
脑电波介绍

脑电波(Electroencephalogram, EEG)是应用电生理指标来记录大脑活动的方法。大脑在活动时,神经元同步发生突触后电位反应在了头皮表面,研究者将电机放置在被试者的头皮上检测脑电波信号。电机位置大概如下:

实际而言,收集到的数据就是多个通道的时间序列数据:

之前有幸参加了学院路内的一个脑电实验,签了保密协议就不谈实验内容了。抛开内容不谈,这次实验让我觉得虽然脑电的理论基础很好,但是实际上执行的可能并不是很理想。电极位置、实验流程等都可能影响数据的质量。


信号预处理

在进行模型构建前,主要有三个步骤:信号预处理、数据增强和特征提取。
1
伪影处理
脑电信号会受到眼部伪影和肌电信号的影响。眼部伪影(EOG)是在受试者眼球或眼皮改变眼向或眨眼时,在EEG信号中产生的扰动。肌电信号(EMG)则是由吞咽或咬合时引起的,分布范围为0-200Hz。
对于伪影的处理,约四分之一的研究者忽视了伪影,四分之一手工进行去除。其余进行去除伪影的算法最主要的为ICA与DWT,还有其他的一些名字特别长的算法。
独立成分分析
ICA(Independent Component Analysis)
数据有可能是多个独立分量的组合时(盲源分离),应用ICA可以将其提取出来。声音数据是线性叠加的,电信号数据我简单搜了一下没有搜到,之后再补充吧。
ICA之前往往对数据进行PCA和白化处理,以提取源信号中的信息。例如图中是PCA提取特征后的声音信号,这些信号都由三种简单的波形组成。
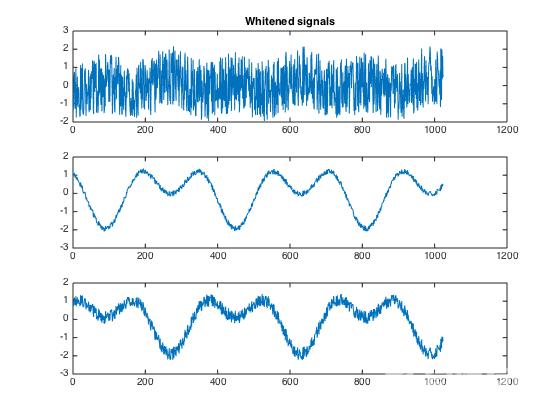
ICA算法进行多步迭代寻优,将信号解混为以下三种波形:

离散小波变换
DWT(Discrete Wavelet Transformation)
小波也就是wavelet是一种均值为零,快速衰减的波浪状震荡,存在时间有限:

离散小波变换主要用于信号的去噪,主要流程如下:

在这个变换中,可以捕获几个幅值较大的DWT系数的重要信号,信号中的噪声则会生成较小的DWT系数。DWT有助于分析不同分辨率下逐渐变窄的子带上的信号,以及帮助去噪和压缩信号。
2
滤波处理
在一篇综述中收集的文献中,各类问题滤波处理方法如下,大部分都使用了带通滤波,取1-40hz的信号。


数据增强
有很多研究将眨眼、肌肉活动和高斯噪声加入到了原数据集中,以生成新的样本。高斯噪声是概率密度函数服从高斯分布(即正态分布)的一类噪声。如果它的功率谱密度又是均匀分布的,则称为高斯白噪声。
同时也有将高斯噪声添加到输入的特征向量中,而非原始的数据中的增强方法。
重叠窗口以增加数据。对于分类问题一般我们都在一段脑电序列的信号中依次截取几秒作为窗口,然后对于每个窗口进行分类。那么如果将窗口重叠截取,就会有更多的样本了。
交换左右侧电极数据,使样本翻倍。这个方法对于大脑对称的活动来说有效,但是可能泛用性不是很高的样子。
将预处理时下采样丢弃的数据作为新样本。这个思路我没有太理解,生成的样本不会与原样本差距过大吗,可能需要仔细读一下文献再说。
以及应用cDCGAN生成人工脑电图信号。就是在GAN的基础上在生成模型的随机噪声处合并一个标签,以作为条件约束生成特定标签的模型。

生成原始EEG数据的傅里叶变换替代物。将EEG数据进行傅里叶变换为频域数据后,直接生成频域的数据而不是原始的数据。
特征提取
之后就是输入进深度学习模型的特征的问题了,综述中共分为三个大类,计算特征、图像特征、以及信号值。

1
计算特征
最多的计算特征是PSD(Power Spectral Density),也即功率谱密度。其定义了信号或者时间序列的功率如何随频率分布。

其次的是wavelet decomposition,指的可能是DWT等小波变换等操作。
之后占比较多的是statistical measures,包括信号的平均值和标准差等。
2
图像特征
在一些CNN架构的网络中,会用到eeg生成的频谱图作为输入。

以及Fourier feature maps

以及堆叠信号生成的2D、3D结构

3
信号值
信号值大多数是raw,也就是直接输入不经处理的信号。不过aaai的一篇文章(2021)中提到,目前来说CNN、RNN和attention机制之类的很难提取出EEG中的隐藏信息。所以根据道听途说来的消息,raw数据直接输入的可靠性还有待商榷。
Averaged方法综述中没有提到,推断应该是指signal averaging,将多个相同类别的片段求平均并输入。
CVT指Complex Value Transformation,应该是某篇文章中作者拍脑袋想出来的算法。
结语

之前写稿的时候姜学姐问我是不是在写专设的内容,我一想这个确实值得一写。
树莓派这个板子可以写python和c,能实现很多复杂的功能,在我们这届的专设中用的很广泛。不过大多数人又不会写代码,又不会搞硬件,只能在组里当个挂件并度过相对失败的专业设计课程。于是我准备之后科普一下从零开始使用树莓派,以防学弟学妹们以后像我的队友一样一边摆烂一边说我干的不够多。专设真是令人愉悦的小组合作呢 : )