Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度。
例 : 假设要根据同学的名字查找对应的成绩,如果用list实现,需要两个list:
names = ['Michael', 'Bob', 'Tracy'] scores = [95, 75, 85]登录后复制
定义一个名字,要查找对应的成绩,就先要在names中找到对应的位置,再从scores取出对应的成绩,list越长,耗时越长。
如果用dict实现,只需要一个“名字”-“成绩”的对照表,直接根据名字查找成绩,无论这个表有多大,查找速度都不会变慢。
例:
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
print(d['Michael'])登录后复制
dict就是在字典的索引表里(比如部首表)查这个字对应的页码,然后直接翻到该页,找到这个字。无论找哪个字,这种查找速度都非常快,不会随着字典大小的增加而变慢。
把数据放入dict的方法,除了初始化时指定外,还可以通过key放入:
d['Adam'] = 67 print(d['Adam'])登录后复制

由于一个key只能对应一个value,所以,多次对一个key放入value,后面的值会把前面的值冲掉:
d['Jack'] = 90 d['Jack'] = 88 print(d['Jack']) #多次对一个key放入value,后面的值会把前面的值冲掉:显示后面修改的值登录后复制

如果key不存在,dict就会报错:
print( d['Thomas'])登录后复制

print('Thomas' in d)登录后复制
d.get('Thomas')
print(d.get('Thomas', -1))登录后复制
注:
返回None的时候Python的交互式命令行不显示结果。
要删除一个key,用pop(key)方法,对应的value也会从dict中删除:
d.pop('Bob')
print(d)登录后复制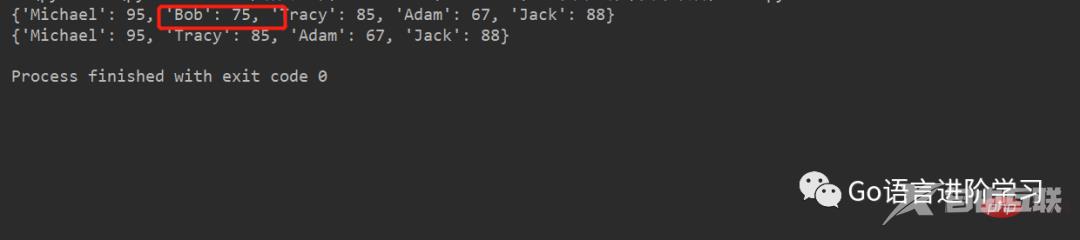
查找和插入的速度极快,不会随着key的增加而增加;
需要占用大量的内存,内存浪费多。而list相反:
查找和插入的时间随着元素的增加而增加;
占用空间小,浪费内存很少。所以,dict是用空间来换取时间的一种方法。
set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。
要创建一个set,需要提供一个list作为输入集合:
s = set([1, 2, 3]) print(s)登录后复制

传入的参数[1, 2, 3]是一个list,而显示的{1, 2, 3}只是告诉这个set内部有1,2,3这3个元素,显示的顺序也不表示set是有序的。。
重复元素在set中自动被过滤:
s = set([1, 1, 2, 2, 3, 3]) print(s)登录后复制
通过add(key)方法可以添加元素到set中,可以重复添加,但不会有效果:
s.add(4)
s{1, 2, 3, 4}登录后复制
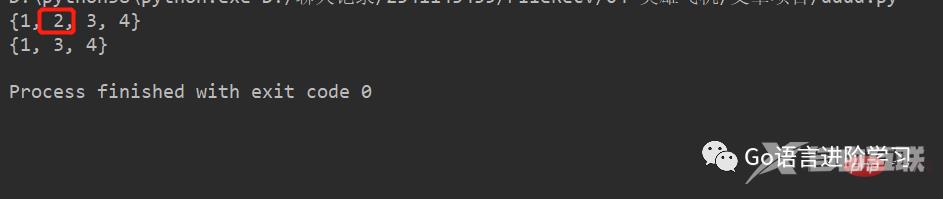
通过remove(key)方法可以删除元素:
s.remove(2) print(s)登录后复制
set可以看成数学意义上的无序和无重复元素的集合,因此,两个set可以做数学意义上的交集、并集等操作:
s1 = set([1, 2, 3]) s2 = set([2, 3, 4]) print(s1 & s2) print(s1 | s2)登录后复制

仅在于没有存储对应的value,但是,set的原理和dict一样,所以,同样不可以放入可变对象,因为无法判断两个可变对象是否相等,也就无法保证set内部“不会有重复元素”。试试把list放入set,看看是否会报错。
str是不变对象,而list是可变对象。对于可变对象,比如list,对list进行操作,list内部的内容是会变化的。
例:
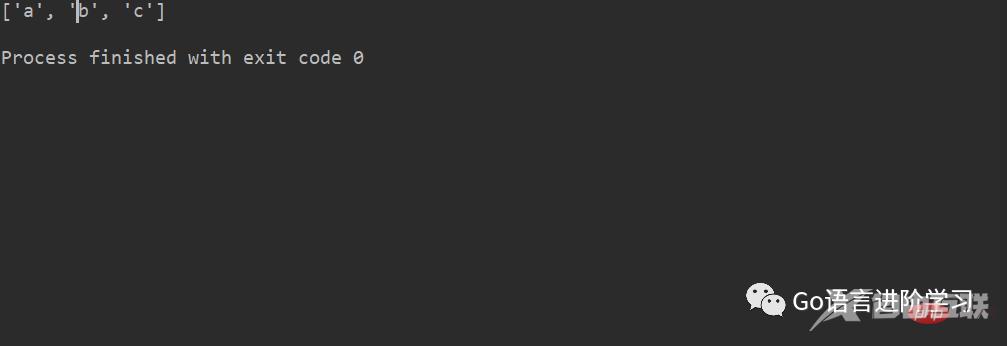
a = ['c', 'b', 'a'] a.sort() # a['a', 'b', 'c'] print(a)登录后复制
而对于不可变对象,比如str,对str进行操作呢:
a = 'abc'
b = a.replace('a', 'A')
print(b)
print(a)登录后复制
注:
对于不变对象来说,调用对象自身的任意方法,也不会改变该对象自身的内容。相反,这些方法会创建新的对象并返回,这样,就保证了不可变对象本身永远是不可变的。
本文基于Python基础,介绍了如何去使用dict和set, 使用key-value存储结构的dict在Python中非常有用,选择不可变对象作为key很重要,最常用的key是字符串。
【文章出处:香港多ip站群服务器 http://www.558idc.com/hkzq.html提供,感恩】