目录 Join的类型 Join原理 Simpe Nested-Loop Join Index Nested-Loop Join Block Nested-Loop Join Join优化 Join的类型 left join,以左表为驱动表,以左表作为结果集基础,连接右表的数据补齐到结果集中 ri
目录
- Join的类型
- Join原理
- Simpe Nested-Loop Join
- Index Nested-Loop Join
- Block Nested-Loop Join
- Join优化
Join的类型
- left join,以左表为驱动表,以左表作为结果集基础,连接右表的数据补齐到结果集中
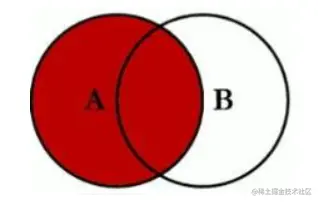
- right join,以右表为驱动表,以右表作为结果集基础,连接左表的数据补齐到结果集中
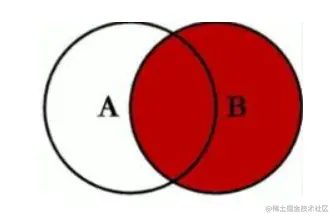
- inner join,结果集取两个表的交集
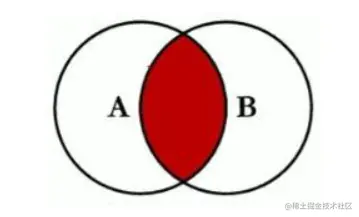
- full join,结果集取两个表的并集
mysql没有full join,union取代
union与union all的区别为,union会去重
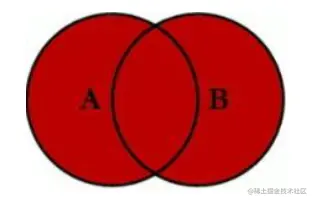
- cross join 笛卡尔积
如果不使用where条件则结果集为两个关联表行的乘积
与,的区别为,cross join建立结果集时会根据on条件过滤结果集合
- straight_join
严格根据SQL顺序指定驱动表,左表是驱动
Join原理
本质上可以理解为嵌套循环的操作,驱动表作为外层for循环,被驱动表作为内层for循环。根据连接组成数据的策略可以分为三种算法。
Simpe Nested-Loop Join
- 连接比如有A表,B表,两个表JOIN的话会拿着A表的连表条件一条一条在B表循环,匹配A表和B表相同的id 放入结果集,这种效率是最低的。
Index Nested-Loop Join
- 执行流程(磁盘扫描)
从表t1中读入一行数据 R;
从数据行R中,取出a字段到表t2里进行树搜索查找;
取出表t2中满足条件的行,跟R组成一行,作为结果集的一部分;
重复执行步骤1到3,直到表t1的末尾循环结束。
- 而对于每一行R,根据a字段去表t2查找,走的是树搜索过程。
Block Nested-Loop Join
- mysql使用了一个叫join buffer的缓冲区去减少循环次数,这个缓冲区默认是256KB,可以通过命令show variables like 'join_%'查看
- 其具体的做法是,将第一表中符合条件的列一次性查询到缓冲区中,然后遍历一次第二个表,并逐一和缓冲区的所有值比较,将比较结果加入结果集中
- 只有当JOIN类型为ALL,index,rang或者是index_merge的时候才会使用join buffer,可以通过explain查看SQL的查询类型。
Join优化
- 为了优化join算法采用Index nested-loop join算法,在连接字段上建立索引字段
- 使用数据量小的表去驱动数据量大的表
- 增大join buffer size的大小(一次缓存的数据越多,那么外层表循环的次数就越少)
- 注意连接字段的隐式转换与字符编码,避免索引失效
到此这篇关于一文详解MySQL Join使用原理的文章就介绍到这了,更多相关MySQL Join原理内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!