python 爬虫小试牛刀(一)
在github上发现一个轻量级的爬虫框架
一. 官网介绍 requests-html中文文档
- 全面支持解析Javascript!
- CSS 选择器 (jQuery风格, 感谢PyQuery).
- XPath 选择器, for the faint at heart.
- 自定义user-agent (就像一个真正的web浏览器).
- 自动追踪重定向.
- 连接池与COOKIE持久化.
- 令人欣喜的请求体验,魔法般的解析页面.
嗯 感觉好像很强大, 试一试, 315晚会报道了360 医疗相关假广告,想着就爬点医疗相关数据
http://www.fudanmed.com/institute/news2019-2.aspx 锁定目标先,就先把全国前一百名医院数据爬到excel里实践下
二. F12分析网页元素接口
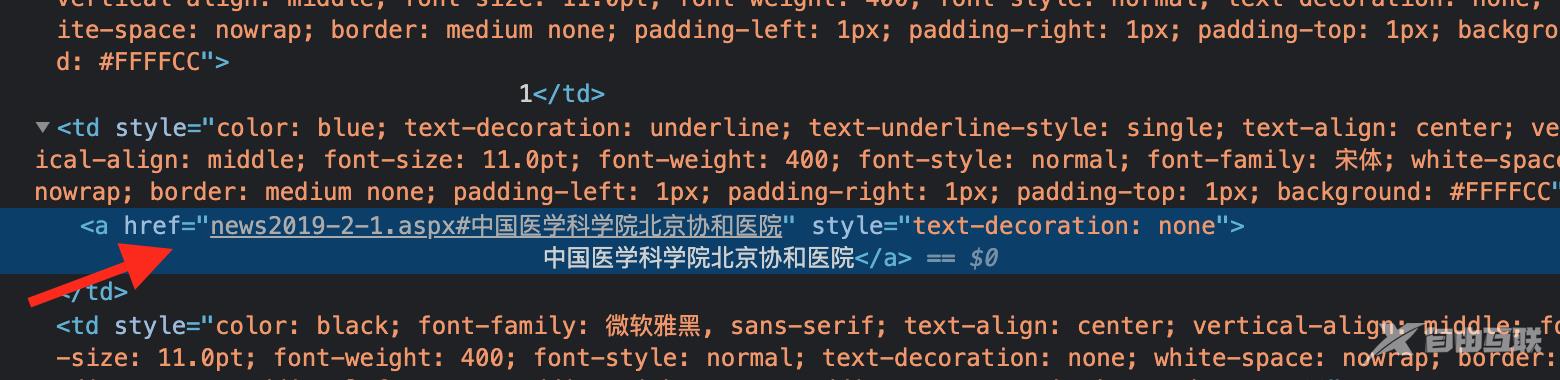
整个页面table包裹,医院名称包裹在a标签里
最简单粗暴的思路是爬取所有a标签里的数据,然后循环提取href里的文本,直接上代码
# coding=UTF-8from requests_html import HTMLSessionimport xlwt#链接网页站点session = HTMLSession()r = session.get('http://www.fudanmed.com/institute/news2019-2.aspx')#初始化一个Excelxl = xlwt.Workbook(encoding='utf-8')sheet = xl.add_sheet('全国医院排名')sheet.write(0, 0, '排名')sheet.write(0, 1, '医院名称')#初始化排名i = 0#爬取数据def findHospitalName(): trs = r.html.find("a") for item in trs: #获取到a标签的href属性里的文本 text = item.find('a', first=True).attrs['href'] filterData(text)#清洗数据def filterData(text): #过滤文本了的链接参数 if "#" in text: array = text.split("#", 1) #过滤掉空 if len(array[1]): global i i += 1 writeData(i, array[1])#写入数据def writeData(sort, data): print(sort) print(data) sheet.write(sort, 0, sort) sheet.write(sort, 1, data) xl.save('/Users/lsr/Documents/GJProject/py/' + "全国医院排名" + ".xls")#开始findHospitalName()
别看代码多,其实核心代码就两条
trs = r.html.find("a") #获取所有a标签数据,返回 Element对象 数组text = item.find('a', first=True).attrs['href'] #获取a标签的herf属性
