导读ICDMIEEE International Conference on Data Mining简称ICDM是数据挖掘领域的国际顶级会议。京东数科硅谷机器学习算法组朱翔宇带队在Knowledge Graph Contest知识图谱大赛中获得季军。本文将介绍2020 ICDM中的获奖方案和在 Workshop中分享的内容。基于BERT做了Finetune引入了一种全新的视角来重新审视关系行为原因提取任务并提出了一种新的序列标记框架而不是单独提取行为类型和行为原因。

一、问题背景
在内容广告、社会化聆听等许多业务场景中提取消费者一些行为的背后原因是关注的焦点。以内容广告为例如今的广告主并不满足于品牌或产品的直接曝光他们更喜欢通过产品功能嵌入内容潜移默化地激发消费者主动将自己的品牌或产品与任意的消费行为联系起来。为此明确地提取消费者行为发生的原因成为构建这样一个满足广告商需求的系统的重要技术。 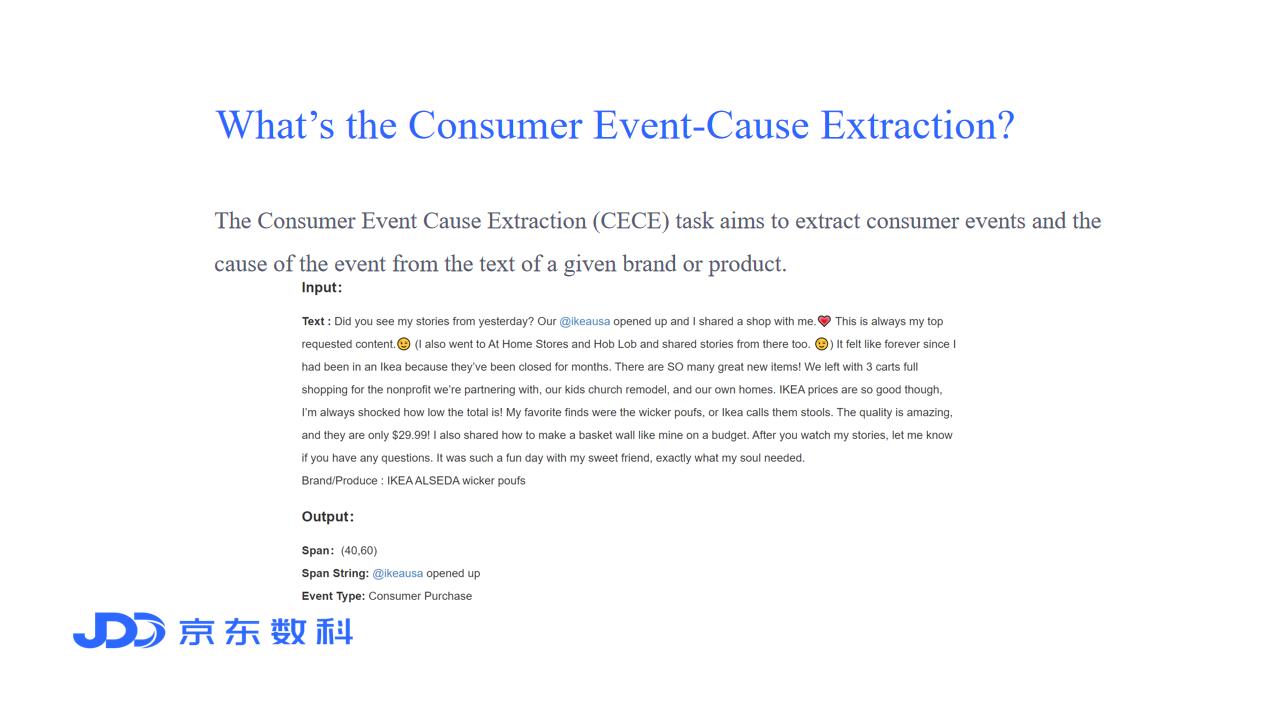 本赛题由行业解决方案专家挑选500篇Instagram文章以确保语言的正式性、多样性和对实际应用程序的知识深度。在本次ICDM评测单元中主要关注五种事件类型消费者的关注、消费者的兴趣、消费者的需求、消费者的购买和消费者的使用AttentionIntentionNeed PurchaseUse。同时评测主要采用F1评测。
本赛题由行业解决方案专家挑选500篇Instagram文章以确保语言的正式性、多样性和对实际应用程序的知识深度。在本次ICDM评测单元中主要关注五种事件类型消费者的关注、消费者的兴趣、消费者的需求、消费者的购买和消费者的使用AttentionIntentionNeed PurchaseUse。同时评测主要采用F1评测。 
二、问题挑战
 消费者行为的原因提取[1][10]是许多业务场景如内容广告、社交监听等关注的焦点。以内容广告为例。如今的广告主并不满足于品牌或产品的直接曝光他们更喜欢通过产品功能嵌入内容潜移默化地激发消费者主动将自己的品牌或产品与任意的消费行为联系起来。为此明确地提取消费者行为的原因成为构建这样一个满足广告商需求的系统的重要技术。
消费者行为的原因提取[1][10]是许多业务场景如内容广告、社交监听等关注的焦点。以内容广告为例。如今的广告主并不满足于品牌或产品的直接曝光他们更喜欢通过产品功能嵌入内容潜移默化地激发消费者主动将自己的品牌或产品与任意的消费行为联系起来。为此明确地提取消费者行为的原因成为构建这样一个满足广告商需求的系统的重要技术。
消费者行为原因提取CECE任务旨在从给定品牌或产品的文本中提取消费者行为和行为原因。传统的方法使用类似于抽取机器阅读理解MRC的模型结构[7]。大多数相关工作[6]都是分别提取行为类型和行为原因没有考虑它们之间的依赖关系。
三、方案简介
消费者行为归因提取是一项旨在从文本中提取特定行为背后潜在原因的任务由于其广泛的应用近年来受到了广泛的关注。ICDM 2020大会设立了一个评估竞赛旨在提取特定主题品牌或产品的行为及其原因。在本课题中我们主要研究如何构建一个端到端的模型同时提取多个行为类型和行为原因。
为此我们引入了一种全新的视角来重新审视关系行为原因提取任务并提出了一种新的序列标记框架而不是单独提取行为类型和行为原因。实验表明我们的框架优于基线方法即使它的编码模块使用一个初始化的预训练的BERT编码器显示了新的标签框架的力量。在这次比赛中我们队获得了第一阶段排行榜的第一名。
1、数据层面
为了保证数据的高质量性我们移除了文本中的ID。
例如“68771,Love doing makeup on all ages”处理成“"Love doing makeup on all ages”。
2、模型层面
 为了以端到端的方式提取消费者行为原因我们的模型主要由两部分组成BERT编码器和序列标签解码器。
为了以端到端的方式提取消费者行为原因我们的模型主要由两部分组成BERT编码器和序列标签解码器。
- BERT Encoder
首先我们将文本Text和标签brand/produt转换成 [CLS] Brand/Product [SEP] Text [SEP] 的形式作为模型的输入{x1,x2,…xn}。 然后我们使用预训练的BERT模型[2]对内容信息进行编码。编码模块从xj语句中提取特征信息zj并将其输入到后续的标记模块中。
这里我们简要回顾了基于多层双向变换器的语言表示模型BERT。它的目的是通过共同调节每个单词的左右语境来学习深层表征最近它在许多下游任务中被证明是非常有效的[3]。具体地说它由N个相同的Transformer blocks组成。我们将Transformer blocks表示为Transx其中x代表输入向量。具体操作如下 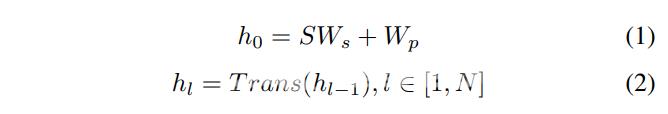
上式中S为输入句中子词索引的一个one-hot向量矩阵Ws为子词嵌入矩阵Wp为位置嵌入矩阵其中p表示输入序列中的位置索引hl为隐藏状态向量即第L层输入句的上下文表示N为变换器个数方块。注意在我们的工作中输入是一个单一的文本句子而不是句子对因此Eq中没有考虑原始BERT论文中描述的分段嵌入。关于Transformer的结构请参考论文[4]。 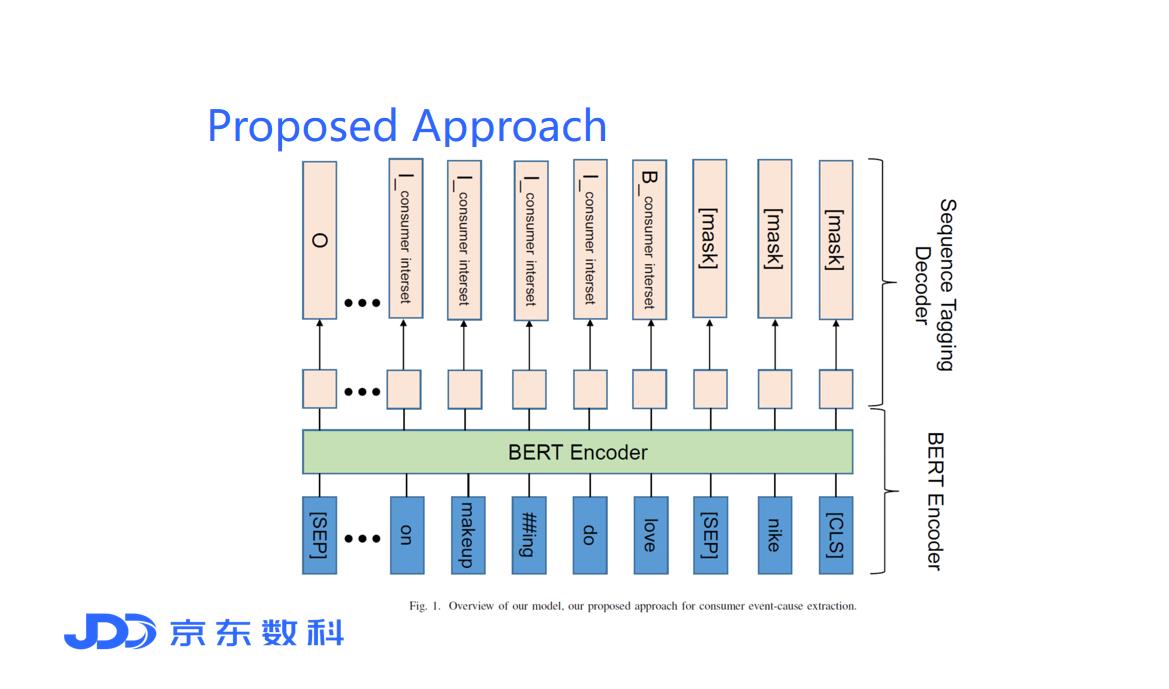
- Sequence Tagging Decoder
在2020年的ICDM竞赛中该任务增加了对多种行为类型的判断这很难用阅读理解框架来解决。竞赛的目标是为每个文本text和 brand/product提取多种行为类型和行为原因。为此我们提出了一种序列标记解码器可以同时提取多个行为类型和行为原因。
首先我们为成对的输入句子构造标记每个标记都有一个标记符如下所示
Love doing makeup on all ages,
B_{consumer interest}
I_{consumer interest} …
用这种方式我们就可以使用softmax函数独立地对每个标签进行解码得到所有可能的行为类型和行为原因对的集合。
在序列标注任务的启发下考虑邻域中标签之间的相关性并联合解码给定输入句子的最佳标签链是有益的。因此我们使用一个条件随机场CRF[5]联合建模标签序列而不是单独解码每个标签。
形式上我们使用z{z1z2····zn}来表示一个通用的输入序列其中zi是第i个单词的输入向量。y{y1y2·····yn}表示z的一个通用标签序列。yz表示z的一组可能的标签序列。序列CRF的概率模型定义了一系列条件概率py | zWb在给定z的所有可能的标签序列y上其形式如下 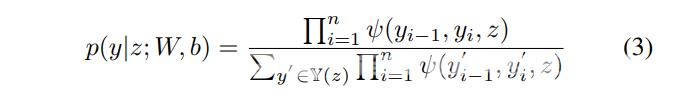 对于CRF训练我们使用最大条件似然估计。对于训练集{ziyi}似然的对数即对数似然由以下公式给出
对于CRF训练我们使用最大条件似然估计。对于训练集{ziyi}似然的对数即对数似然由以下公式给出 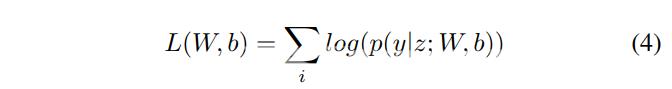 最大似然训练选择参数使对数似然LWb最大化。解码是以最大的条件概率搜索标签序列y。
最大似然训练选择参数使对数似然LWb最大化。解码是以最大的条件概率搜索标签序列y。 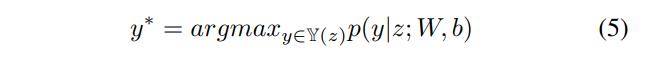 对于序列CRF模型只考虑两个连续标签之间的相互作用采用Viterbi[11]算法可以有效地解决训练和解码问题。
对于序列CRF模型只考虑两个连续标签之间的相互作用采用Viterbi[11]算法可以有效地解决训练和解码问题。
3、模型集成
 在模型集成[9]阶段我们采用了一种简单有效的方法得到了1.30%的提升如图2所示。我们采用了两步走的方法来得到最终的结果。首先确定文本边界交叉验证结果的串行化预测结果的字符位置为1其余为0。然后我们将所有的CV结果叠加到相应的位置并通过阈值将小于N的位置更改为0。
在模型集成[9]阶段我们采用了一种简单有效的方法得到了1.30%的提升如图2所示。我们采用了两步走的方法来得到最终的结果。首先确定文本边界交叉验证结果的串行化预测结果的字符位置为1其余为0。然后我们将所有的CV结果叠加到相应的位置并通过阈值将小于N的位置更改为0。
4、模型效果
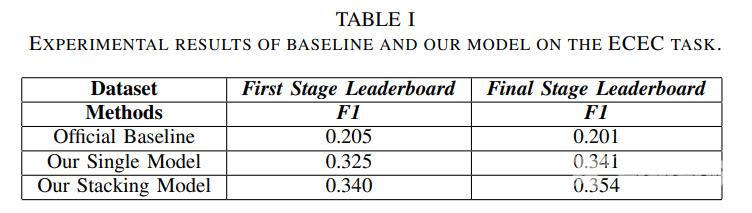
四、WorkShop其他获奖方案
在本次竞赛中来自日本的选手使用GAN完成了本次任务整体思路为是通过GAN的生成方式增加训练样本同时对GAN生成的数据标注为Fake然后将GAN的生成和BERT层一起送入Bi-LSTM层后在原有AttentionIntentionNeed PurchaseUse的基础上增加Fake标签进行预测。 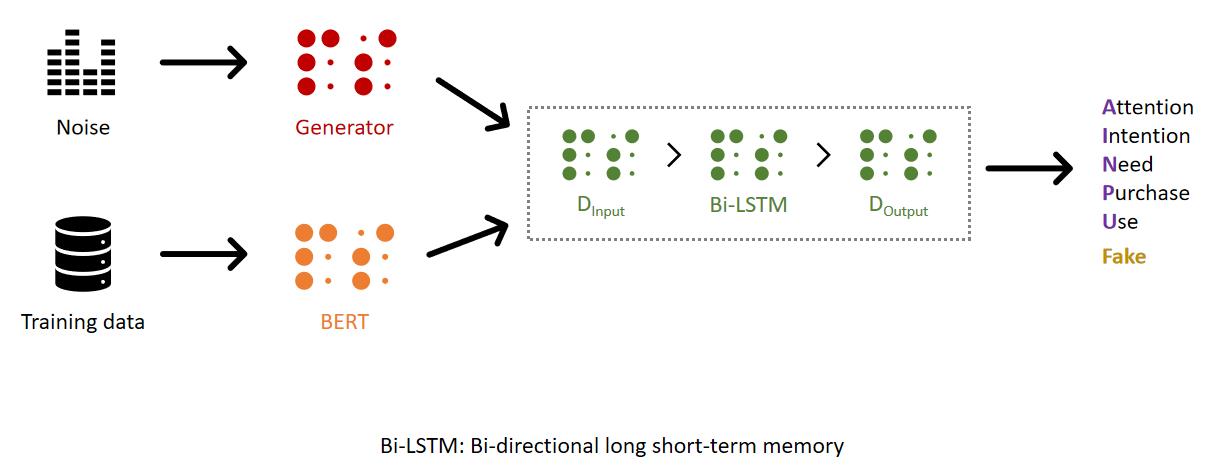
五、写在后面的话
两年的比赛经历各种顶会赛事奖杯纳入囊中但仍以赤子之心不断追逐。后需将把重心放在推荐系统及推荐算法炼丹上。在今年8月份也注册了“炼丹笔记”微信公众号主做三类内容学术界推荐算法研究解读、工业界推荐算法方案实战、数据竞赛深度炼丹技巧。欢迎算法爱好者关注共同交流成长。

最后若对数科硅谷算法团队所做的工作感兴趣的朋友们内部员工可直接咚咚搜索DOTA与本人咨询或交流。
互动讨论你在日常工作中有没有遇到类似BERT这种预训练模型上线难的问题又是怎么解决的呢模型压缩方向有过哪些经验欢迎在留言区分享你的困惑或你的见解。
参考文献 [1] Marco Rospocher, et al. ”Building event-centric knowledge graphs from news.” Journal of Web Semantics, Volumes 37–38, 2016, pp. 132-151. [2] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018. [3] Lee J, Yoon W, Kim S, et al. BioBERT: a pre-trained biomedical language representation model for biomedical text mining[J]. Bioinformatics, 2020, 36(4): 1234-1240. [4] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008. [5] Ma X, Hovy E. End-to-end sequence labeling via bi-directional lstmcnns-crf[J]. arXiv preprint arXiv:1603.01354, 2016. [6] Xia R, Ding Z. Emotion-cause pair extraction: a new task to emotion analysis in texts[J]. arXiv preprint arXiv:1906.01267, 2019. [7] Li X, Feng J, Meng Y, et al. A unified mrc framework for named entity recognition[J]. arXiv preprint arXiv:1910.11476, 2019. [8] Huang Z, Xu W, Yu K. Bidirectional LSTM-CRF models for sequence tagging[J]. arXiv preprint arXiv:1508.01991, 2015. [9] Dietterich T G. Ensemble methods in machine learning[C]//International workshop on multiple classifier systems. Springer, Berlin, Heidelberg, 2000: 1-15. [10] Gooding R Z, Kinicki A J. Interpreting event causes: The complementary role of categorization and attribution processes[J]. Journal of Management Studies, 1995, 32(1): 1-22. [11] Viterbi A J. A personal history of the Viterbi algorithm[J]. IEEE Signal Processing Magazine, 2006, 23(4): 120-142.
更多竞赛技术方案 数字中国创新大赛 数字政府赛道 算法赛 冠军 Microsoft DiggSci 科学数据挖掘大赛 亚军 京东JDATA算法大赛 绝对语义识别挑战赛 季军 “中国法研杯”司法人工智能挑战赛 三等奖
