watermark 水位线 处理乱序 数据流从数据产生到DataSource,再到具体的算子,中间是有一个过程和时间,有可能会导致数据乱序问题,通过watermark + EventTime来处理。 作用 : 由于网络延迟等
watermark 水位线 处理乱序
数据流从数据产生到DataSource,再到具体的算子,中间是有一个过程和时间,有可能会导致数据乱序问题,通过watermark + EventTime来处理。
作用:由于网络延迟等原因,一条数据会迟到计算,比如使用event time来划分窗口,我们知道窗口中的数据是计算一段时间的数据,如果一个数据来晚了,它的时间范围已经不属于这个窗口了,则会被丢弃,但他的event time实际上是属于这个窗口的。引入watermark机制则会等待晚到的数据一段时间,等待时间到则触发计算,如果数据延迟很大,通常也会被丢弃或者另外处理。
生成方式
watermark生成方式有两种:
- 周期性生成watermark【常用】:每隔N秒自动向流中注入一个watermark,由executionConfig.setAutoWatermarkInterval()决定,默认是200毫秒。注意:假如设置3秒延时,使用事件的时间戳,如果有窗口的停止时间等于maxEventTime – 3,那么这个窗口被触发执行,否则一直等待
- 基于事件生成:基于某些事件触发watermark的生成,每个元素都有机会判断是否生成一个watermark
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置时间语义
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
// 设置并行度为1 用来演示单并行度下的watermark
env.setParallelism(1);
// 设置周期性生成watermark 默认200ms
env.getConfig().setAutoWatermarkInterval(200);
// 传输过来的数据格式:10001,19980009908(id,时间戳)
DataStreamSource<String> streamSource = env.socketTextStream("10.50.8.125", 9001);
// 将数据转成Tuple2(id,时间戳)
SingleOutputStreamOperator<Tuple2<Long, Long>> streamOperator = streamSource.map(new MapFunction<String, Tuple2<Long, Long>>() {
@Override
public Tuple2<Long, Long> map(String values) throws Exception {
String[] split = values.split(",");
return new Tuple2<>(Long.valueOf(split[0]), Long.valueOf(split[1]));
}
});
// 分配时间戳和 watermark 设置允许的最大乱序时间范围10秒
SingleOutputStreamOperator<Tuple2<Long, Long>> watermarkStream = streamOperator.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Tuple2<Long, Long>>(Time.seconds(10)) {
// 从数据流中抽取时间戳作为EventTime
@Override
public long extractTimestamp(Tuple2<Long, Long> longLongTuple2) {
System.out.println("key:" + longLongTuple2.f0 + ",eventTime:" + longLongTuple2.f1);
return longLongTuple2.f1;
}
});
watermarkStream.keyBy(0)
// 按照消息的EventTime分配窗口 和调用TimeWindow效果一样
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
// 全量聚合 参数1:接收的数据 参数2:输出的数据类型
.apply(new WindowFunction<Tuple2<Long, Long>, String, Tuple, TimeWindow>() {
@Override
public void apply(Tuple key, TimeWindow timeWindow, Iterable<Tuple2<Long, Long>> input, Collector<String> out) throws Exception {
ArrayList<Long> result = new ArrayList<>();
// 将时间戳放入队列 便于排序
input.forEach(in->{
result.add(in.f1);
});
// 对时间戳排序 小的在前
Collections.sort(result);
// 将目前window内排序后的数据以及window的开始和结束时间打印出来
System.out.println("result:"+ JSON.toJSONString(result)+",windowStart:"+timeWindow.getStart()+",windowEnd:"+timeWindow.getEnd());
out.collect(JSON.toJSONString(result));
}
}).print();
env.execute();
}延迟数据的处理方式
三种方式:
- 直接丢弃【默认】:Flink默认的策略就是对迟到的数据直接丢弃
- 重新激活已经关闭的窗口并重新计算以修正结果。
- 将迟到数据收集起来另外处理。
并行度
TaskManager和Slot,TaskManager是从节点,Slot个数一般对应的就是TaskManager的cpu数量,Slot用来执行具体的算子。
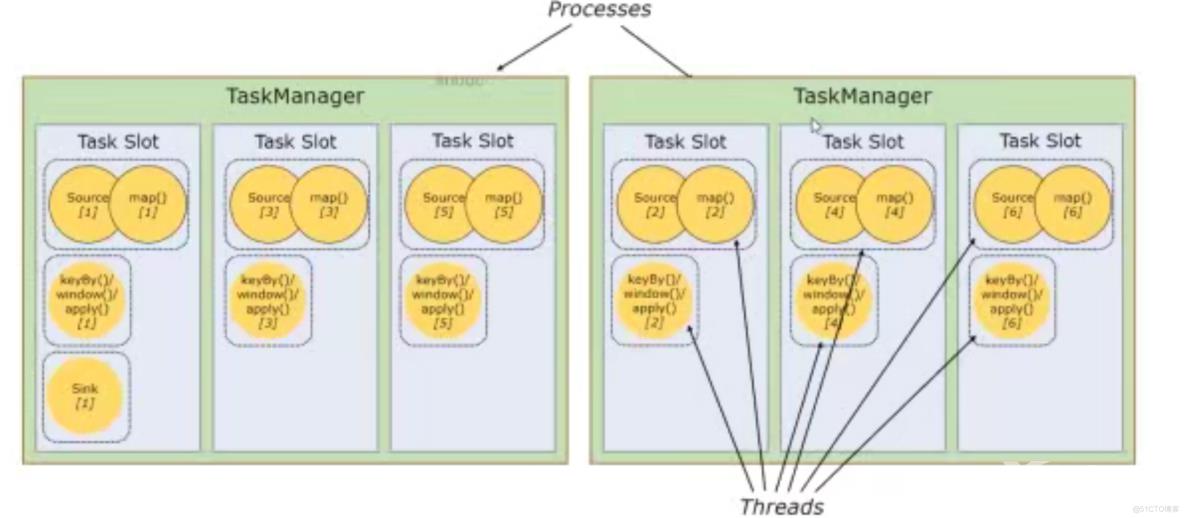
Flink可以通过四种方式设置并行度,优先级从高到低排序:算子层面>执行环境层面>客户端层面>系统层面
// 算子层面
streamSource.map(new MapFunction<String, Tuple2<Long, Long>>() {
@Override
public Tuple2<Long, Long> map(String values) throws Exception {
String[] split = values.split(",");
return new Tuple2<>(Long.valueOf(split[0]), Long.valueOf(split[1]));
}
}).setParallelism(2)
// 执行环境层面
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);客户端层面:提交任务时通过-p 指定并行度
系统层面:通过设置flink-conf.yaml文件中的parallelism.default属性来设置默认并行度