因为工作上的需要,skidu最近这几周都在折腾瀑布流这玩意。
截止到本日志发布日期,主要功能已基本实现,整理一下实现过程以及其中遇到的一些问题吧:)
最终目的是实现瀑布流+无限拖拽的页面效果
先上局部效果图:
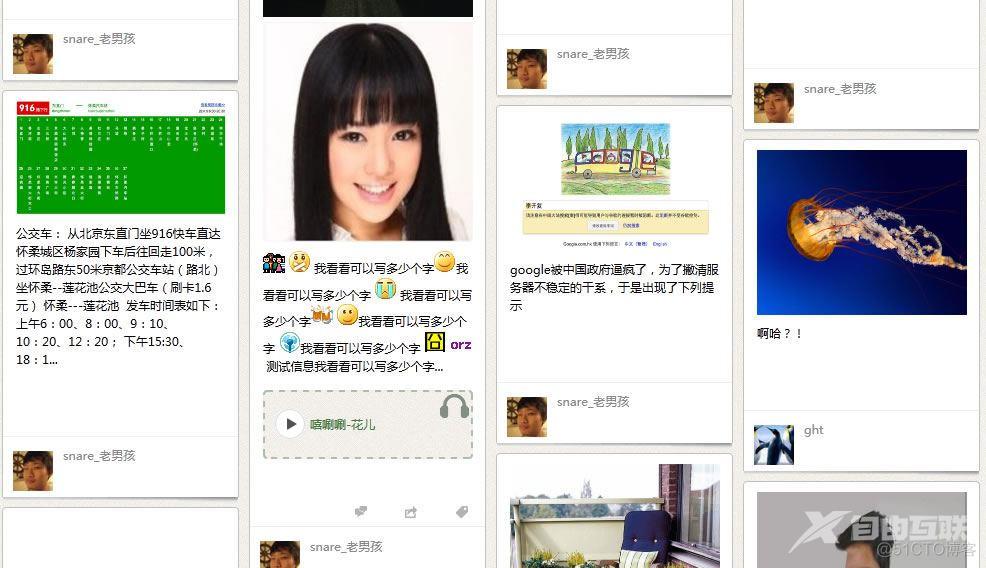
====用到的插件====
jQuery jQuery.Masonry
因为skidu本人js玩的并不太好,很是依赖于jQuery,所以这次任务义无反顾的选择了通过使用现有jQuery插件来完成。
====大致思路====
首次加载:页面加载时,通过php向页面以json格式传递一组数据,然后在前端生成每一条信息的卡片样式并通过插件实现瀑布流的布局效果
滚动请求:通过js监听浏览器滚动条的位置,当滚动条移动到预设位置的时候产生ajax请求后台php获得新的数据并插入到当前瀑布流信息中
====实现步骤====
下载前往官网本插件;
因为是使用插件来实现,所以这里就直接说本文提到的这个插件的实现方法了,之前skidu也尝试过其他方法来实现,这里就不一一描述了。
首先,我们需要定义一个主体容器用来放置所有信息卡片。
这里,这个主容器我们命名为demo,每一个卡片命名为为col,并设置css样式float为left。
导入插件后,我们的准备工作就完成了。
< script type = "text/javascript" src = "http://code.jquery.com/jquery-1.7.2.min.js" ></ script >
< script type = "text/javascript" src = "http://masonry.desandro.com/jquery.masonry.min.js" ></ script >
< style >
.col{ float:left; }
</ style >
< div id = "demo" >
< div class = "col" ></ div >
< div class = "col" ></ div >
< div class = "col" ></ div >
< div class = "col" ></ div >
< div class = "col" ></ div >
</ div >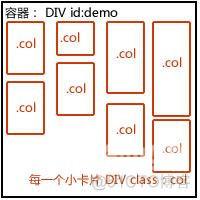
接下来,我们开始使用插件来实现瀑布流布局吧~
下面贴出skidu使用的配置信息,带口头版注释,相信大家都能看懂
$( "#demo" ).masonry({ //指定瀑布流主框架
itemSelector: '.col' , //指定每一个信息卡片
columnWidth:247, //每个卡片的总宽度(含间距)
isFitWidth: true , //是否自适应浏览器宽度(自动布局)
isAnimatedFromBottom: true , //是否支持继续插入信息流
});
isAnimatedFromBottom参数一定要设置,不然后面的无限拖拽无法实现:)
好了,现在静态页面的布局就已经实现了~~
下面说说动态数据加载
在开始之前,还是简要提一下某插件吧,masonry官方也在使用该插件,那就是infinite scroll(传送门)。
它的功能是实现瀑布流无限拖拽获取信息的功能,几乎适用于任何形式的信息展示方式,包括咱的wordpress╮(╯▽╰)╭
主要实现方式就是通过该插件绑定页面中已有的“上、下一页”这样的翻页区域元素,然后插件会隐藏掉这些元素的显示,再通过配置文件指定滚动条滚动到什么位置的时候去请求这个“下一页”的链接,然后将获取到的数据加载到当前页尾。
这个插件对于已有程序来说是个不错的选择,不过skidu是自己折腾的程序,在起初设计这个瀑布流的时候就没有准备给这样一个导航,所以skidu果断抛弃它,使用自己的方式来实现。
首先,咱页面打开了得有数据才行吧?好吧,skidu的做法是使用php从数据库中获取一定量的信息(这个,这一步不是本文重点,获取方式就不用skidu多费口水了吧 – - )并以json格式传递给当前页面,然后使用js整合这些数据成每一个小卡片,然后再通过masonry插件实现瀑布流布局。
下面上代码!
前文中提及过的代码这里就不重复了~
//file: demo.php
<html>
<head>
<title>瀑布流布局DEMO</title>
<style>...</style>
<script>...</script>
<script> var data = <?php echo $data ; ?></script>
//这一步是将php传递过来的数据交给js变量data,方便之后的操作
</head>
<body>
<div id= "demo" ></div>
</body>
<script type= "text/javascript" >
html = make_html( data );
$( "#demo" ).append( html );
$( function (){
$( "#demo" ).masonry({
itemSelector: '.col' ,
columnWidth:247,
isAnimated:true,
isAnimatedFromBottom:true,
gutterWidth:0,
});
</script>
</html>
眼尖的同学应该已经发现了,前文提到过的
<div class="col"></div> <p>不见了~
嗯,这里skidu是将这些div单独提取出来封到一个js函数中去了,这样js才能够生成数据是不?呵呵,下面放出这个函数。
先简要描述一下skidu的返回数据组成吧~
array (
[0]=> array ( //第一条数据
'content' => 'aaaa' //数据内容
),
[1]=> array (), //第二条数据
[2]=> array (), //第三条数据
[3]=> array (), //第四条数据
// ……………… 更多的数据
[ 'totle' ]=>20 //本次返回的数据总条数
)
//嗯,是简化版,仅仅是满足本文需求
function make_html( data ){
var html = '' ;
var leng = data.totle;
for (i=0; i<leng; i++){
html += '<div class="col">' + data[i].content + '</div>' ;
}
return html;
}
好了,咱接着说,js将获取到的json数据传递给上面这个make_html这个函数,函数将遍历该组数据并动态生成需要的html并返回给js变量html,然后通过jquery的append方法将它们塞到页面的#demo中去,然后再通过masonry插件实现对这些数据的瀑布流布局。
怎么样?很简单吧~
接下来,开始实现拖拽请求
首先,我们得监听滚动条事件
$(window).scroll( function () {
var scrollh = document.documentElement.scrollHeight;
var scrollt = document.documentElement.scrollTop + document.body.scrollTop;
if ( scrollt/scrollh > 0.3 ) {
$.ajax({
url:...,
type:...,
data:...,
dataType: 'json' ,
async: false ,
success: function ( msg ){
var new_data = '' ;
new_data = make_html( msg );
$( '#demo' ).append( new_data ).masonry( 'reload' );
}
});
}
});
我们通过scrollh和scrollt这两个变量来获取到当前页面的高度以及滚动条所在的位置,然后判断滚动条是否到达预定位置,若到达,则执行一次ajax请求如以上代码所示。嗯,上述中的jquery.ajax我简写了,不明白的朋友可以查阅jquery手册的相关部分,当然,后端的php请求文件要提前写好,这里也不重复了。
当请求成功后,ajax用msg来接收php返回的新数据,然后再次将该数据交给make_html,生成新的信息后再次append给#demo并使用masonry的reload方法对这些信息进行瀑布流布局。
至此,整个瀑布流+无限拖拽功能已经实现。
后文是skidu在实际折腾的过程中遇到一些问题的解决办法。
关于请求内容:
咱当然是不能重复获取数据了,所以skidu在后端请求完成的时候使用cookie记录了一下本次返回数据中最小的数据id,并将它作为下次请求的开始id号,在数据库中查找小于该id的规定数目条信息并返回。
数据太多,拖拽可能卡死:
因为这次是做的微博系统开发,信息量庞大是必然的,所以,咱还是不能让用户看太多太爽是不?再次派出我们的cookie记录一个数字来模拟当前的查看内容的页数,每次向php请求新数据的时候php会判断一下这个数字是否大于我们预设的一个数字,如果大于了,php将不再返回数据。
拖拽请求频繁:
这个现象很严重,毕竟从ajax发出请求到获取到数据的这个过程可能会比较久,如果遇到极品用户,在这个过程中他就能发出一堆重复请求,于是乎,各种重复数据诞生了。。
同时,因为之前的拖拽监听中是使用的大于符号,所以,在这个区域中进行拖拽js都会玩命发生ajax请求。。
skidu的初步解决办法是这样的
当php接收到ajax请求后,首先将之前记录在cookie中的id保存到某变量中,然后注销掉该cookie,然后通过传值的方式带着这个id去请求数据直到有数据返回;同时,php对该cookie的存在与否进行一次判断,如果不存在则直接终止掉本次请求,也就是用户将无法获取到数据,这样,极品拖拽帝的问题解决了。
接下来就是js的滚动事件产生的无限请求。
skidu最终抛弃了$().scroll()方法来监听滚动条,而是将这个监听事件写入一个js函数中(比如get_more()),然后在页面加载完成时使用$().bind()方法将get_more()绑定到window上去,这样在用户拖拽时就能监听滚动条了;当滚动条位置满足产生ajax请求的时候再使用$().unbind()方法取消掉get_more()的绑定,同时,ajax添加参数async:false关闭异步请求,当请求成功并且获得的数据是我们需要的数据的时候再次$().bind()绑定上这个监听事件,这样瀑布流中的请求次数就成功控制下来了。
排版错乱:
主要是由于信息中有图片的时候才会产生此现象,因为当图片加载完成之前,masonry是无法准确确定这一个卡片的具体高度的,于是乎就会出现各种不和谐的界面效果。解决办法是在php返回数据的时候先对数据内容进行分析,如果含有图片,则首先获取到这些图片的宽高数据一并返回,这样js就可以通过这些数据预留出这个高度,瀑布流就不会错乱了。
末了,感谢痞子同学的文章让我能够快速上手masonry这个小插件~
最后,关于jQuery.Masonry这个插件,还有很多其他功能本文并未一一作出介绍,有兴趣的朋友可以去查看官方帮助文档:
http://masonry.desandro.com/index.html
最后的最后,咱还得感谢一下火狐浏览器~这篇日志描述不多,不过skidu前前后后折腾了有两个多小时,中途skidu不小心一脚踢掉了插线,wordpress的自动保存让俺损失了一个小时的文字,还是firefox的自动恢复给力,连编辑器中的内容都给恢复了0.0
好吧,再没有最后了,表达有些凌乱代码也比较简陋,各位看官凑合凑合吧:)