目录
- 索引的分类
- 聚簇索引
- 非聚簇索引
- 实战理解
我们都知道MySQL的辅助索引可以提升检索效率,但是为什么有的时候,走辅助索引反而不如走主键索引的效率高呢?这里我觉得需要先弄懂辅助索引的底层原理以及回表查询的概念。
ps:下边我们讨论的场景主要是针对innodb存储引擎为前提。
索引的分类
在我们给MySQL表建立索引的时候,一共有两种,分别是聚簇索引,非聚簇索引。
聚簇索引
聚簇索引会将索引和对应的行记录数据内容都统一存放在同一个叶子节点中。例如下图所示:
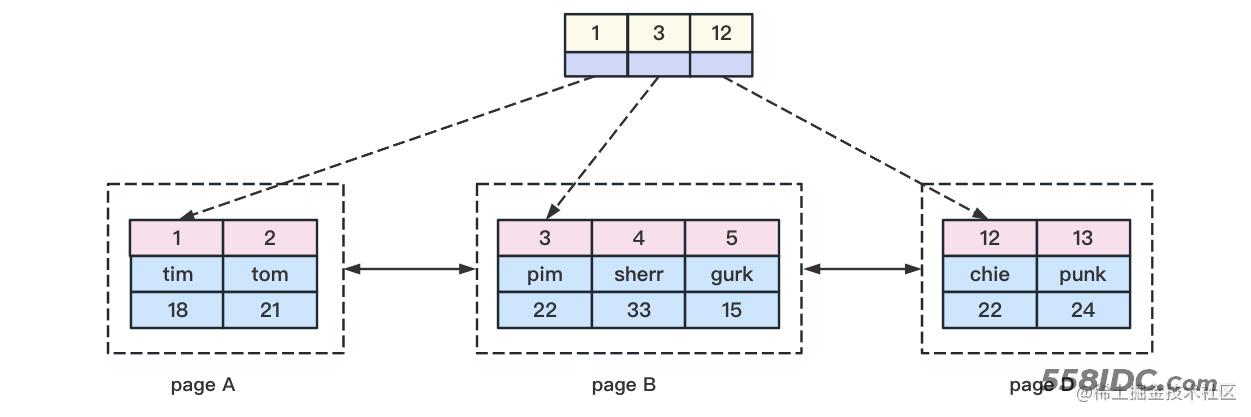
从上图中我们可以看到,最上头是非叶子结点,这种非叶子结点里面存储的是主键id的值,而非叶子结点的内部会有个数据页的指针,这些指针会指向下层的B+树节点,一般B+树的最底层我们称之为叶子结点。在聚簇索引的叶子结点里面,会存储主键id和对应的行记录内容。
非聚簇索引
非聚簇索引的结构如下所示:
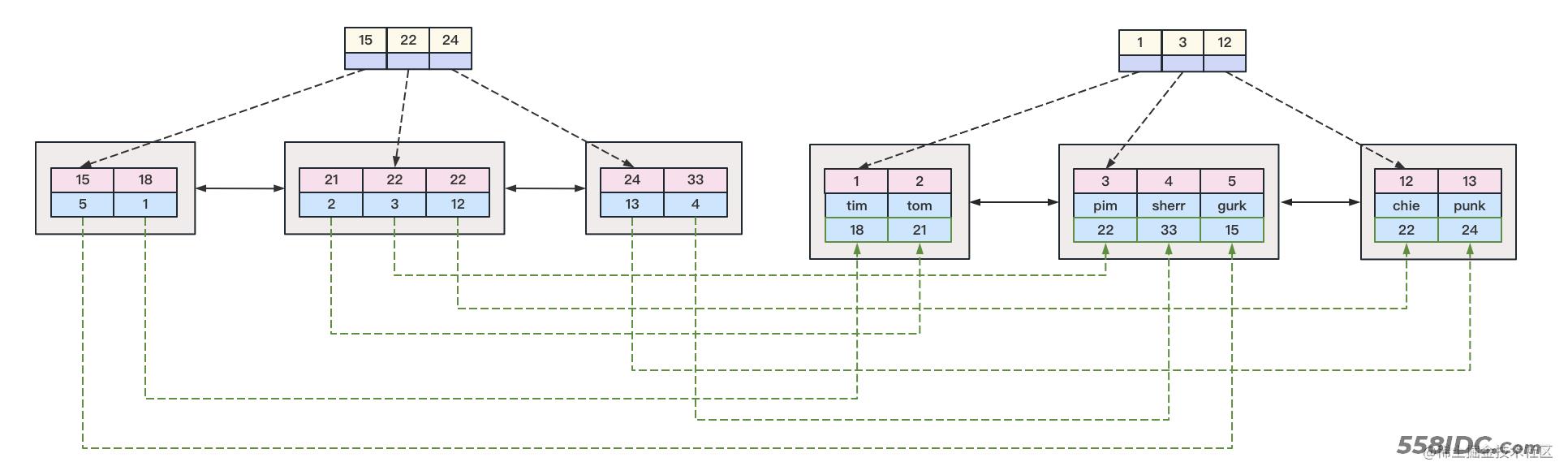
可以看到,在非聚簇索引中,所有的叶子结点都包含了辅助索引的值和主键的值。而当我们要根据辅助索引查询的时候,最终就会通过使用辅助索引定位到具体的叶子结点,最后根据叶子节点里面的主键id去聚簇索引的b+树中检索具体的行记录。
下边我们通过一组代码案例来深入了解下回表的知识点。
实战理解
首先需要创建一张表用于做测试:
CREATE TABLE `t_common` ( `a` int unsigned NOT NULL AUTO_INCREMENT, `b` int DEFAULT NULL, `c` int DEFAULT NULL, `d` int DEFAULT NULL, PRIMARY KEY (`a`), KEY `ud_b_c` (`b`,`c`) ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb3;
然后我们插入一些测试数据:
INSERT INTO `t_common` (`a`, `b`, `c`, `d`) VALUES (1, 1, 1, 1), (2, 2, 2, 2);
接着我们来看看下边的几个sql案例:
1.全表扫描
select a,b,c,d from t_common;
explain结果如下:

可以看到这条sql需要从mysql中检索出a,b,c,d四个字段,走的是全表扫描,并没有走索引。
2.按照c关键字查询
select a,b,c,d from t_common where c=1;
explain结果如下:

可以看到,这里也是走了全表扫描。
3.按照b关键字查询
select a,b,c,d from t_common where c=1;
explain结果如下:

可以看到,结果是走了b,c联合索引。这里的结果也应证了最左匹配原则的说法。但是这里因为查询出来的d字段不在bc索引树上,因此需要回表。
4.按照c关键字查询,只返回b,c字段
select b,c from t_common where c=1;
explain结果如下:

这种情况有点特殊,按理说他是不满足最左匹配原则的,但是由于检索的内容正好是辅助索引的字段,同时扫描辅助索引的IO开销要比扫描主键索引的IO开销小,所以这里的查询对辅助索引树进行了全表扫描。
(开销更小的原因是:因为主键索引存储的是行记录,加载的数据更多。走普通索引的时候,叶子节点存储的是主键id值,这样一次加载的数据会更多,走普通索引效率比主键索引要高。)
5.按照c关键字查询,返回a,b,c字段
select a,b,c from t_common where c=1;
explain结果如下:

这种情况和上边的情况相同,由于c的查询不满足最左匹配原则,原先是不不应该走b,c索引的,但是后期优化器发现,需要查询的字段正好是辅助索引的字段内容,而扫描辅助索引的IO开销要比扫描主键索引的IO开销小,所以这里的查询对辅助索引树进行了全表扫描。
(开销更小的原因是:因为主键索引存储的是行记录,加载的数据更多。走普通索引的时候,叶子节点存储的是主键id值,这样一次加载的数据会更多,走普通索引效率比主键索引要高。)
6.按照b关键字进行查询,查询a,b,c,是否有回表
select a,b,c from t_common where b=1;
explain结果如下:

这种情况下,要注意,由于我们的bc索引的叶子结点包含了主键的值,所以其实减少了回表查询的情况。但是如果我们看回上边所说的第三种情况,第三种查询其实还需要通过一次回表的操作,去查询d的值。
7.如果查询的字段包含了主键索引和辅助索引,优先走辅助索引
select a,b,c from t_common;
explain结果:

因为主键索引存储的是行记录,加载的数据更多。走普通索引的时候,叶子节点存储的是主键id值,这样一次加载的数据会更多,走普通索引效率比主键索引要高。所以这条sql直接扫描了整个b,c联合索引树。
到此这篇关于MySQL索引查询的具体使用的文章就介绍到这了,更多相关MySQL索引查询内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!