模型训练系统模型训练系统模型训练系统
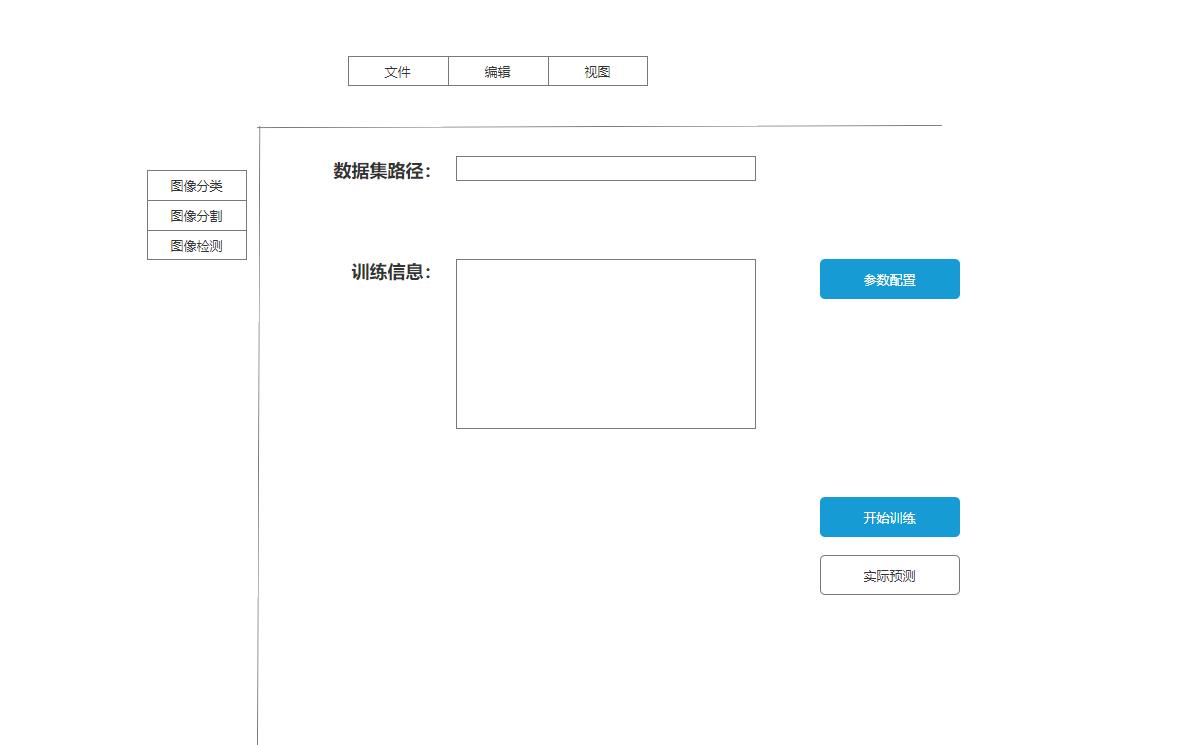
GUI界面采取读取文件的形式和后端模型训练进行分离
写XML文件
https://blog.csdn.net/qq_41375318/article/details/112883753
1002F:\PycharmWorkPlace\ModelTrainingSystem\api\classification\cifar10_dataset.txt
Train.py
1.读取xml文件2.配置各项参数3.训练
# 引入工具包 # step 0 参数配置 # step 1 数据处理 # step 2 模型 # step 3 损失函数 # step 4 优化器 # step 5 评测函数# step 6 训练 # step 7 训练可视化 # inference
# 引入工具包 from torch.utils.data import Datasetfrom PIL import Imageimport osimport torchvision.transforms as transformsfrom torch.utils.data import DataLoaderimport xml.etree.ElementTree as ET # 导入ElementTree模块import torch.optim as optimimport torch.nn as nnimport torch# step 0 参数配置 device torch.device(cuda) if torch.cuda.is_available() else torch.device(cpu)norm_mean [0.33424968, 0.33424437, 0.33428448]norm_std [0.24796878, 0.24796101, 0.24801227]epoch Nonebatchsize Nonetrain_dataset_path Nonevalid_dataset_path Nonelearning_rate Nonepath_saved_model best_model.pth# 解析xml配置tree ET.parse(train_config.xml) # 获取解析对象root tree.getroot() # 获取根节点# 赋值for node in root.iter(epoch): # 在 根节点的子节点中过滤出标签‘epoch’epoch int(node.text)for node in root.iter(batchsize): # 在 根节点的子节点中过滤出标签‘batchsize’batchsize int(node.text)for node in root.iter(train_dataset_path): # 在 根节点的子节点中过滤出标签‘dataset_path’train_dataset_path node.textfor node in root.iter(valid_dataset_path): # 在 根节点的子节点中过滤出标签‘dataset_path’valid_dataset_path node.textfor node in root.iter(learning_rate): # 在 根节点的子节点中过滤出标签‘learning_rate’learning_rate float(node.text)# step 1 数据处理与读取 train_transform transforms.Compose([transforms.Resize((32, 32)),transforms.ToTensor(), # 0-255 归一化到0-1 转Tensortransforms.Normalize(norm_mean, norm_std),])# 返回所有图片路径和标签def get_img_info(data_dir):data_info []with open(data_dir, rU) as file:for i ,line in enumerate(file):split_res line.split(" ", 1)path_img split_res[0]label split_res[1]data_info.append((path_img, int(label)))return data_infoclass LoadDataset(Dataset):# 确定数据路径def __init__(self, data_dirNone, transformNone):self.imgs_labels get_img_info(data_dir)self.transform transform# 获取并返回真实的数据和labeldef __getitem__(self, index):img_path,label self.imgs_labels[index]img Image.open(img_path)# img.show()if self.transform is not None:img self.transform(img) # 在这里做transform转为tensor等等return img, label# 确定索引的范围def __len__(self):return len(self.imgs_labels)train_dataset LoadDataset(data_dirtrain_dataset_path,transformtrain_transform)train_loader DataLoader(datasettrain_dataset, batch_sizebatchsize, shuffleTrue) # shuffle训练时打乱样本valid_dataset LoadDataset(data_dirvalid_dataset_path,transformtrain_transform)valid_loader DataLoader(datasettrain_dataset, batch_sizebatchsize) # shuffle训练时打乱样本# step 2 模型 from net.classification.ResNet import ResNet18net ResNet18(10,512) # 对应修改模型 net se_resnet50(num_classes5,pretrainedTrue)# step 3 损失函数 criterion nn.CrossEntropyLoss()# step 4 优化器 optimizer optim.SGD(net.parameters(), lrlearning_rate, momentum0.9) # 选择优化器scheduler torch.optim.lr_scheduler.StepLR(optimizer, step_size10, gamma0.1) # 设置学习率下降策略每过step_size个epoch做一次更新# step 5 评测函数def evaluteTop1(model, loader):model.eval()correct 0total len(loader.dataset)for x, y in loader:x, y x.to(device), y.to(device)with torch.no_grad():logits model(x)pred logits.argmax(dim1)correct torch.eq(pred, y).sum().float().item()# correct torch.eq(pred, y).sum().item()return correct / totaldef evaluteTop5(model, loader):model.eval()correct 0total len(loader.dataset)for x, y in loader:x, y x.to(device), y.to(device)with torch.no_grad():logits model(x)maxk max((1, 5))y_resize y.view(-1, 1)_, pred logits.topk(maxk, 1, True, True)correct torch.eq(pred, y_resize).sum().float().item()return correct / total# step 6 训练 for i in range(epoch):# 训练print("current_epoch:",i1)best [0] # 存储最优指标用于Early Stoppingcorrect 0total_loss 0for idx,data_info in enumerate(train_loader):inputs, labels data_info# forwardoutputs net(inputs)# backwardoptimizer.zero_grad() # 梯度置零,设置在loss之前loss criterion(outputs, labels) # 一个batch的losstotal_loss loss.item()loss.backward() # loss反向传播# update weightsoptimizer.step() # 更新所有的参数# 统计分类情况_, predicted torch.max(outputs.data, 1) # 1 返回索引的意思correct (predicted labels).squeeze().sum().numpy() # 计算一共正确的个数print("loss:",total_loss)print("acc:",correct/(len(train_loader)*batchsize))scheduler.step() # 更新学习率# 打印当前学习率print("当前学习率",optimizer.state_dict()[param_groups][0][lr])if max(best) < correct/(len(train_loader)*batchsize):best.append(correct/(len(train_loader)*batchsize))torch.save(net.state_dict(), "best_model.pth")# 验证val_correct 0if epoch % 5 0:print("valid")for idx, data_info in enumerate(valid_loader):inputs, labels data_info# forwardoutputs net(inputs)_, predicted torch.max(outputs.data, 1) # 1 返回索引的意思val_correct (predicted labels).squeeze().sum().numpy() # 计算一共正确的个数print("val_acc:", val_correct / (len(valid_loader) * batchsize))
Predict.py
用switch语句进行选择
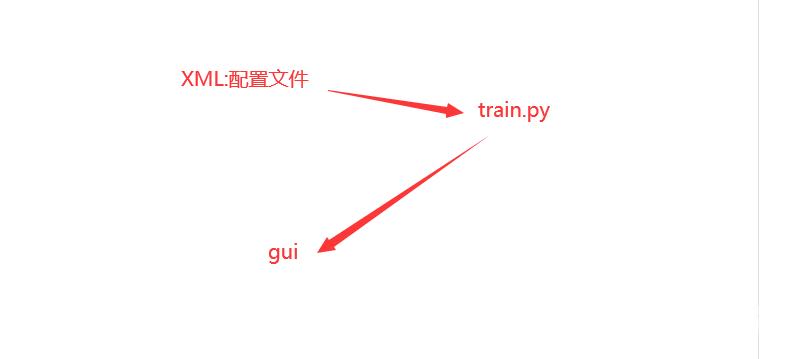
用xml保存中间模型训练参数
1002F:\PycharmWorkPlace\ModelTrainingSystem\api\classification\cifar10_dataset.txt
所有系统导入的模型数据集标准都以txt保存左侧为原始数据右侧为标注数据之间用空格来间隔
G:\dataset\split_data\split_data\test\0\0_116.png 0G:\dataset\split_data\split_data\test\0\0_116.png 0G:\dataset\split_data\split_data\test\0\0_116.png 0G:\dataset\split_data\split_data\test\0\0_116.png 0G:\dataset\split_data\split_data\test\0\0_116.png 0G:\dataset\split_data\split_data\test\0\0_116.png 1G:\dataset\split_data\split_data\test\0\0_116.png 1G:\dataset\split_data\split_data\test\0\0_116.png 1G:\dataset\split_data\split_data\test\0\0_116.png 1G:\dataset\split_data\split_data\test\0\0_116.png 1G:\dataset\split_data\split_data\test\0\0_116.png 2G:\dataset\split_data\split_data\test\0\0_116.png 2G:\dataset\split_data\split_data\test\0\0_116.png 2G:\dataset\split_data\split_data\test\0\0_116.png 2G:\dataset\split_data\split_data\test\0\0_116.png 2