写入层上Lambda 没有对数据写入进行抽象而是将双写流批系统的一致性问题反推给了写入数据的上层应用
存储上以 HDFS 为代表的master dataset 不支持数据更新持续更新的数据源只能以定期拷贝全量 snapshot 到 HDFS 的方式保持数据更新数据延迟和成本比较大
计算逻辑需要分别在流批框架中实现和运行而在类似 Storm 的流计算框架和Hadoop MR 的批处理框架做 job 开发、调试、问题调查都是比较复杂的
结果视图需要支持低延迟的查询分析通常还需要将数据派生到列存分析系统并保证成本可控。
传统仓库的架构设计
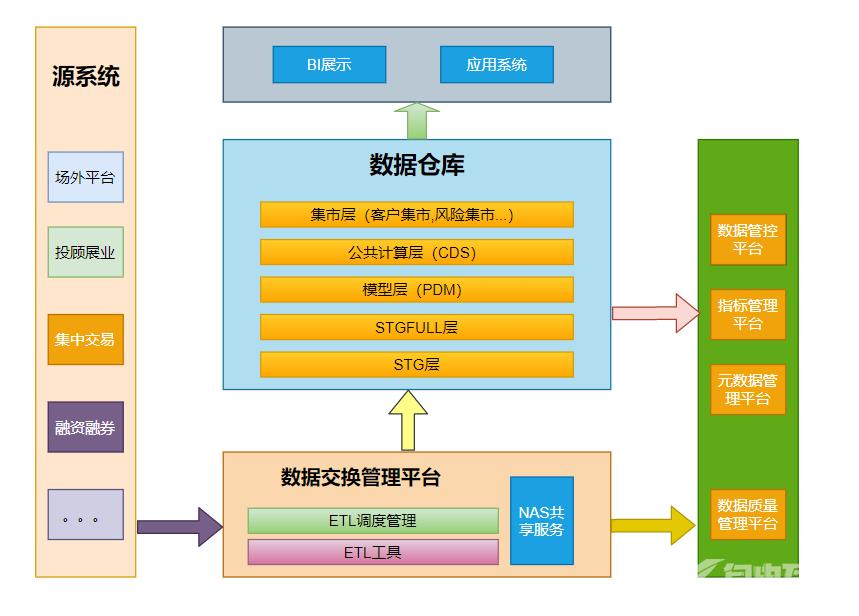
根据多年的传统仓库实践经验基本的框架如上图所示左边一列表示各个源系统经过数据交换管理平台处理后进入数据仓库的STG。数据交换管理其实就是仓库的ETL过程目前常用的方案是使用NAS公共服务管理中间数据。
管理的公共数据除了数据共享以外还可以作为数据质量管理的基础关于数据质量平台就是通过一系列的检查逻辑检查数据的合理性完备性规范性目前一般关于这部分的检查都在使用数据仓库的资源来进行的比如分配到STG层PDM层甚至集市层验证数据质量这样导致的后果是比较占用数据仓库的资源。关于数据质量这块其实最大的问题还是换行符特殊字符等等的检测一个比较好的拆分是使用ETL服务器的资源计算数据质量的情况。
STG保存当天的数据STGFULL保存当前全量的数据
STG和STGFULL经过整合进入PDM模型在金融系统一般采用范式建模分成几大主题分类管理。
模型处理后进入公共计算层CDSCDS主要做公用的计算比如指标管理平台可以以CDS为基础模型提供的是通用的数据整合服务CDS提供更加精细的业务数据计算。
仓库对外就是各种的应用系统和BI报表之类的平台关于仓库对外的接口需要讨论一下传统仓库对外一般通过批量文件进行交换。但是仓库的优点是适合计算不适合导数之类的工作如果仓库里面大范围的导数会很吃资源需要集中管理起来。
此外还有数据管控平台和元数据管理系统元数据管理系统可以通过ETL采集各个源的元数据再整合仓库内部的元数据形成统一的元数据管理
数据管控平台更多的涉及数据资产管理相关。
老胡点评
传统大数据架构其定位是为了解决传统BI的问题。这样做的优点是简单、易懂但是缺点也非常的明显对业务支撑的灵活度不够对于存在大量报表或复杂钻取的场景需要太多的手工定制化同时该架构依旧以批处理为主缺乏实时的支撑。
流式架构
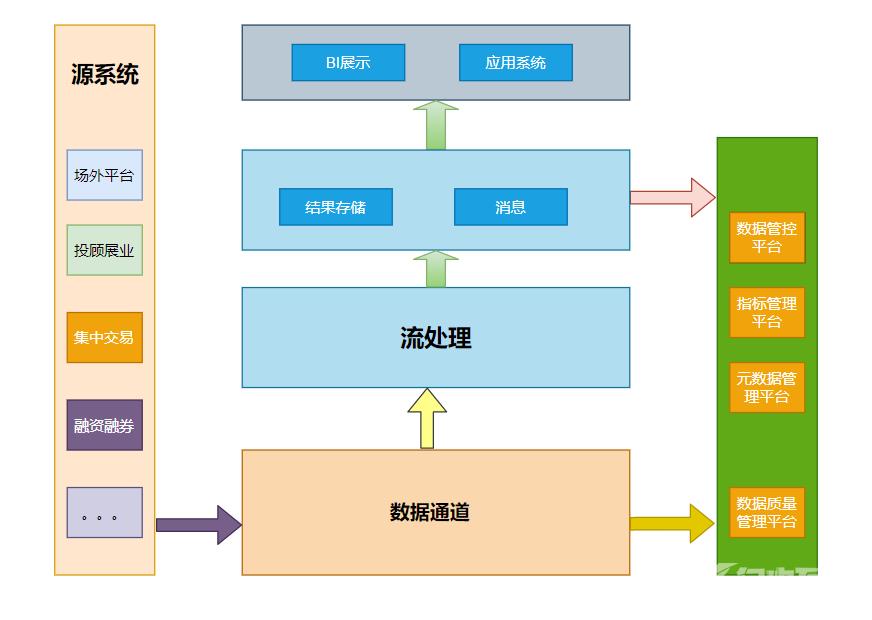
流式架构直接去掉了批处理数据全程以流的形式处理数据接入端没有了ETL转而替换为数据通道常用的数据通道工具就是kafka。
流处理加工后的数据部分以消息的形式直接推送给了消费者。部分存储供重复使用。
这样的架构没有ETL过程数据的实效性非常高。但是由于不存在批处理因此对于数据的历史统计无法很好的支撑。对于离线分析仅仅支撑窗口之内的分析。
老胡点评
纯流式的架构比较激进但是也有适用适用场景比如预警、监控、对数据有有效期要求的情况等等。
Lambda架构
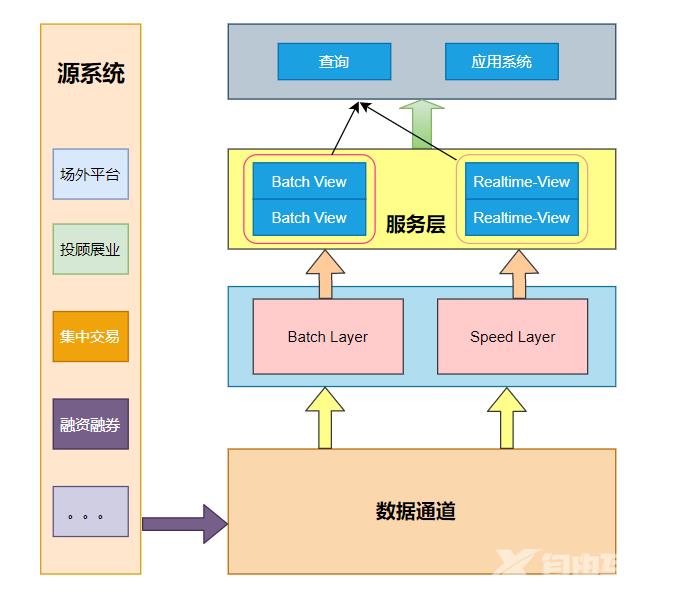
目前大多数架构基本都是Lambda架构或者基于其变种的架构。
Lambda的数据通道分为两条分支实时流和离线。实时流依照流式架构保障了其实时性而离线则以批处理方式为主保障了最终一致性。
流式通道处理为保障实效性更多的以增量计算为主辅助参考而批处理层则对数据进行全量运算保障其最终的一致性。
Lambda 架构的实时和批量部分具有相同的计算逻辑并且在查询阶段合并batch view和real-time view的计算视图并展示给用户。
但是批处理相对简单不易出现错误而流处理相对不太可靠因此流处理器可以使用近似算法快速产生对视图的近似更新而批处理系统会采用较慢的精确算法产生相同视图的校正版本。
老胡点评
为了保证不断变化的历史数据和实时数据的查询需求Lambda 架构使用合并批处理视图和流处理视图的方式很巧妙的满足了相关需求。
这种方法既有实时又有离线全面的覆盖了各个场景这种方式有一个缺点就是相同的脚本要维护两套不管开发测试两套保持一致。
另外在数据的写入方面显然一边是增量一边是全量这种可能需要上层应用进行控制
Kappa架构
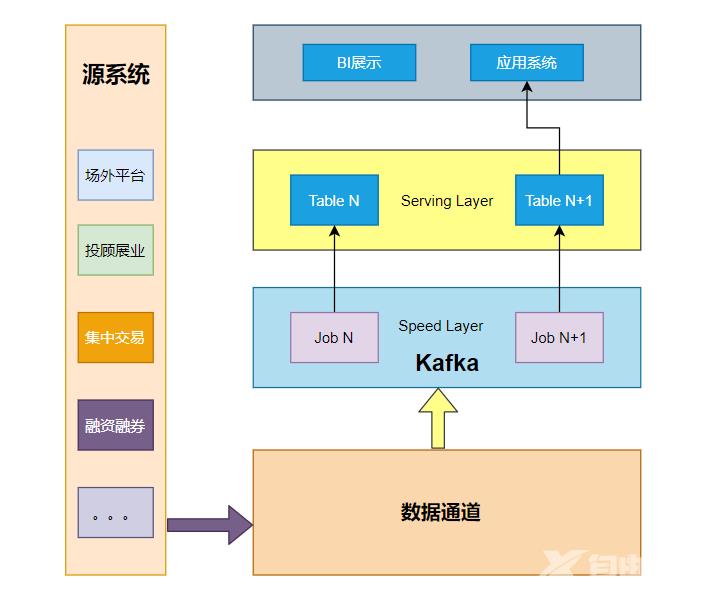
不同于Lambda 同时计算流计算和批计算并合并视图Kappa 只会通过流计算一条的数据链路计算并产生视图。
Kappa严格依赖Kafka因为历史和当前的数据都在Kafka中那么Kafka的保存日期的长度就需要查询的最长历史长度。
当需要全量计算时重新起一个流计算实例从头开始读取数据进行处理并输出到一个结果存储中。
当新的实例完成后停止老的流计算实例并把老的一引起结果删除。
Kappa 架构只保留了速度层而缺少批处理层在速度层上处理大规模数据可能会有数据更新出错的情况发生这就需要我们花费更多的时间在处理这些错误异常上面。
针对一些开放的分析需求具有很好的适用性。
但它依然没有解决存储和展示的问题特别是在存储上使用类似 kafka 的消息队列存储长期日志数据数据无法压缩存储成本很大。
Kappa 不是 Lambda 的替代架构而是其简化版本Kappa 放弃了对批处理的支持更擅长例如各种时序数据场景天然存在时间窗口的概念流式计算直接满足其实时计算和历史补偿任务需求
Lambda 直接支持批处理因此更适合对历史数据有很多 ad hoc 查询的需求的场景比如数据分析师需要按任意条件组合对历史数据进行探索性的分析并且有一定的实时性需求期望尽快得到分析结果批处理可以更直接高效地满足这些需求。
典型大数据架构的情况和问题
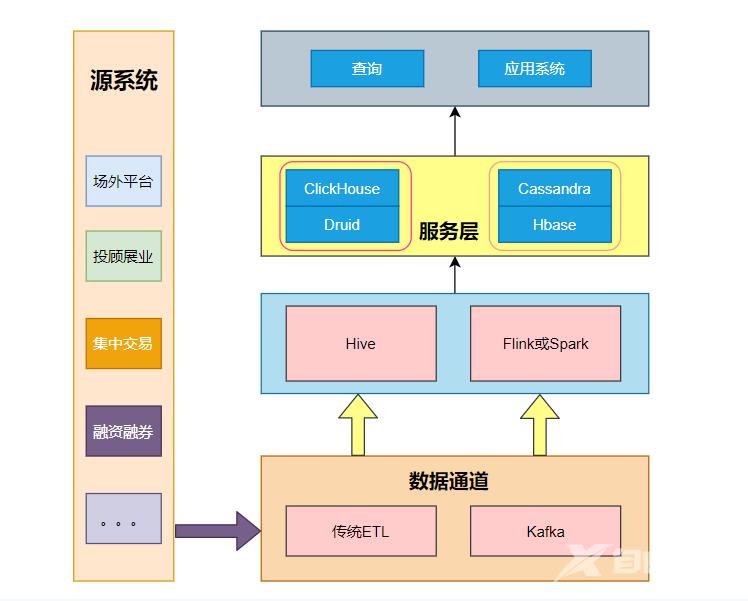
市面上有很多存储的开源产品每种产品都有其适用场景比如基于离线存储的HiveHive除了离线存储还可以做离线批量。
kafka作为消息中间件更多的作为实时批量的源Flink或者spark stream 作为实时批量组件。
HBase、Cassandra主要提供点查询能力比如指标可视化相关但是只有点查而缺少分析能力。
为解决数据分析问题组件Druid和Clickhouse则提供分析功能。
Drill或者Presto可以设计为了对实时数据和离线数据做一个联邦查询。
但以上的每个存储产品都形成了一个又一个的数据孤岛。