PHP MySQL栏目讲解如何实现千万级数据处理

推荐(免费):PHP MySQL
mysql分表思路
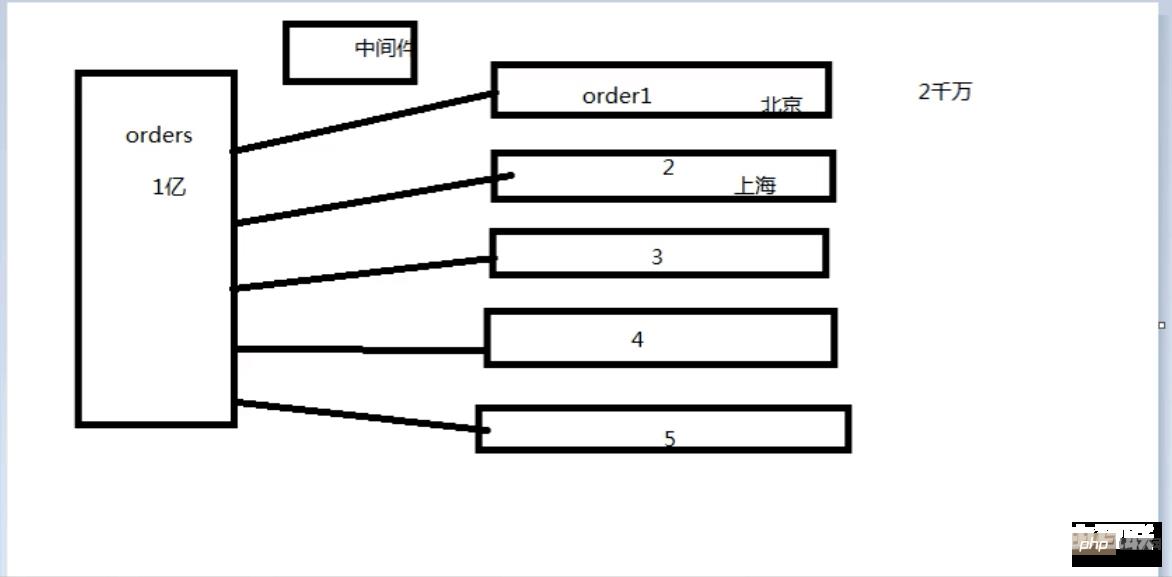
一张一亿的订单表,可以分成五张表,这样每张表就只有两千万数据,分担了原来一张表的压力,分表需要根据某个条件进行分,这里可以根据地区来分表,需要一个中间件来控制到底是去哪张表去找到自己想要的数据。
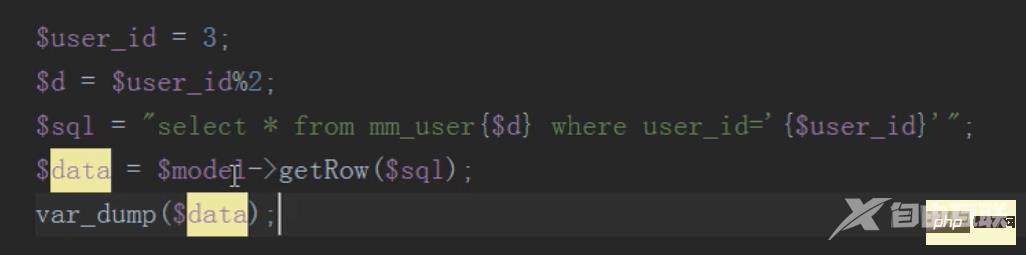
中间件:根据主表的自增id作为中间件(什么样的字段适合做中间件?要具备唯一性)
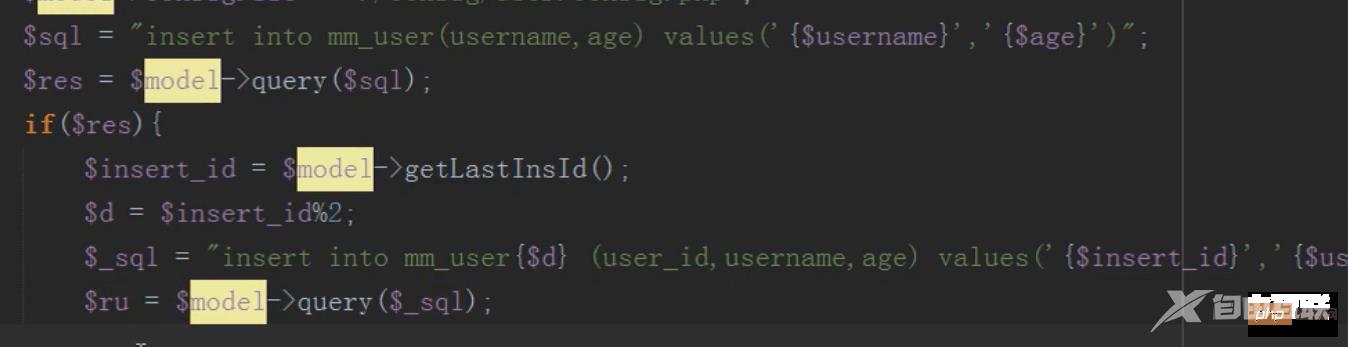
怎么分发?主表插入之后返回一个id,根据这个id和表的数量进行取模,余数是几就往哪张表中插入数据。
注意:子表中的id要与主表的id保持一致
以后只有插入操作会用到主表,修改,删除,读取,均不需要用到主表
redis消息队列
1,什么是消息队列?
消息传播过程中保存消息的容器
2,消息队列产生的历史原因

消息队列的特点:先进先出
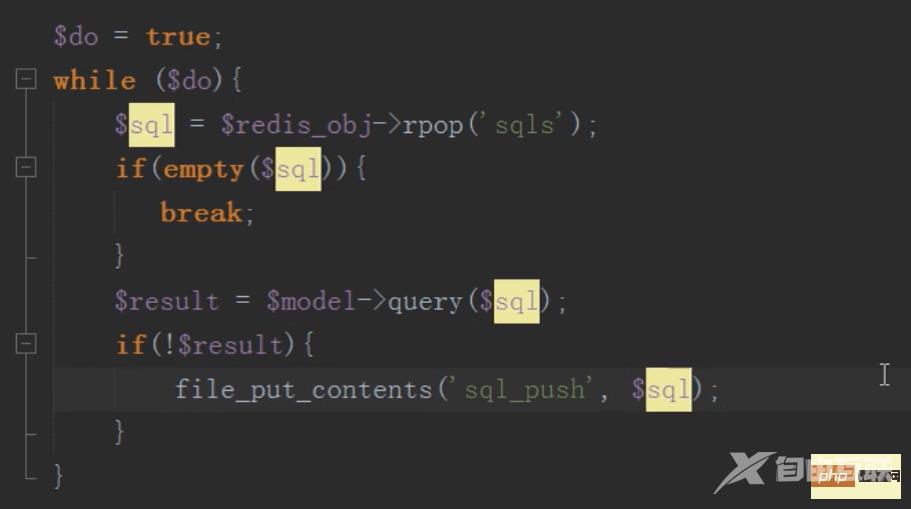
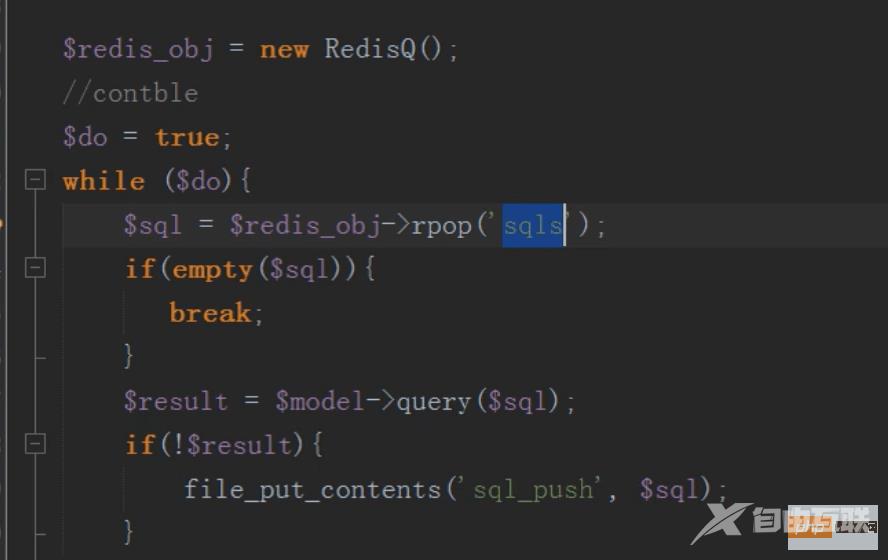
把要执行的sql语句先保存在消息队列中,然后依次按照顺利异步插入的数据库中
应用:新浪,把瞬间的评论先放入消息队列,然后通过定时任务把消息队列里面的sql语句依次插入到数据库中
修改
操作子表进行修改
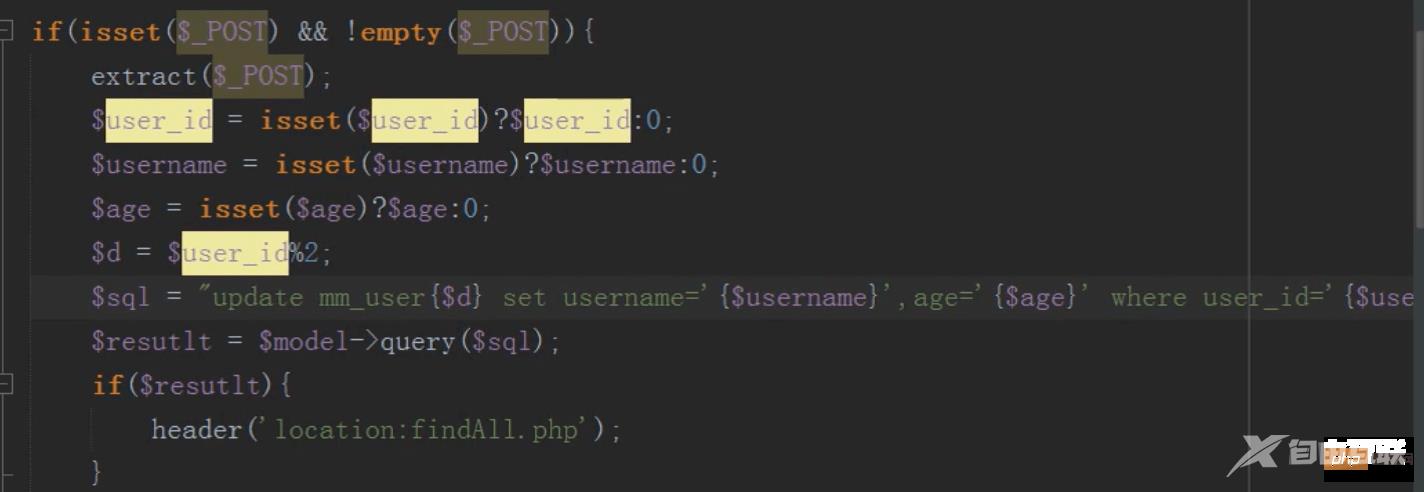
这样修改有一个问题,主表和子表的数据会出现不一致,如何让主表和字表数据一致?
redis队列保持主表子表数据一致
修改完成后将要修改主表的数据,存入redis队列中
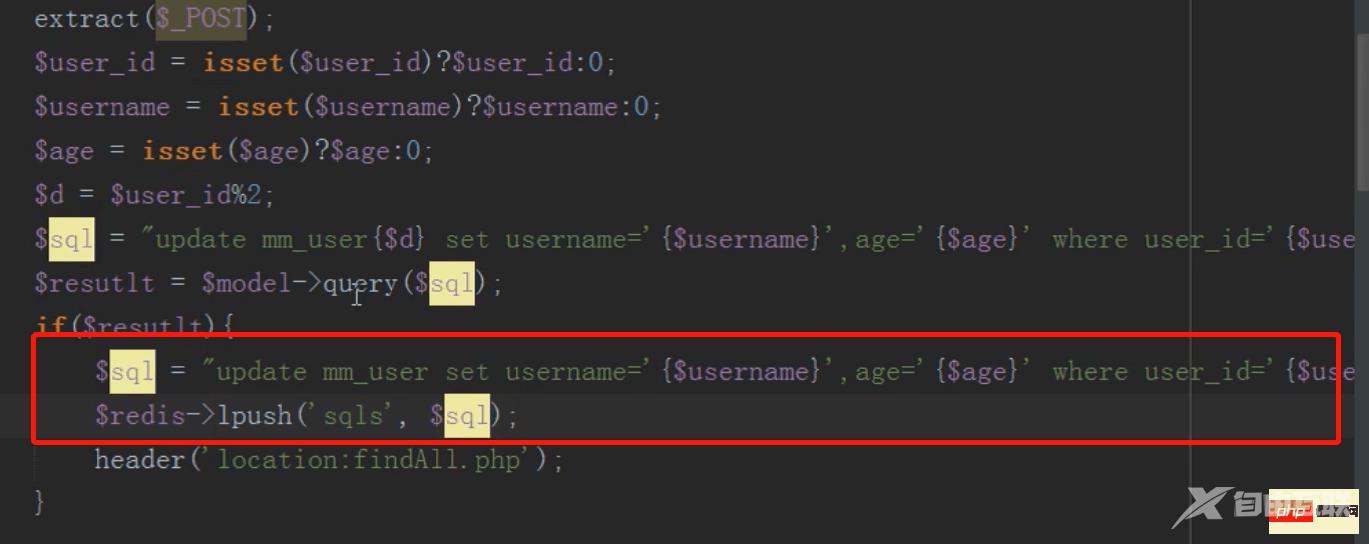
然后linux定时任务(contble)循环执行redis队列中的sql语句,同步更新主表的内容
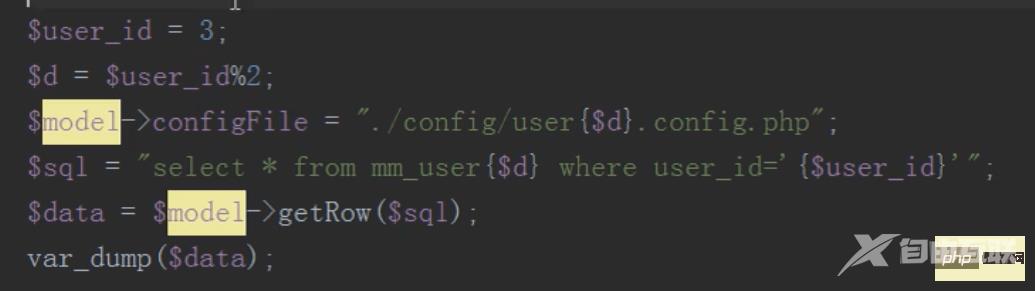
mysql分布式之分表(查,删)
查询只需要查询子表,不要查询总表
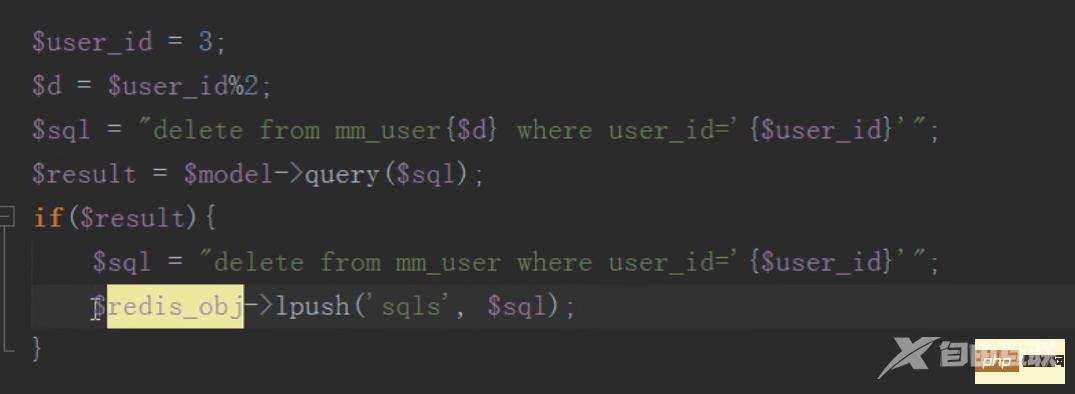
删除,先根据id找到要删除的子表,然后删除,然后往消息队列中压入一条删除总表数据的sql语句
然后执行定时任务删除总表数据
定时任务:
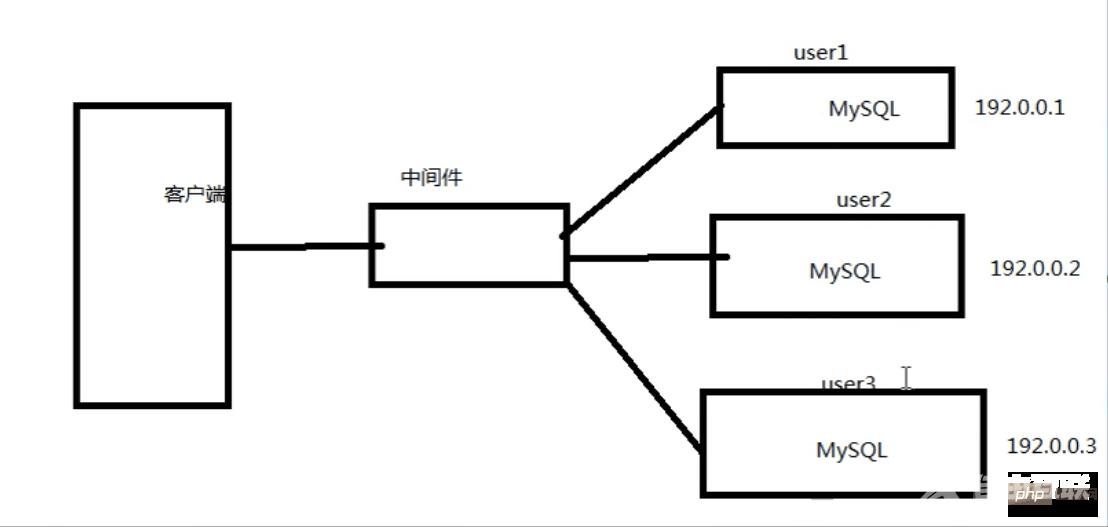
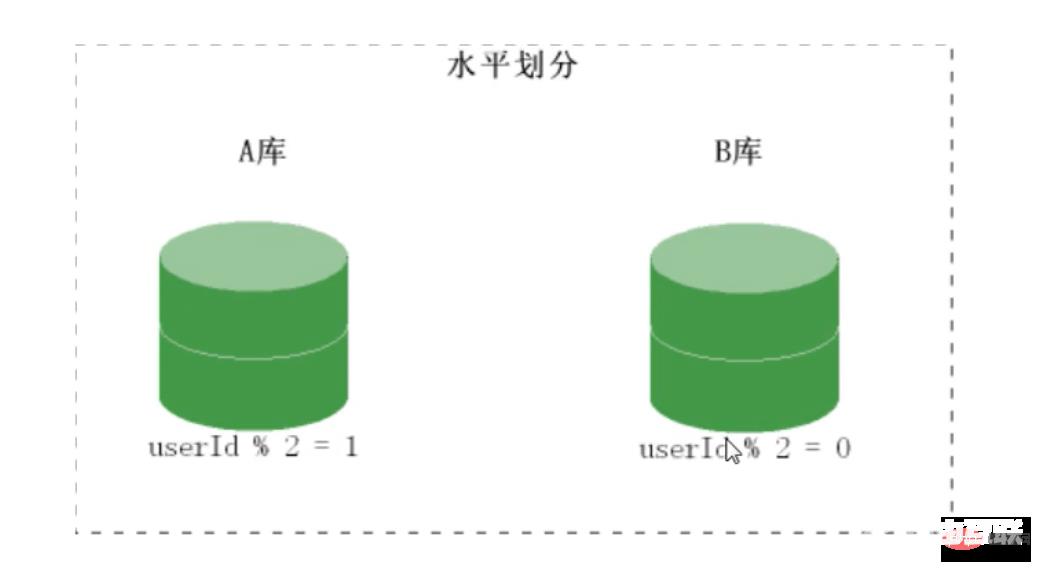
mysql分布式之分库
分库思路
分库原理图:
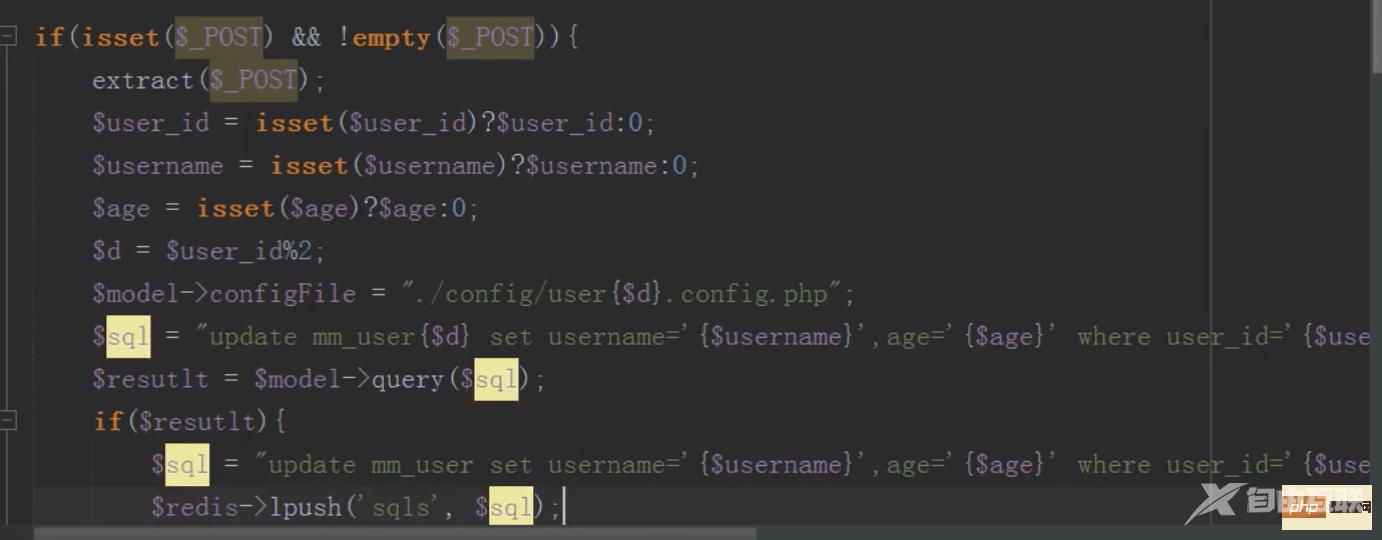
mysql分布式之分库(增)
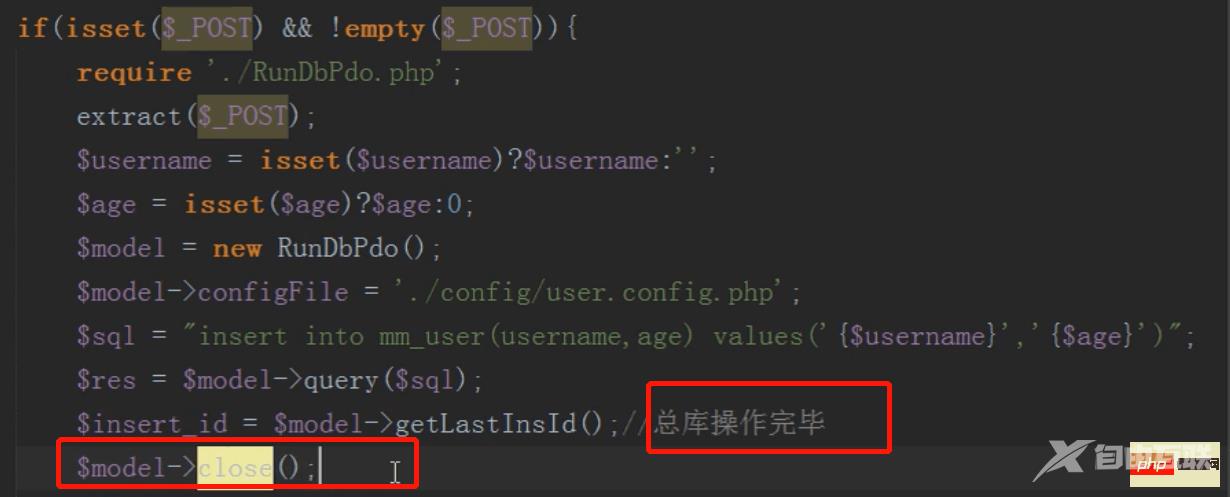
注意:操作完一个数据库一定要把数据库连接关闭,不然mysql会以为一直连接的同一个数据库
还是取模确定加载哪个配置文件连接哪个数据库
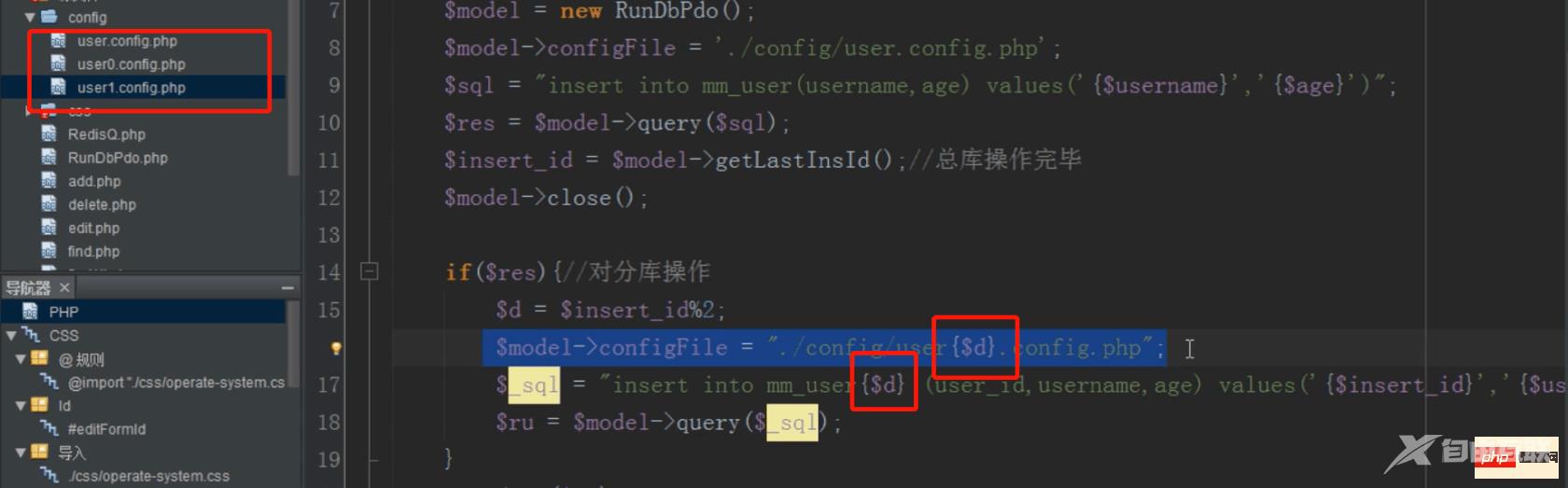
mysql分布式之分库(改)
原理同新增
mysql分布式之分库(查,删)
原理类似
删除
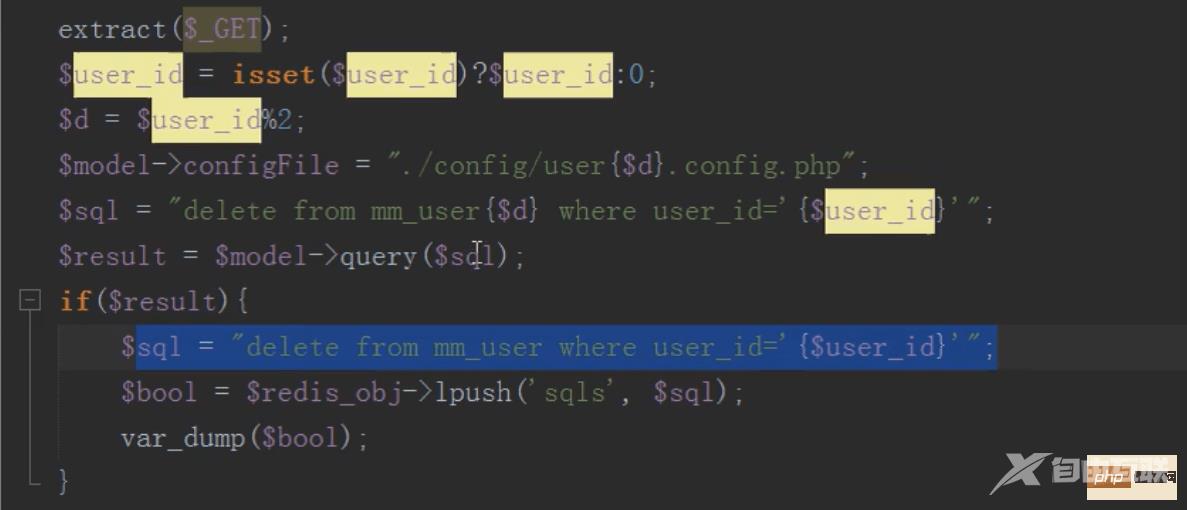
执行队列
mysql分布式之缓存(memcache)的应用
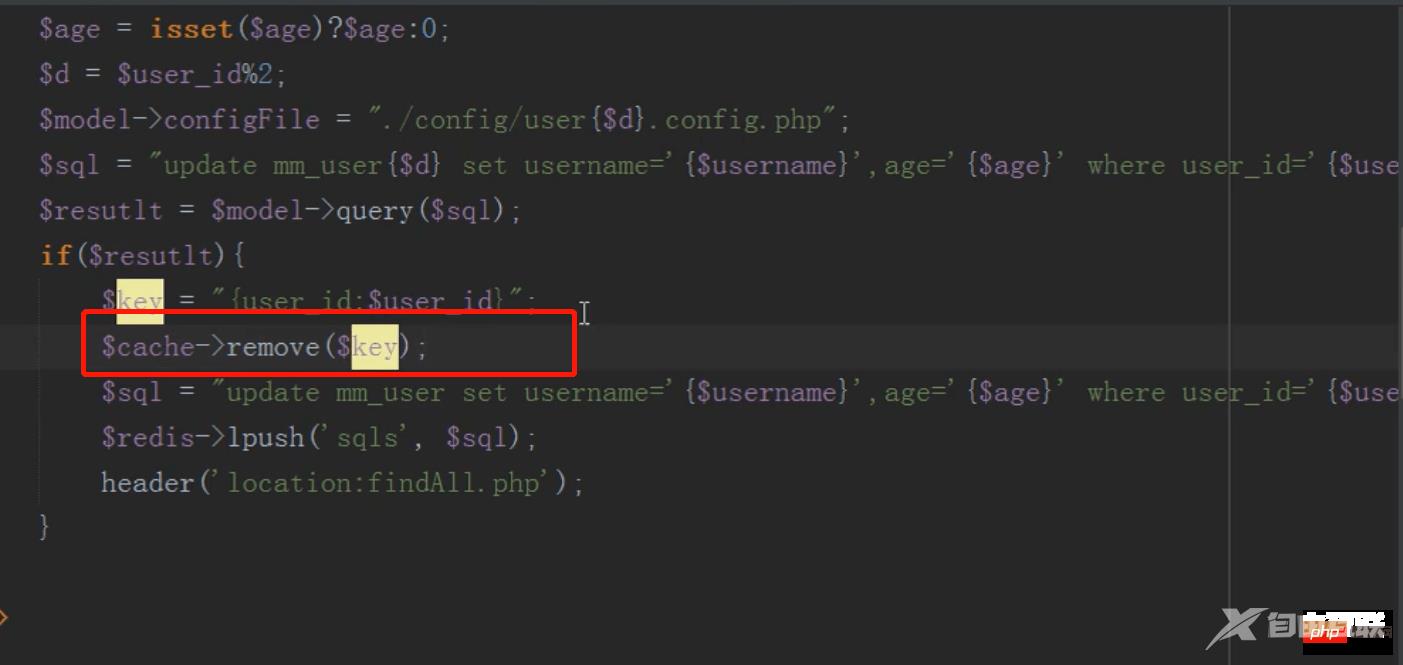
将数据放入缓存中,节省数据库开销,先去缓存中查,如果有直接取出,如果没有,去数据库查,然后存入缓存中
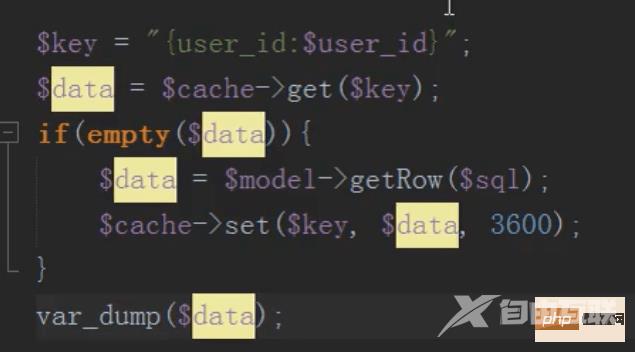
在编辑信息之后需要删除缓存,不然一直读取的是缓存的数据而不是修改过的数据
【转自:外国服务器 http://www.558idc.com/shsgf.html转载请说明出处】