.requests库的介绍
- 6.requests库的使用模板
- 7.使用requests库获取数据
- 8.requests库一些个人总结
- 9.个人建议(附代码)
前言
大家在日常生活中经常需要查找不同的事物的相关信息,今天我们利用python来实现这一个小功能,同时呢,也是大家对基础知识的一个综合实践,相信有不少小伙伴已经准备跃跃欲试了,话不多说,开干!
本次爬虫思路
- 获取url
- 通过请求拿到响应
- 处理反爬
- 修改传递参数
- 完善程序
urllib库
1.urllib库的介绍
urllib库是Python的标准库,提供了一系列用于操作URL的功能,其大部分功能与requests库类似,也有一些特别的用法。
urllib库是Python标准库提供的一个用户操作URL的模块,Python3把原来Python 2的urilib库和Urllib 2库合并成了一个Urllib库,现在讲解的就是Python3中的Urllib库。
urllib.request——打开和读取URL;
urllib.error——包含Urllib.request各种错误的模块;
urlib.parse——解析URL;
urllib.robotparse——解析网站robots.txt文件。
2.urllib库的使用模板
import urllib.request url ='xxxxxxxxxxxx' #发送请求 request= urllib.request.Request(url,data,header) #得到响应 response=urllib.request.urlopen(request) #解码 content = response.read().decode() #查看数据 print(content)
3.使用urllib库获取数据
1. 获取URL:首先使用Chrome浏览器打开某度网页,随便输入一个:xxx,然后打开开发者工具(右键检查),切换到网络界面,清空记录,重新刷新页面,可以看到:
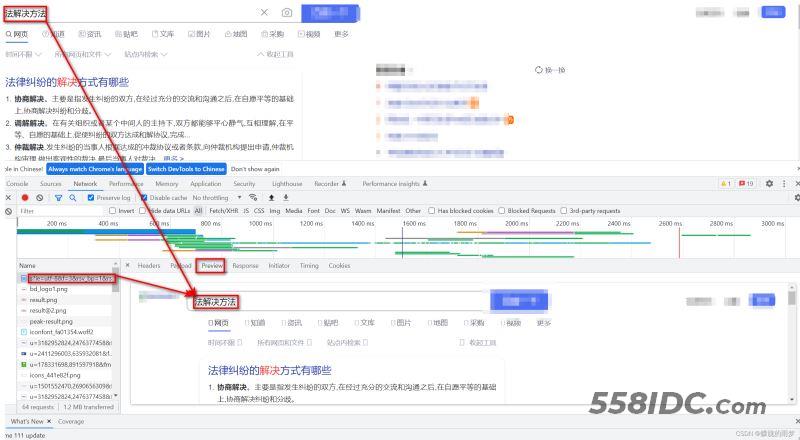
如此这个URL就是我们需要获取的URL:https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=%E6%B3%95%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95&fenlei=256&rsv_pq=0x8dc81b9f001c02d3&rsv_t=1c35crTFwJXLFoeU8nF33RDMyj9nX%2FofGDNqUmHapdGRlUDmKmo7610WDRno****&rqlang=en&rsv_dl=tb&rsv_sug3=7&rsv_enter=0&rsv_btype=i&inputT=2267&rsv_sug4=2878
分析:加粗的这一堆:就是法解决方法这几个关键字;
2.通过请求拿到响应:直接利用模板模拟浏览器发起请求:
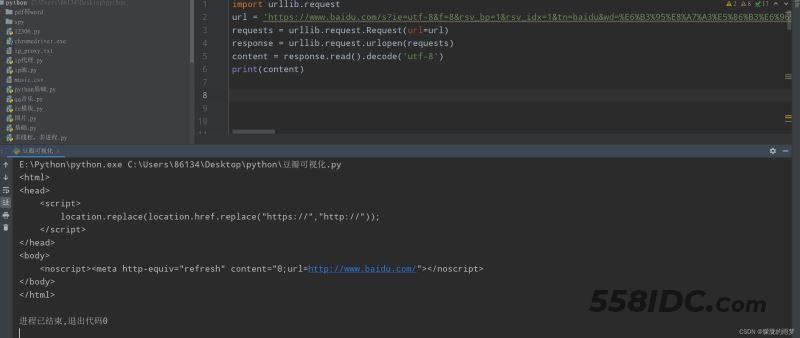
突然发现我们没有拿到想要的数据。难道是我们程序写错了吗?
3. 处理反爬:莫急,俗话说人靠衣服马靠鞍,服务器就像大美女,你要打扮的帅帅的,才能获得美女的芳心,当然,这种方法是对于我们人来说的,你可别马上就给电脑喷香水啊,针对程序来说,我们就需要伪装,假装我是一个浏览器,那么,如何伪装呢?我们就需要携带一些参数,先试试这个:
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36(主要是我们电脑浏览器的名称,版本信息),再试一次:
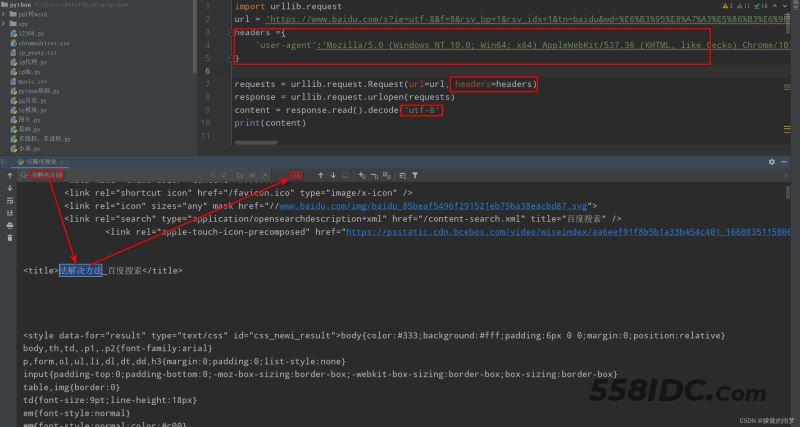
成功“骗”过了服务器,这样就拿到了数据(高兴