这里举一个通信机制的例子:我们都很熟悉通信这个词,比如一个人想给他的女友打电话。一旦通话建立,便会形成一个隐式的队列(请注意这个术语)。此时这个人就会通过对话的方式不停的将信息告诉女友,而这个人的女友也是在倾听着。我认为在大多数情况下,情况可能是倒过来的。
这里可以将他们两个人比作是两个进程,"这个人"的进程需要将信息发送给"女友"的进程,就需要一个队列的帮助。由于女友需要时刻接收队列中的信息,因此她可以同时进行其他事情,这意味着两个进程之间的通信主要依赖于队列。
这个队列可以支持发送消息与接收消息,“这个人"负责发送消息,反之"女友” 负责的是接收消息。
既然队列才是重点,那么来看一下队列要如何创建。
队列的创建 - multiprocessing依然使用 multiprocessing 模块,调用该模块的 Queue 函数来实现队列的创建。
Queue 函数功能介绍:调用 Queue 可以创建队列;它有一个参数 mac_count 代表队列最大可以创建多少信息,如果不传默认是无限长度。实例化一个队列对象之后,需要操作这个队列的对象进行放入与取出数据。
进程之间通信的方法put 函数功能介绍:将数据传入。它有一个参数 message ,是一个字符串类型。
get 函数功能介绍:用来接收队列中的数据。(其实这里就是一个常用的json场景,有很多的数据传输都是 字符串 的,队列的插入与获取就是使用的字符串,所以 json 就非常适用这个场景。)
接下来就来练习一下 队列的使用 。
进程间的通信 - 队列演示案例代码示例如下:
# coding:utf-8
import json
import multiprocessing
class Work(object): # 定义一个 Work 类
def __init__(self, queue): # 构造函数传入一个 '队列对象' --> queue
self.queue = queue
def send(self, message): # 定义一个 send(发送) 函数,传入 message
# [这里有个隐藏的bug,就是只判断了传入的是否字符串类型;如果传入的是函数、类、集合等依然会报错]
if not isinstance(message, str): # 判断传入的 message 是否为字符串,若不是,则进行 json 序列化
message = json.dumps(message)
self.queue.put(message) # 利用 queue 的队列实例化对象将 message 发送出去
def receive(self): # 定义一个 receive(接收) 函数,不需传入参数,但是因为接收是一个源源不断的过程,所以需要使用 while 循环
while 1:
result = self.queue.get() # 获取 '队列对象' --> queue 传入的message
# 由于我们接收的 message 可能不是一个字符串,所以要进程异常的捕获
try: # 如果传入的 message 符合 JSON 格式将赋值给 res ;若不符合,则直接使用 result 赋值 res
res = json.loads(result)
except:
res = result
print('接收到的信息为:{}'.format(res))
if __name__ == '__main__':
queue = multiprocessing.Queue()
work = Work(queue)
send = multiprocessing.Process(target=work.send, args=({'message': '这是一条测试的消息'},))
receive = multiprocessing.Process(target=work.receive)
send.start()
receive.start()使用队列建立进程间通信遇到的异常
但是这里会出现一个 报错,如下图:
报错截图示例如下:
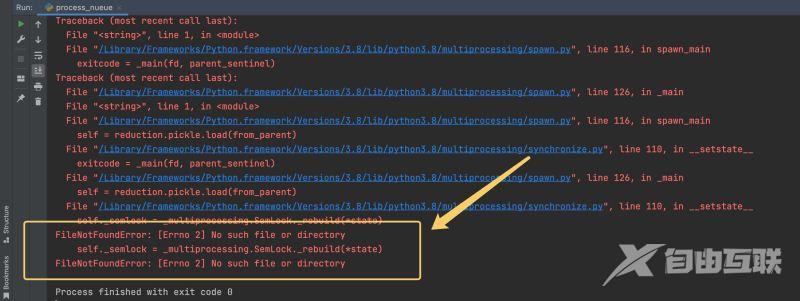
这里的报错提示是 文件没有被发现的意思 。其实这里是我们使用 队列做 put() 和 get()的时候 有一把无形的锁加了上去,就是上图中圈中的 .SemLock 。我们不需要去关心造成这个错误的具体原因,要解决这个问题其实也很简单。
FileNotFoundError: [Errno 2] No such file or directory 异常的解决
需要阻塞进程的只是 send 或 receive 子进程中的一个,只要阻塞其中一个即可,这是理论上的情况。但是我们的 receive子进程是一个 while循环,它会一直执行,所以只需要给 send 子进程加上一个 join 即可。
解决示意图如下:
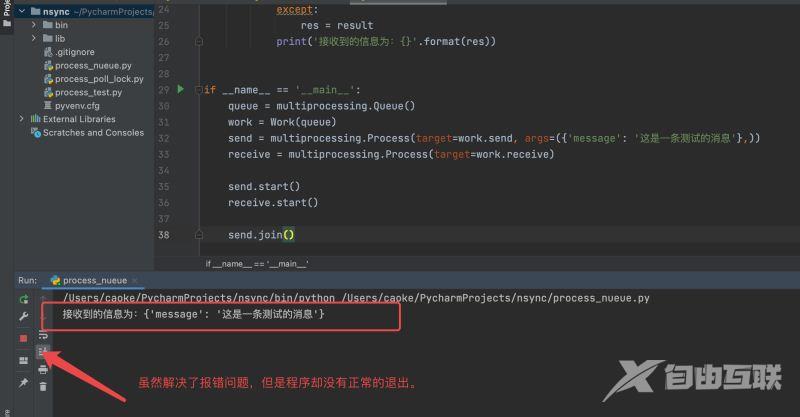
PS:虽然解决了报错问题,但是程序没有正常退出。
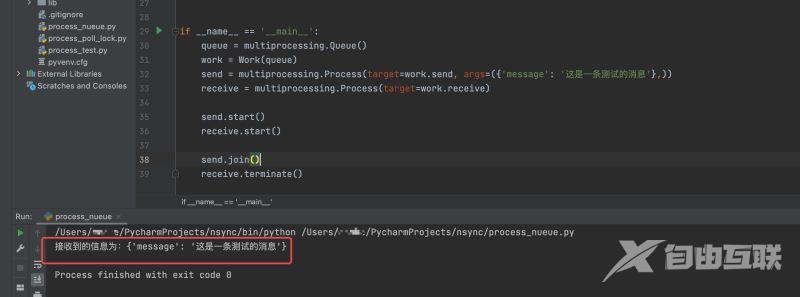
实际上由于我们的 receive 进程是个 while循环,并不知道要处理到什么时候,没有办法立刻终止。所以我们需要在 receive 进程 使用 terminate() 函数终结接收端。
运行结果如下:
新建一个函数,写入 for循环 模拟批量添加要发送的消息
然后再给这个模拟批量发送数据的函数添加一个线程。
示例代码如下:
# coding:utf-8
import json
import time
import multiprocessing
class Work(object): # 定义一个 Work 类
def __init__(self, queue): # 构造函数传入一个 '队列对象' --> queue
self.queue = queue
def send(self, message): # 定义一个 send(发送) 函数,传入 message
# [这里有个隐藏的bug,就是只判断了传入的是否字符串类型;如果传入的是函数、类、集合等依然会报错]
if not isinstance(message, str): # 判断传入的 message 是否为字符串,若不是,则进行 json 序列化
message = json.dumps(message)
self.queue.put(message) # 利用 queue 的队列实例化对象将 message 发送出去
def send_all(self): # 定义一个 send_all(发送)函数,然后通过for循环模拟批量发送的 message
for i in range(20):
self.queue.put('第 {} 次循环,发送的消息为:{}'.format(i, i))
time.sleep(1)
def receive(self): # 定义一个 receive(接收) 函数,不需传入参数,但是因为接收是一个源源不断的过程,所以需要使用 while 循环
while 1:
result = self.queue.get() # 获取 '队列对象' --> queue 传入的message
# 由于我们接收的 message 可能不是一个字符串,所以要进程异常的捕获
try: # 如果传入的 message 符合 JSON 格式将赋值给 res ;若不符合,则直接使用 result 赋值 res
res = json.loads(result)
except:
res = result
print('接收到的信息为:{}'.format(res))
if __name__ == '__main__':
queue = multiprocessing.Queue()
work = Work(queue)
send = multiprocessing.Process(target=work.send, args=({'message': '这是一条测试的消息'},))
receive = multiprocessing.Process(target=work.receive)
send_all = multiprocessing.Process(target=work.send_all,)
send_all.start() # 这里因为 send 只执行了1次,然后就结束了。而 send_all 却要循环20次,它的执行时间是最长的,信息也是发送的最多的
send.start()
receive.start()
# send.join() # 使用 send 的阻塞会造成 send_all 循环还未结束 ,receive.terminate() 函数接收端就会终结。
send_all.join() # 所以我们只需要阻塞最长使用率的进程就可以了
receive.terminate()运行结果如下:
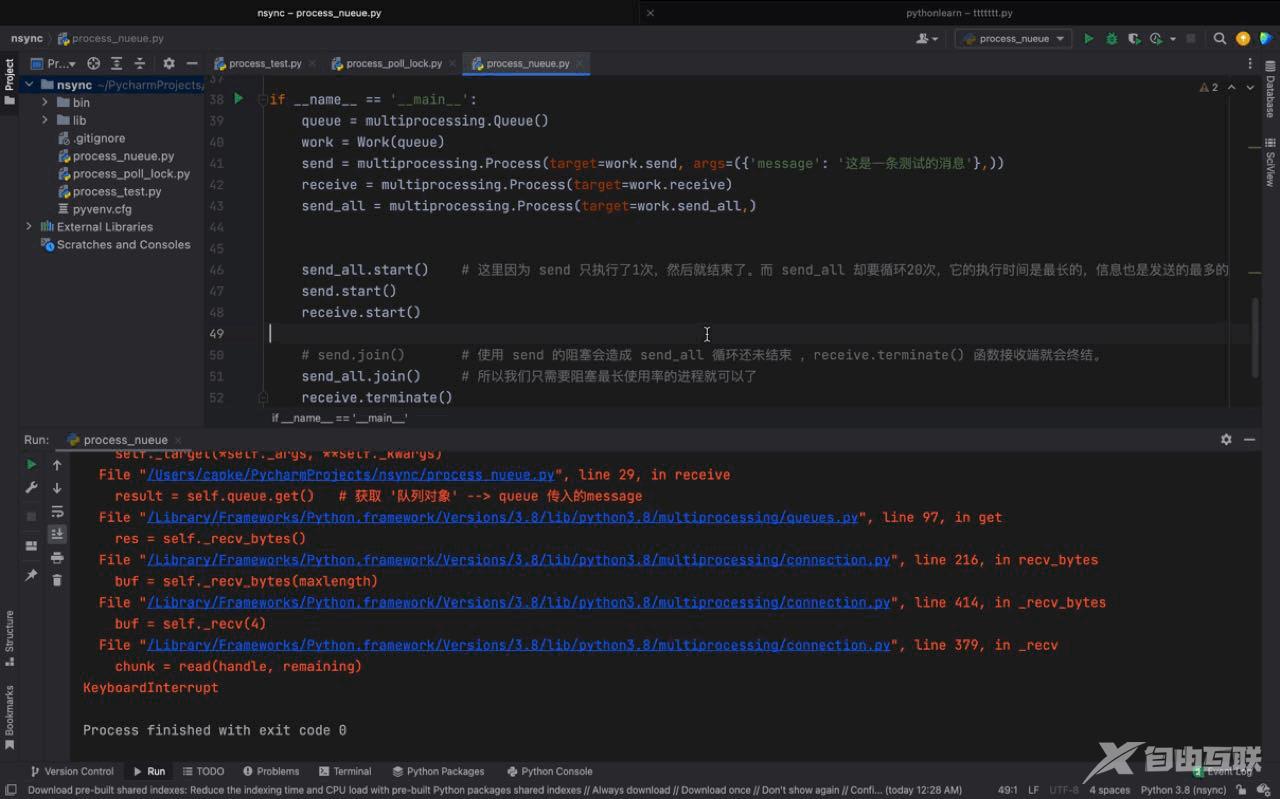
从上图中我们可以看到 send 与 send_all 两个进程都可以通过 queue这个实例化的 Queue 对象发送消息,同样的 receive接收函数也会将两个进程传入的 message 打印输出出来。
小节在这一章节,我们成功运用队列实现了跨进程通信,同时也掌握了队列的操作技巧。一个队列中,有一端(这里我们演示的是 send端)通过 put方法实现添加相关的信息,另一端使用 get 方法获取相关的信息;两个进程相互配合达到一个进程通信的效果。
除了队列,进程之间还可以使用管道、信号量和共享内存等方式进行通信,如果您感兴趣,可以了解一下这些方法。可以自行拓展一下。
进程间通信的其他方式 - 补充python提供了多种进程通信的方式,包括信号,管道,消息队列,信号量,共享内存,socket等
主要Queue和Pipe这两种方式,Queue用于多个进程间实现通信,Pipe是两个进程的通信。
1.管道:分为匿名管道和命名管道
匿名管道:在内核中申请一块固定大小的缓冲区,程序拥有写入和读取的权利,一般使用fock函数实现父子进程的通信
命名管道:在内存中申请一块固定大小的缓冲区,程序拥有写入和读取的权利,没有血缘关系的进程也可以进程间通信
特点:面向字节流;生命周期随内核;自带同步互斥机制;半双工,单向通信,两个管道实现双向通信
一种重写方式是:在操作系统内核中建立一个队列,队列中包含多个数据报元素,多个进程可以通过特定句柄来访问该队列。消息队列可以用来将数据从一个进程发送到另一个进程。每个数据块都被认为是有一个类型,接收者进程接收的数据块可以有不同的类型。消息队列也有管道一样的不足,就是每个消息的最大长度是有上限的,每个消息队列的总的字节数是有上限的,系统上消息队列的总数也有一个上限
特点:消息队列可以被认为是一个全局的一个链表,链表节点中存放着数据报的类型和内容,有消息队列的标识符进行标记;消息队列允许一个或多个进程写入或读取消息;消息队列的生命周期随内核;消息队列可实现双向通信
3.信号量:在内核中创建一个信号量集合(本质上是数组),数组的元素(信号量)都是1,使用P操作进行-1,使用V操作+1
P(sv):如果sv的值大于零,就给它减1;如果它的值为零,就挂起该程序的执行
V(sv):如果有其他进程因等待sv而被挂起,就让它恢复运行,如果没有进程因等待sv而挂起,就给它加1
PV操作用于同一个进程,实现互斥;PV操作用于不同进程,实现同步
功能:对临界资源进行保护
4.共享内存:将同一块物理内存一块映射到不同的进程的虚拟地址空间中,实现不同进程间对同一资源的共享。说到进程间通信方式,共享内存可以说是最有用的,也是最快速的IPC形式
特点:不同从用户态到内核态的频繁切换和拷贝数据,直接从内存中读取就可以;共享内存是临界资源,所以需要操作时必须要保证原子性。使用信号量或者互斥锁都可以.
【感谢龙石为本站提供数据采集系统 http://www.longshidata.com/pages/government.html 】