目录
- 概述
- 一些常用命令
- 实现
- 跳跃表
- 跳表的插入
- 压缩列表
概述
一些常用命令
- 存储:zadd key score value
- 获取:zrange key start end
- 获取:同时获取分数:zrange key start end with score
- 删除:zrem key value
存储的时候我们可以发现,是有一个score(分数)的,这个就是用来排序的字段。
实现
先说结论,SortedSet底层,根据配置会在不同的时候选用两种不同的数据结构zset,或ziplist进行存储:
首先,我们来看几个参数:
zset-max-ziplist-entries 128zset-max-ziplist-value 64if ( field-value对的数量 > ziplist.entries.size || 任意一个filed或value长度 > zset-max-ziplist-value) { // 使用 zset 进行存储} else { // 使用 ziplist 进行存储zset的结构如下:
typedef struct zset { dict *dict; zskiplist *zsl;} zset可以发现,是由字典+跳跃表实现的。
- zset 结构体里有两个元素,一个是 dict,用来维护 数据 到 分数 的关系,一个是 zskiplist,用来维护 分数所在链表 的关系
- dict 里通过维护 哈希表 存储了 张三=>100,李四=>90 的分数关系。
而跳表则是排序的关键
跳跃表
先上图:
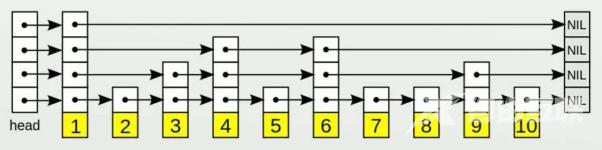
我们知道,链表的检索效率是非常低的,如果要拿到100条数据中间的数据,则需要遍历50个数据才行,为了解决这个问题,跳表应运而生
如上图,就是常规的跳表,会在原有的数据上加上若干层,指向当前层的下一个节点。
跳表的插入
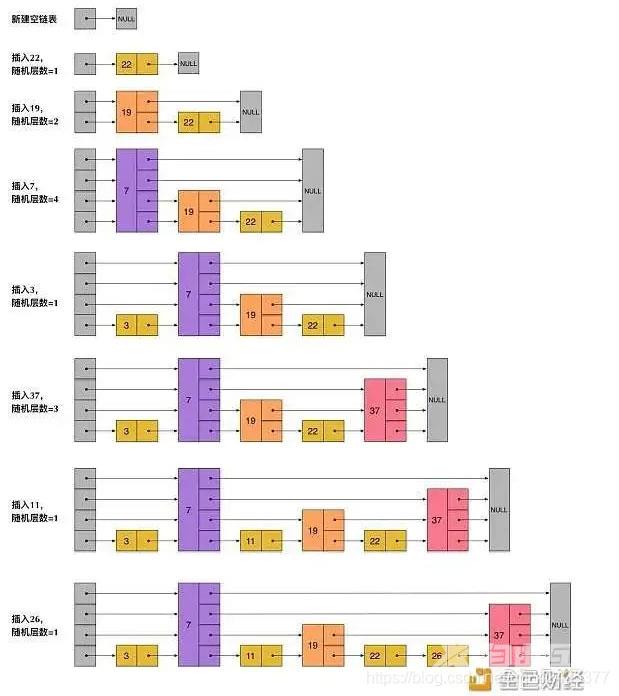
如上图所示:其实每个节点的层数是随机的,而且新插入一个节点不会影响其它节点的层数。因此,插入操作只需要修改插入节点前后的指针,而不需要对很多节点都进行调整。这就降低了插入操作的复杂度。实际上,这是skiplist跳表的一个很重要的特性,这让它在插入性能上明显优于平衡树的方案。
如下图,假如我们需要查询23,查询的路径如下。
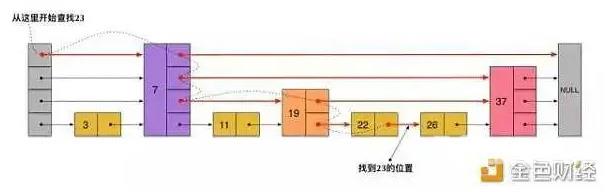
事实上,在插入之前也要先经历一个类似的查找过程,在确定插入位置后,再完成插入操作。
这也是SortedSet实现排序的原理。
压缩列表
压缩列表 ziplist 是为 Redis 节约内存而开发的。
压缩列表是由一系列特殊编码的连续内存块组成的顺序型数据结构,一个压缩列表可以包含任意多个节点 (entry),每个节点可以保存 一个字节数组 或者 一个整数值 。

1、zl bytes:用于记录整个压缩列表占用的内存字节数
2、zl tail:记录要列表尾节点距离压缩列表的起始地址有多少字节
3、zl len:记录了压缩列表包含的节点数量。
4、entryX:要说列表包含的各个节点
5、zl end:用于标记压缩列表的末端
压缩列表是一种为了节约内存而开发的顺序型数据结构
压缩列表被用作列表键和哈希键的底层实现之一
压缩列表可以包含多个节点,每个节点可以保存一个字节数组或者整数值
添加新节点到压缩列表,可能会引发连锁更新操作。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。