字符串 是 Redis 最基本的数据类型,不仅所有 key 都是字符串类型,其它几种数据类型构成的元素也是字符串。注意字符串的长度不能超过 512 M。
首先是谁规定不能超过 512 M?或者为什么不能超过 512 M?
// 源码定义(检查字符串长度)
static int checkStringLength(redisClient *c, long long size) {
if (size > 512*1024*1024) {
addReplyError(c,"string exceeds maximum allowed size (512MB)");
return REDIS_ERR;
}
return REDIS_OK;
}由源码检查固定不能超过 512 M。
来看一下 redis 字符串的结构体:
struct sdshdr{
// 记录 buf 数组中已使用字节的数量
// 等于 SDS 所保存字符串的长度
int len;
// 记录 buf 数组中未使用字节的数量
int free;
// 字节数组,用于保存字符串
char buf[];
}由此可以直接看出,int 为 32位,那么最大应该可以支持 4G 的字符串,但是实际情况并非如此。
为了找到为什么不能超过 512 M,发现了一个官方的回答:
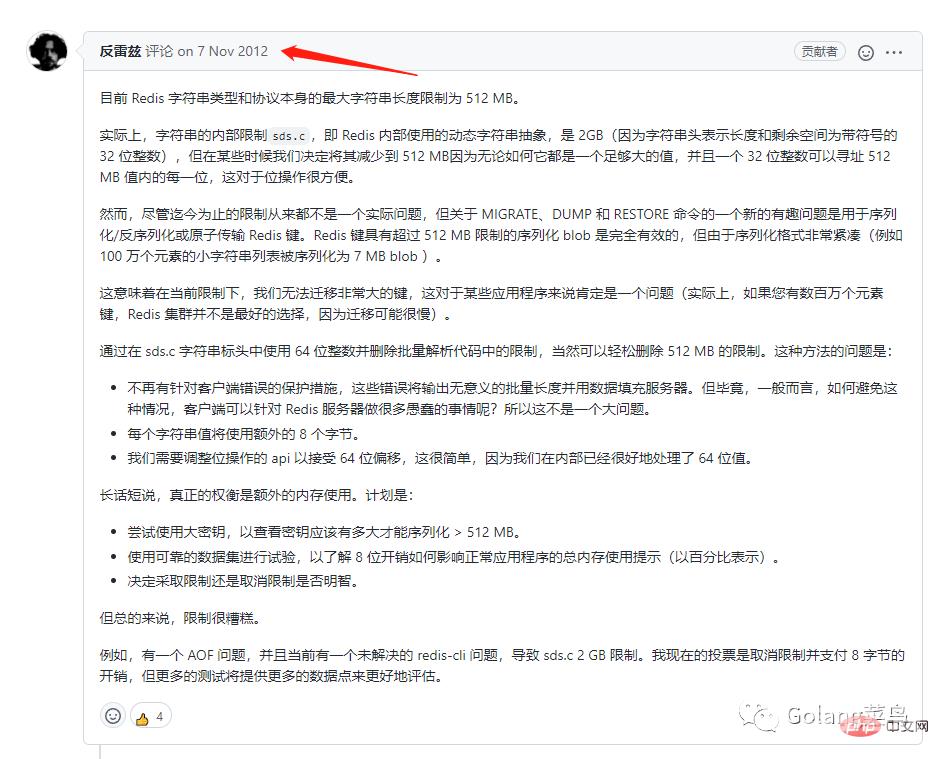
然后我才发现,我看过的 redis 资料已经过时了!
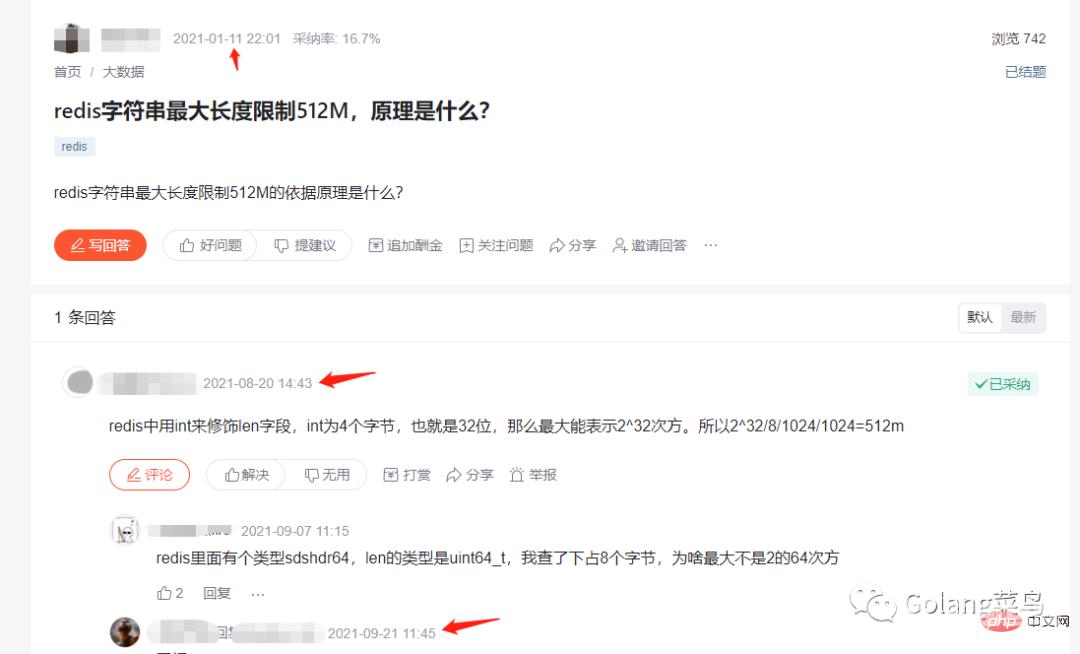
看看,还有人也中招了。这个讨论的版本都是3.2 之前的了。
话不多说,继续学习 redis5.0 版本的资料。不过之前学习了的也没事,我们可以一起来看下 redis 的字符串是怎么优化的。
用如下结构来存储长度小于32的短字符串:
struct __attribute__((__packed__)) sdshdr5 {
unsigned char flags; /* 低3位存储类型,高5位存储长度*/
char buf[]; /* 柔性数组,存放实际内容*/
}sdshdr5 结构中,flags占1个字节,其低3位(bit)表示type,高5位(bit)表示长度,能表示的长度区间为0~31(25-1), flags后面就是字符串的内容。
而对于长度大于31的字符串,这个结构就不够用了,所以对于不同长度的字符串,有不同的处理方式:
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};可以看到,这4种结构的成员变量类似,唯一的区别是len和alloc的类型不同。
结构体中4个字段的具体含义分别如下:
1)len:表示buf中已占用字节数。
2)alloc:表示buf中已分配字节数,不同于free,记录的是为buf分配的总长度。
3)flags:标识当前结构体的类型,低3位用作标识位,高5位预留。
4)buf:柔性数组,真正存储字符串的数据空间。
创建字符串的过程:Redis通过sdsnewlen函数创建SDS。在函数中会根据字符串长度选择合适的类型,初始化完相应的统计值后,返回指向字符串内容的指针,根据字符串长度选择不同的类型。
对于sdshdr5类型,在创建空字符串时会强制转换为sdshdr8。原因可能是创建空字符串后,其内容可能会频繁更新而引发扩容,故创建时直接创建为sdshdr8。
拼接字符串:sdscatsds是暴露给上层的方法,其最终调用的是sdscatlen。由于其中可能涉及SDS的扩容,sdscatlen中调用sdsMakeRoomFor对带拼接的字符串s容量做检查,若无须扩容则直接返回s;若需要扩容,则返回扩容好的新字符串s。函数中的len、curlen等长度值是不含结束符的,而拼接时用memcpy将两个字符串拼接在一起,指定了相关长度,故该过程保证了二进制安全。最后需要加上结束符。
字符串扩容若sds中剩余空闲长度avail大于新增内容的长度addlen,直接在柔性数组buf末尾追加即可,无须扩容。
若sds中剩余空闲长度avail小于或等于新增内容的长度addlen,则分情况讨论:新增后总长度len+addlen<1MB的,按新长度的2倍扩容;新增后总长度len+addlen>1MB的,按新长度加上1MB扩容。
最后根据新长度重新选取存储类型,并分配空间。此处若无须更改类型,通过realloc扩大柔性数组即可;否则需要重新开辟内存,并将原字符串的buf内容移动到新位置。
字符串大致就这些内容了。
在 5.0 的版本中,没有什么字符串 512M 的限制,对于字符串的处理方式,根据不同类型处理方式不同,更加节约内存;
【感谢数据中台厂商龙石数据为本站提供 http://www.longshidata.com/pages/government.html,,感恩 】