详细任务步骤
任务1Hadoop 心跳机制
1.1 心跳机制简介
现在有这样一个应用场景
在长连接下有可能很长一段时间都没有数据往来。理论上说这个连接是一直保持连接的但是实际情况中如果中间节点出现什么故障是难以知道的。更要命的是有的节点防火墙会自动把一定时间之内没有数据交互的连接给断掉。在这个时候就需要我们的心跳包了用于维持长连接。
那么什么是心跳机制呢
心跳机制就是每隔几分钟发送一个固定信息给服务端服务端收到后回复一个固定信息如果服务端几分钟内没有收到客户端信息则视客户端断开。
发包方可以是客户也可以是服务端看哪边实现方便合理。
心跳包之所以叫心跳包是因为它像心跳一样每隔固定时间发一次以此来告诉服务器这个客户端还活着。事实上这是为了保持长连接至于这个包的内容是没有什么特别规定的不过一般都是很小的包或者只包含包头的一个空包。心跳包主要也就是用于长连接的保活和断线处理。一般的应用下判定时间在30-40秒比较不错如果实在要求高可以设置在6-9秒之间。
Hadoop心跳机制解析
- Hadoop 集群是 Master/Slave 结构 Master 中有 NameNode 和 ResourceManager Slave 中有 Datanode 和 NodeManager
- Master 启动的时候会启动一个 IPCInter-Process Comunication进程间通信 Server 服务等待 Slave 的链接
- Slave 启动时会主动链接 Master 的 IPC Server 服务并且每隔 3 秒链接一次 Master这个间隔时间是可以调整的参数为 dfs.heartbeat.interval这个每隔一段时间去链接一次的机制我们形象地称为心跳。
- Slave 通过心跳汇报自己的信息给 Master Master 也通过心跳给 Slave 下达命令 NameNode 通过心跳得知 DataNode 的状态ResourceManager 通过心跳得知 NodeManager 的状态
- 如果 Master 长时间都没有收到 Slave 的心跳就认为该 Slave 挂掉了
1.2 心跳机制配置
NameNode 感知到 DataNode 掉线死亡的时长计算
HDFS 默认的超时时间为 10 分钟30 秒这里暂且定义超时时间为 timeout。 计算公式为
timeout 2*dfs.namenode.heartbeat.recheck-interval10*dfs.heartbeat.interval
- dfs.namenode.heartbeat.recheck-interval重新检查时长默认为 5 分钟
- dfs.heartbeat.intervalDataNode的心跳检测间隔时间默认的大小为 3 秒
我们可以查看一下 Hadoop 当前版本的 hdfs-default.xml 配置项
参数名值描述dfs.namenode.heartbeat.recheck-interval300000This time decides the interval to check for expired datanodes. With this value and dfs.heartbeat.interval, the interval of deciding the datanode is stale or not is also calculated. The unit of this configuration is millisecond.dfs.heartbeat.interval3Determines datanode heartbeat interval in seconds.需要注意的是 hdfs-default.xml 配置文件中的 dfs.namenode.heartbeat.recheck-interval 的单位为毫秒dfs.heartbeat.interval 的单位为秒。
示例如果 dfs.namenode.heartbeat.recheck-interval 设置为 15000毫秒 dfs.heartbeat.interval 设置为 3秒则总的超时时间为 60 秒。
可以在 hdfs-site.xml 配置文件中配置这两个参数进行验证
dfs.namenode.heartbeat.recheck-interval 15000 dfs.heartbeat.interval 3
注意在修改配置文件之前需要将 Hadoop 集群关闭修改完成再重启 Hadoop 集群此时修改的配置文件才会生效。
重启 HDFS 集群后此时我们关闭本机上的 DataNode 进程进行验证。关闭的命令如下
kill -9 pid
解析
- kill pid正常停止进程并释放进程所占用的资源
- kill -9:表示强制杀死该进程
在本机上执行以上命令效果如下所示
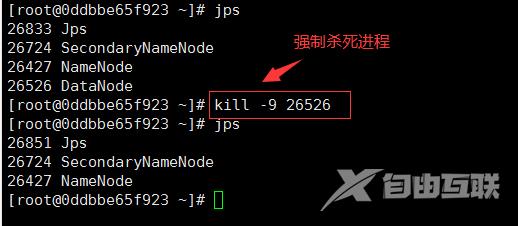
图1
通过宿主机的浏览器访问 http://localhost:50070 进入 HDFS Web UI 界面选择“Datanodes”选项查看 DataNode 列表信息不断刷新发现 Last contact 的值不断增大

图2
因为我们设置的总的超时时间为 60 秒所以 NameNode 在连续 60 秒中没有得到 DataNode 的信息才会认为当前的 DtaNode 宕机

图3
任务2垃圾回收机制
何为垃圾回收
即开启垃圾回收站把删除的文件首先放置在回收站中等待配置的时间结束进行真正的数据删除。
默认情况下HDFS 的垃圾回收机制是没有开启的但是 HDFS 是可以开启垃圾回收机制的。
启动 HDFS 上的垃圾回收机制只需要配置两个参数
-
第一个参数fs.trash.interval表示检查点被删除之前的分钟数默认为0单位为分钟。如果为0则表示禁用垃圾回收功能。这里我们可以设置为1440分钟即1天保留在垃圾回收站的文件或文件夹超过1天后会自动删除。在生产上的 HDFS 垃圾回收机制是必须开启的一般设置成7天或者14天设置更长。
-
第二个参数fs.trash.checkpoint.interval表示垃圾检查点之间的分钟数默认为 0单位为分钟。该值应该小于或等于 fs.trash.interval如果为 0则将该值设置为 fs.trash.interval 的值所以生产上我们直接设置为 0。每次检查点运行时它都会创建一个新的检查点并删除超过 fs.trash.interval 分钟前创建的检查点。
HDFS 垃圾回收机制配置
我们需要在配置文件 core-site.xml 中设置回收机制
fs.trash.interval1440fs.trash.checkpoint.interval0
注意在修改配置文件之前需要将 Hadoop 集群关闭修改完成再重启 Hadoop 集群此时修改的配置文件才会生效。
重启集群后试着删除 HDFS 集群上的一些文件进行测试
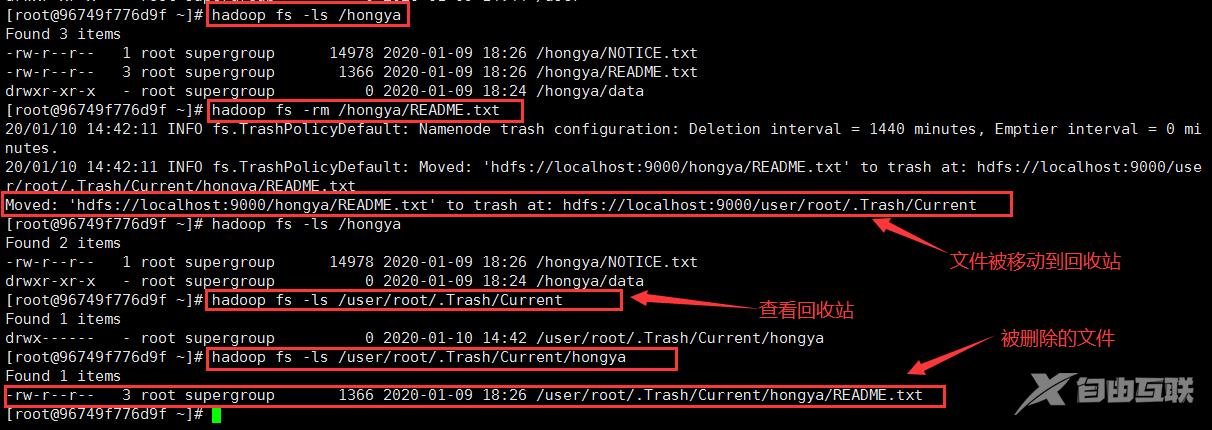
图4
从上图中可以看出删除的文件已被移动到垃圾回收站里面默认的地址为 “/user/搭建集群的用户名/.Trash/ ”。若是想要恢复文件直接使用 cp 或者 mv 命令即可。

图5
存放在垃圾回收站的文件一旦超过了设置的时间就会自动删除