MapReduce
参考资料
https://www.jianshu.com/p/0f83097c0c9e
https://www.jianshu.com/p/9351f2514f75
https://www.jianshu.com/p/5564ee3c885c https://www.jianshu.com/p/db9210b6a493
https://www.jianshu.com/p/306745907fa9
现在无论前端还是后端都有很多地方提到了MapReduce。
那么什么是mapReduce
MapReduce是一种编程模型,"Map映射“和"Reduce归约”。适用于大数据下分布式并行计算
按照规定完成Map分发数据和Reduce处理数据两部分工作就可以快速得出结果。
想象一个场景
有一个篮球场一样大的果篮里面有苹果、香蕉、葡萄、圣女果等等。现在要统计出来各水果都有多少颗。如果果篮很小的时候一个人就可以处理一个一个数就可以但是篮球场这么大的果篮数据量较大远非一个人就可以处理的。
map - reduce就是为了处理这种问题的一个解决方案。
MapReduce主要分为2个任务: map reduce
Map任务
key/value 对作为输入产生另外一系列 key/value 对作为中间输出写入本地 磁盘。这些中间数据按照 key 值进行聚集且 key 值相同用户可 设定聚集策略默认情况下是对 key 值进行哈希取模的数据被统一交给 reduce() 函数处理。
对应到我们上面的场景就是把不同的水果都挑出来并且放在一起。这里面我们就是按照水果类型做为key进行水果的聚集。
Reduce任务
以 key 及对应的 value 列表作为输入经合并 key 相同的 value 值后产 生另外一系列 key/value 对作为最终输出
三个组件
-
InputFormat指定输入 文件格式。将输入数据切分成若干个 split且将每个 split 中的数据解析成一个个 map() 函数 要求的 key/value 对。
-
Partitioner确定 map() 函数产生的每个 key/value 对发给哪个 Reduce Task 函数处 理。
-
OutputFormat指定输出文件格式即每个 key/value 对以何种形式保存到输出文件中。
Map-Reduce 任务过程
-
数据分片过程input split数据分片存储的并非数据本身而是一个分片长度和一个记录数据的位置的数组。每个分片针对一个map任务。
-
map就是程序员编写好的map函数了因此map函数效率相对好控制而且一般map操作都是本地化操作也就是在数据存储节点上进行。
-
combiner 其实也是一种reduce操作,做可以做局部运算、去重等操作。Combiner是一个本地化的reduce操作它是map运算的后续操作主要是在map计算出中间文件前做一个简单的合并重复key值的操作。当然这个阶段不是一定会执行是可选的阶段
-
shuffle这个阶段是对map输出的大量数据排序这个对内存开销是很大的。map在做输出时候会在内存里开启一个环形内存缓冲区这个缓冲区专门用来输出的默认大小是100mb并且在配置文件里为这个缓冲区设定了一个阀值默认是0.80,同时map还会为输出操作启动一个守护线程如果缓冲区的内存达到了阀值的80%时候这个守护线程就会把内容写到磁盘上这个过程叫spill另外的20%内存可以继续写入要写进磁盘的数据写入磁盘和写入内存操作是互不干扰的如果缓存区被撑满了那么map就会阻塞写入内存的操作让写入磁盘操作完成后再继续执行写入内存操作。外部排序。
-
reduce输出最终结果。
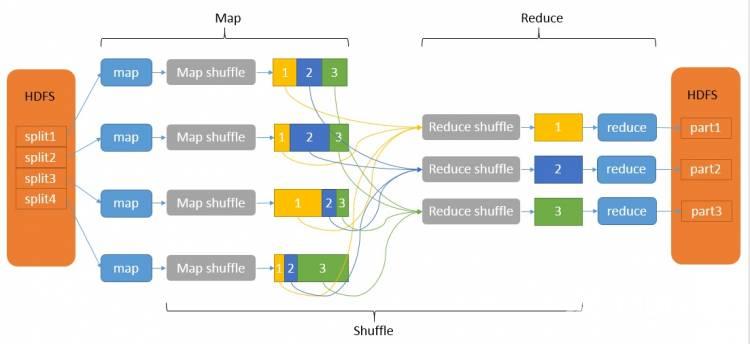
输入 --> map --> shuffle --> reduce -->输出
PartitionerCombinerShuffle分别位于哪个阶段中
-
Partitioner:数据分组 决定了Map task输出的每条数据交给哪个Reduce Task处理。默认实现hash(key) mod R R是Reduce Task数目允许用户自定义很多情况下需要自定义Partitioner 比如“hash(hostname(URL)) mod R”确保相同域名的网页交给同一个Reduce Task处理 属于map阶段。
-
Combiner可以看做local reduce 合并相同的key对应的value通常与reducer逻辑一样 好处是减少map task输出 数量磁盘IO见少Reduce-map网络传输数据量(I网络IO) 结果叠加属于map阶段。
-
ShuffleShuffle描述着数据从map task输出到reduce task输入的这段过程 (完整地从map task端拉取数据到reduce 端。在跨节点拉取数据时尽可能地减少对带宽的不必要消耗。减少磁盘IO对task执行的影响。 ) 属于(reduce)阶段。
下面的图片是参考资料里面的MapReduce工作原理原理