篇首语:本文由编程笔记#自由互联小编为大家整理,主要介绍了Elasticsearch 8.X 有哪些自动补全的检索方式?相关的知识,希望对你有一定的参考价值。
1、自动补全或前缀匹配检索实现效果图
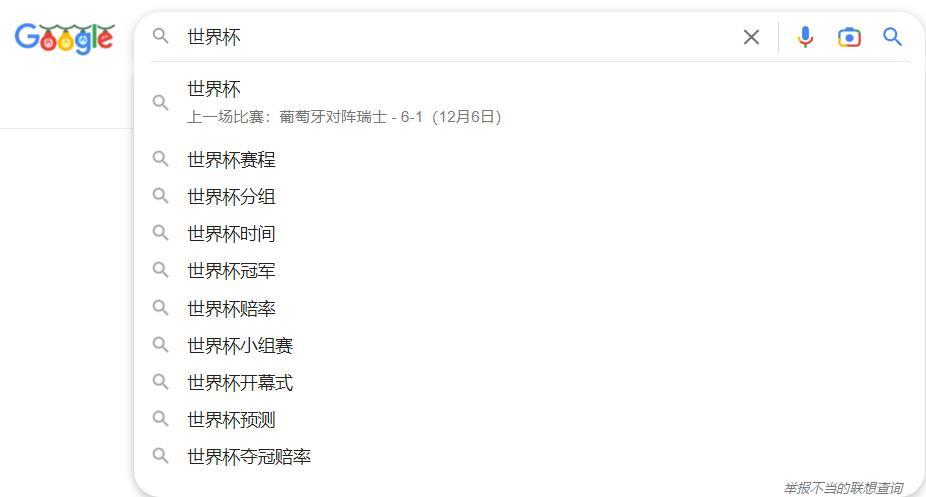
Elasticsearch 能实现自动补全检索的方案很多可以简单归结为如下几种不同的方案
方案一Prefix 前缀匹配检索。
方案二MatchPhrase prefix 短语前缀匹配检索。
方案三更细粒度的 ngram 分词间接解决前缀匹配检索。
方案四Search as your type 类型。
方案五Completion Suggest 自动补全。
方案一、方案二的样例数据如下所示
PUT worldcup_index "mappings": "properties": "title": "type": "text", "analyzer": "ik_max_word", "fields": "keyword": "type": "keyword" POST worldcup_index/_bulk"index":"_id":1"title":"世界杯-拉莫斯帽子戏法 葡萄牙6-1晋级将战摩洛哥""index":"_id":2"title":"世界杯2022赛程""index":"_id":3"title":"世界杯8强全部出炉C罗收获大礼梅西被3大强队包围""index":"_id":4"title":"FIFA世界杯的微博""index":"_id":5"title":"世界杯赛事积分榜及排名""index":"_id":6"title":"世杯界16强决赛对阵表""index":"_id":7"title":"卡塔尔世界杯为什么在冬天"
2、prefix前缀匹配
2.1 prefix 检索类型范畴
属于 term level 精准匹配的范畴。
2.2 针对字段类型
keyword类型。
当然 text 也可以但不够精准结果可能达不到预期。
POST worldcup_index/_search "profile": true, "query": "prefix": "title.keyword": "世界"
检索召回数据结果如下仅截图最核心部分
3、 match_prhase_prefix 检索类型
3.1 检索类型范畴
属于全文检索的范畴。
3.2 针对字段类型
text 类型。
确切说是实现 text 短语匹配的自动补全功能。
3.3 match_phrase_prefix 短语前缀匹配演示
POST worldcup_index/_search "query": "match_phrase_prefix": "title": "query": "世界"
检索召回数据结果如下仅截图最核心部分
3.4 match_phrase_prefix 检索核心实现
实则为MultiPhraseQuery 实现“世界”、“世”、“界”的组合检索。
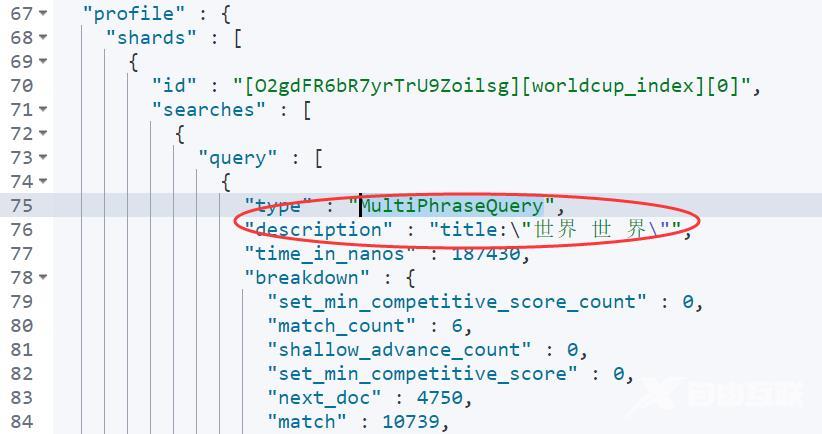
有同学可能会问“世界 世 界” 三个分词单元怎么来的
看这里和 analyzer 分词有关系我们的字段 title 设置的是 text 类型选择的分词器ik_max_word 分词器。
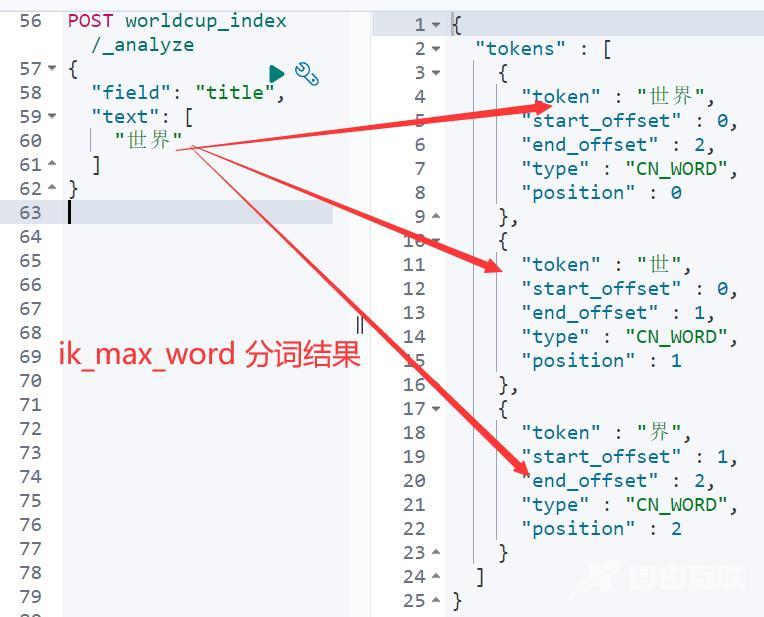
4、更细粒度分词器解决自动补全检索
之前咱们讲过也是大家常见的问题比如手机号的自动补全检索问题。
可以看一下之前的视频
这种传统的分词和咱们上面讲过的两种检索方式都不灵。怎么办
需要自定义分词来实现。
4.1 自定义分词实现
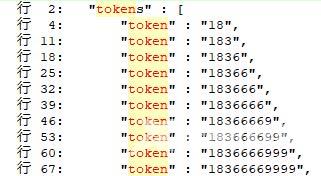
PUT phone_index "settings": "analysis": "analyzer": "autocomplete": "tokenizer": "autocomplete", "filter": [ "lowercase" ] , "tokenizer": "autocomplete": "type": "edge_ngram", "min_gram": 2, "max_gram": 20 , "mappings": "properties": "phone_number": "type": "text", "analyzer": "autocomplete" POST phone_index/_analyze "field": "phone_number", "analyzer": "autocomplete", "text": [ "18366669999" ]
如上 analyze 分词结果为
导入数据
POST phone_index/_bulk"index":"_id":1"phone_number":"18366669999""index":"_id":2"phone_number":"18311112222""index":"_id":3"phone_number":"18333332222""index":"_id":4"phone_number":"18255552222"
执行检索
POST phone_index/_search "profile": true, "query": "match_phrase_prefix": "phone_number": "183" 
自定义分词实现自动补全检索的优点空间换时间针对极大数据量检索依然会很快。
缺点1、写入效率低2、磁盘空间耗费大。
5、search_as_your_type 检索方案
5.1 search_as_your_type 数据类型介绍
search_as_your_type 字段类型7.2 版本之后才有的功能是一个类似文本的字段经过优化以提供开箱即用的支持用于完成自动补全的查询。
支持前缀完成即匹配从输入开头开始的术语和中缀完成即匹配输入中任何位置的术语的检索。
5.2 search_as_your_type 初探
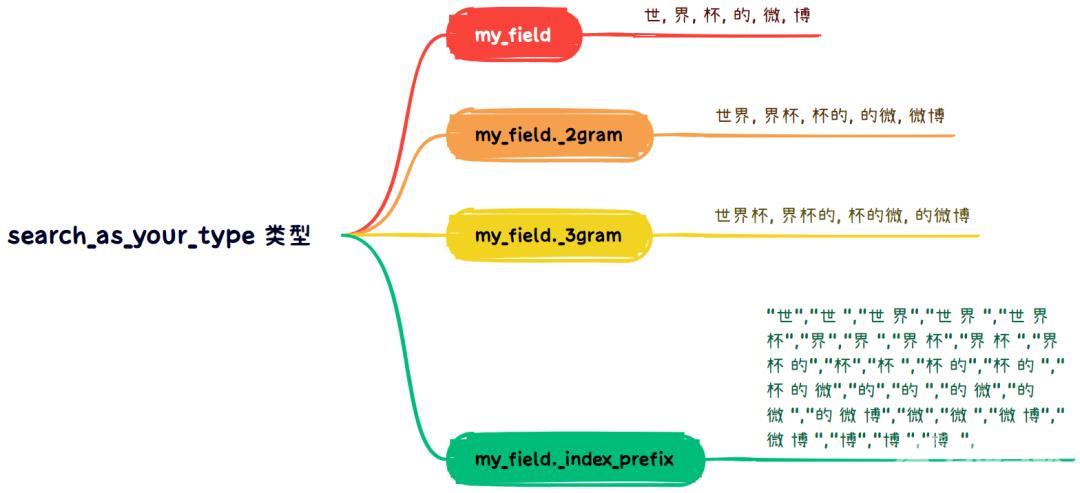
search_as_your_type 字段本质上支持四种不同的分词。
第一种标准 standard 分词器单字为一个分词单元
第二种_2gram 分词器两个单词为一个分词单元
第三种_3gram 分词器三个单词为一个分词单元
第四种_index_prefix 分词器前缀、中缀分词方式。
以“世界杯的微博”文档为例各种不同类型的分词结果如下
5.3 search_as_your_type 实战
如下检索方式使用了multi_match 和 bool_prefix 检索结合"title"、“title._2gram”、"title._3gram"、“title._index_prefix”多字段检索的方式。
这几个字段的最终检索结果基于 most_fields 方式求和得到总的评分。
实际业务层面根据需要选择字段即可。
POST world_cup_index_1207/_search "query": "multi_match": "query": "世界", "type": "bool_prefix", "fields": [ "title", "title._2gram", "title._3gram", "title._index_prefix" ]
对比可以看出这种检索方式非常的灵活。
6、自动补全建议 suggesters 检索
6.1 Elasticsearch suggesters 介绍
Suggesters 是 Elasticsearch 中的高级解决方案可根据用户的输入的文本返回外观相似的短语。Suggesters 可以实现类似检索时提示、用户搜索词联想或校验等功能。
相比于前四种实现方式这种方式“根正苗红”更加的适合实现企业级的自动补全检索。
6.2 Elasticsearch completion suggest 用法
创建索引及构造数据如下
首先需要在索引中添加一个 suggest 字段。如下代码的 suggest 字段该字段将保存要提供的补全建议。
然后写入数据。同时指定input 文本和 weight 权重。input 代表补全建议的文本信息weight 代表权重权值越大计算的评分越高反之则相反。
PUT worldcup_suggest_index "mappings": "properties": "title": "type": "keyword" , "suggest": "type": "completion" PUT worldcup_suggest_index/_bulk"index":"_id":1"suggest":["input":["世界杯2022赛程"],"weight":3]"index":"_id":2"suggest":["input":["世界杯赛事积分榜及排名"],"weight":2]"index":"_id":3"suggest":["input":["FIFA世界杯的微博"],"weight":1]"index":"_id":4"suggest":["input":["世界杯2022赛程"],"weight":1]
最后使用 Elasticsearch 的自动补全 API 来获取补全建议。
POST worldcup_suggest_index/_search "suggest": "worldcup-suggest": "prefix": "世界", "completion": "field": "suggest" 
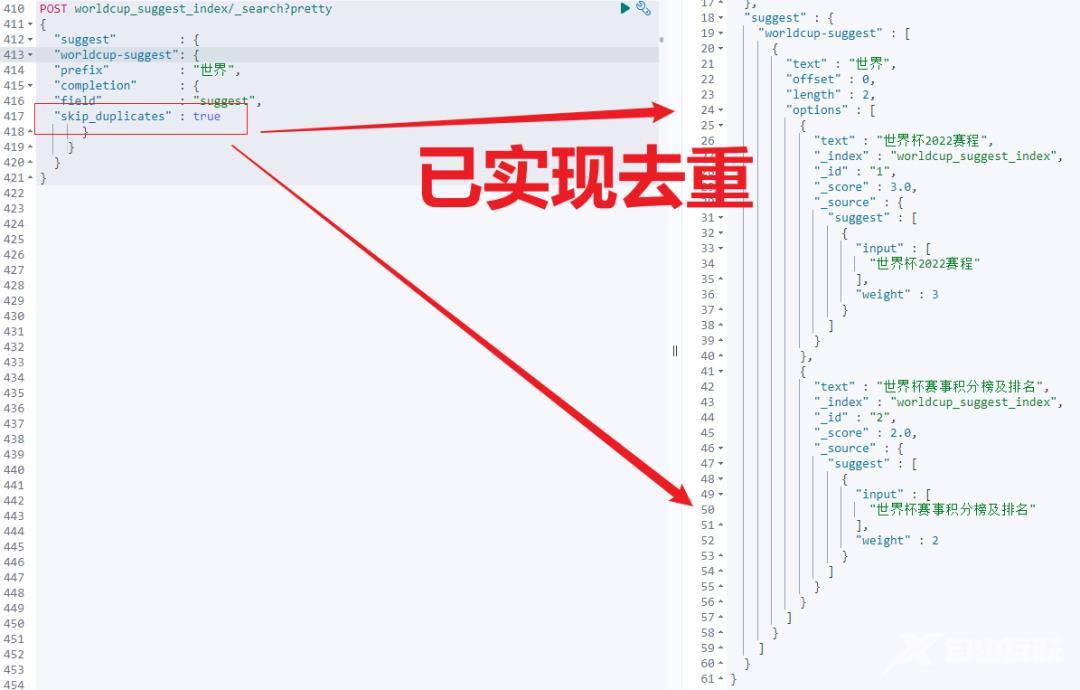
我们推荐结果有重复数据如何去重呢
这个问题业务层面也经常遇到。completion 借助参数
"skip_duplicates" : true
实现推荐结果数据的去重。
 7、小结
7、小结 关于Elasticsearch 8.X 能实现自动补全本文提供了五种不同的方案。几种方案的对比概括如下

解决企业级业务问题远不止这几种方案。
你有没有遇到自动补全问题用什么方案解决的
欢迎留言讨论。
推荐阅读
全网首发从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单2022年国庆更新版
如何系统的学习 Elasticsearch

更短时间更快习得更多干货
和全球 1800 Elastic 爱好者一起精进

比同事抢先一步学习进阶干货