前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
大家爬取分析XX点评数据,最常见的无非两种:
1、分析所有店铺的各类评分和推荐菜等
2、获得店铺里的评论数据
而大众点评最大的难题就是字体加密,也就是这样
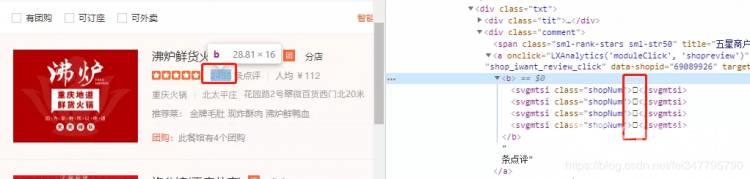
很明显点评网宁可错杀一万,也不肯放过一个,干脆使用了自己定义的字体。不过既然自定义了字体,那么网页肯定需要加载字体文件。
谷歌浏览器,右键检查,进入network 然后刷新页面,点击Font。
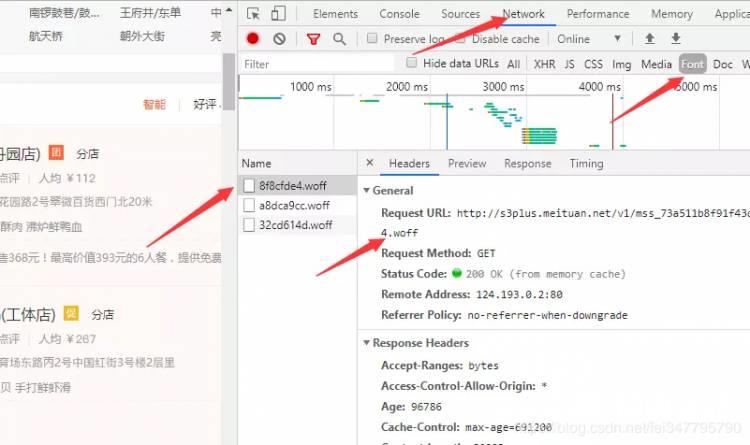
我们来下载这个加载的字体:8f8cfde4.woff
右键 copy like address
粘贴到新页面 即可下载
将下载的字体导入FontEditor中打开
(百度家的在线字体编辑器)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JWVkemcp-1577367359320)(https://upload-images.jianshu.io/upload_images/20547410-52be79f3b75690d1.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240 “点击进入看图评论”)]
导入之后:
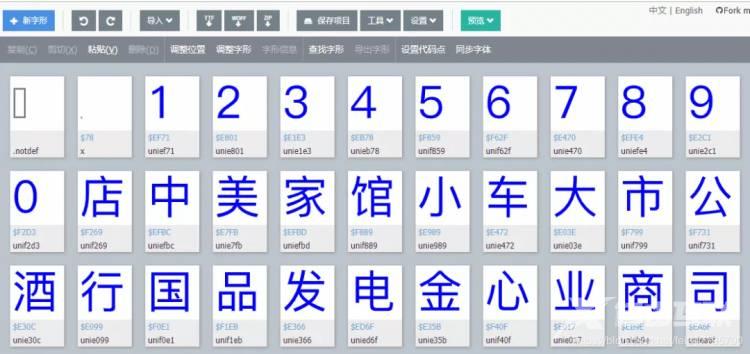
我们再结合网页源代码,就得到了相应乱码与数字的对应关系:
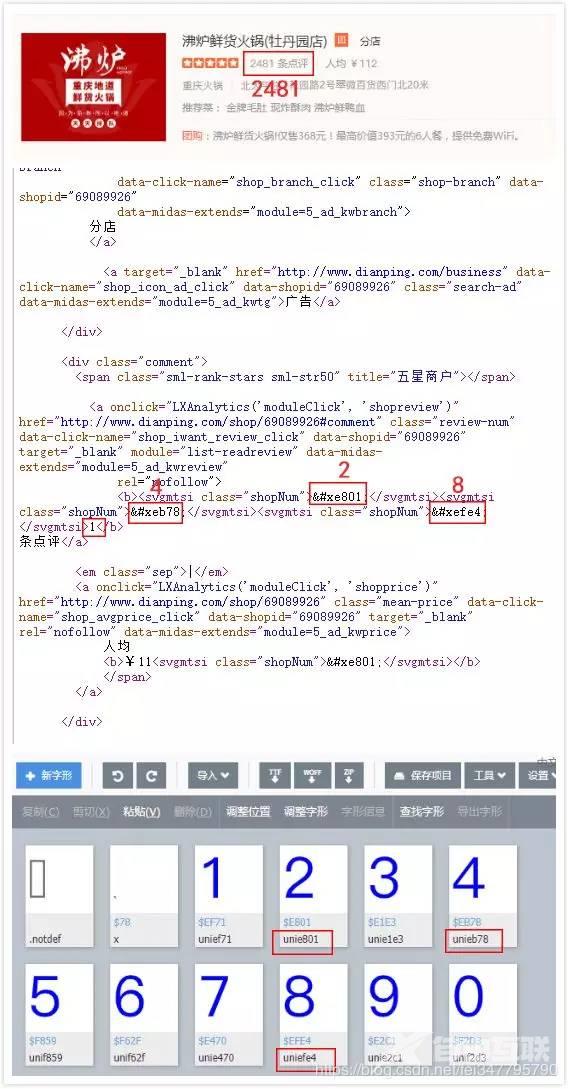
我们可以发现网页中的乱码和FontEditor中的乱码后四位是一样的,比如说图中某店铺的点评数为2481,在网页源代码用【1】来表示,这在FontEditor的字体编辑器中对应的是【unie801,unieb78,uniefe4】。
所以我们要做的是:
1、下载网站font字体包
2、将font字体包中导入FontEditor 观察得到乱码与数字的关系
3、前缀替换,并将字体名字和它们所对应的乱码构成一个字典
def get_font():
fOnt= TTFont(‘8f8cfde4.woff’)
font_names = font.getGlyphOrder()
这些文字就是在FontEditor软件打开字体文件后看到的文字名字
texts = [’’,’’,‘1’,‘2’,‘3’,‘4’,‘5’,‘6’,‘7’,‘8’,‘9’,‘0’]
font_name = {}
将字体名字和它们所对应的乱码构成一个字典
for index,value in enumerate(texts):
a = font_names[index].replace(‘uni’, ‘”
font_name[a] = value
return font_name
运行看一下:
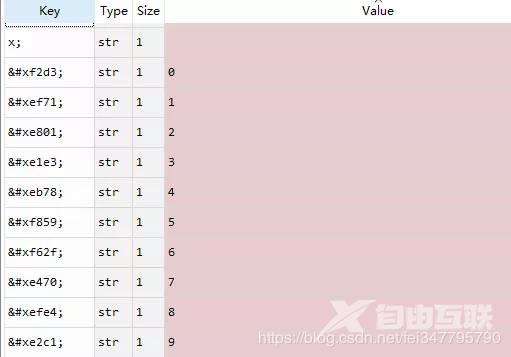
没错,跟刚才观察的结果一致。
那么下面我们获取网页源代码,并根据刚才 get_font()构成的字典进行替换。
import requests
headers = {‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36’}
COOKIEs = {‘COOKIE’:‘你的COOKIEs’}
url = ‘http://www.dianping.com/beijing/ch10/g110p1’
html = requests.get(url, headers=headers,COOKIEs = COOKIEs).text
#requests获得html
num = get_font()
#获得加密映射关系
for key in num:
if key in html:
html = html.replace(key, str(num[key]))
#替换html中加密文字
再看一下结果:

这样就破解了点评网的字体加密。
对Python感兴趣或者是正在学习的小伙伴,可以加入我们的Python学习扣qun:855408893 ,从0基础的python脚本到web开发、爬虫、django、数据挖掘数据分析等,0基础到项目实战的资料都有整理。送给每一位python的小伙伴!每晚分享一些学习的方法和需要注意的小细节,学习路线规划,利用编程赚外快。点击加入我们的 python学习圈
剩下各位就可以自行用喜欢的解析方式来解析html啦。