1.Nosql的适用场景1.1少量数据存储,高速读写访问.通过将数据in-memory来保证高速的访问.通常采用Redis来做高速缓存.1.2分布式下的海量数据存储,保证数据一致性 1. Nosql 的适用场景 1.1 少量数
1. Nosql 的适用场景
1.1 少量数据存储, 高速读写访问.
- 通过将数据in-memory 来保证高速的访问.
- 通常采用Redis 来做高速缓存.
1.2 分布式下的海量数据存储, 保证数据一致性.
- 同时需要做到方便地添加/删除节点.
- dynamo : 完全无中心.
- 节点间通过gossip 方式传递集群信息.
- 保证数据的最终一致性.
- bigtable 2: 中心化设计.
- 通过分布式锁来保证强一致性.
- 流程: 数据先写入内存和redo log, 然后定期归并到硬盘上.
- 优势: 将随机写优化为顺序写.
1.3 优势: Schema free, auto-sharding.
- NoSQL 能够更好地对应由于业务变更而导致的schema 变更.
2. MemCached 的适用场景
2.1 少量的静态数据.
- 如HTML 代码片段.
2.2 String 是唯一支持的数据类型.
- 所以消耗的内存资源更少.
2.3 可读数据的存储.
- 由于String 并不需要进一步的处理.
2.4 更易于横向扩展.
- 由于存储的都是相互独立的string 值.
3. Memcached 的Slab Allocation 机制
3.1 旧的方式
- 对所有记录简单地进行malloc/free 来进行内存分配.
- 缺陷: 导致内存碎片; 加重OS 内存管理的负担.
3.2 Slab 机制
- 相当于内存池
- 从OS 分配一大块内存, 然后memcached 自己负责管理这块内存, 包括分配和回收.
3.3 Slab 基本原理
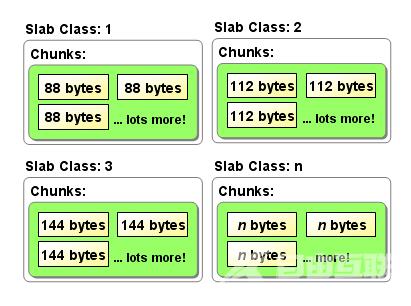
- Chunk
- 按照预先设定的尺寸, 将分配的内存分隔成各种大小的chunk, 以解决内存碎片.
- chunk 的尺寸按比例递增.
- 收到数据后, 选择合适的slab, 根据slab 内空闲chunk 列表来选择合适的chunk , 然后将数据存储到chunk 中.
缺陷 : 由于分配的是特定尺寸的内存, 无法保证有效利用.

4. Redis 的适用场景
4.1 处理过期项目.
- 使用time作为score.
4.2 计数.
- 利用其atomic increment 特性.
4.2 特定时间内的特定项目.
4.3 实时分析正在发生的情况.
- 例如用于数据统计与防止垃圾邮件等.
4.4 消息队列.
- 系统组件间通信,或系统跟其它服务间交互.
- 将系统中各组件解耦, 不再受最慢组件的约束.
- 各组件异步运行,以更块地完成各自的工作.