前言
马上就快过年了,祝福小伙伴们牛年大吉,牛气冲天!本期文章分享的是赵老师在《方法论与工程化解决解决方案》一书中提到的关于如何在用户画像项目开发中进行性能调优的例子,希望大家耐心看完后有所收获!

一、数据倾斜调优
数据倾斜是开发画像过程中常遇到的问题,当任务执行一直卡在map 100%、reduce 99%,最后的1%花了几个小时都没执行完时,这时一般是遇到了数据倾斜。
问题出现的原因是当进行分布式计算时,由于某些节点需要计算的数据较多,导致其他节点的reduce阶段任务执行完成时,该节点的任务还没有执行完成,造成其他节点等待该节点执行完成的情况。比如两张大表在join的时候大部分key对应10条数据,但是个别几个key对应了100万条数据,对应10条数据的task很快执行完成了,但对应了100万数据的key则要执行几个小时。
下图便是一个典型的例子。
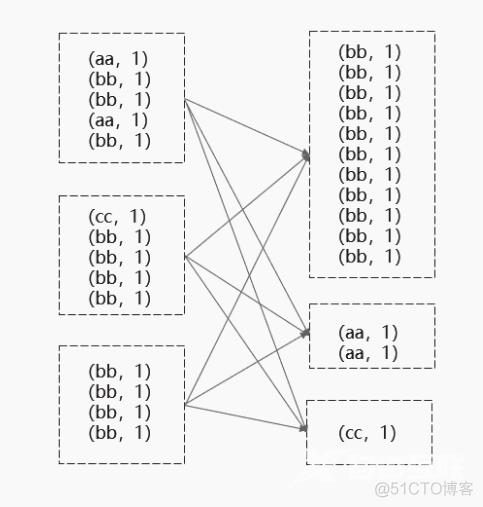
bb这个key在3个节点上有11条数据,aa和cc在3个节点上分别有2条和1条数据,这些数据都会被拉取到一个task上处理。处理bb这个task的运行时间可能是处理aa和cc的task的运行时间数倍,整体运行速度由最慢的task决定。
下面介绍两种解决数据倾斜问题的方案。
方案一:过滤掉倾斜数据
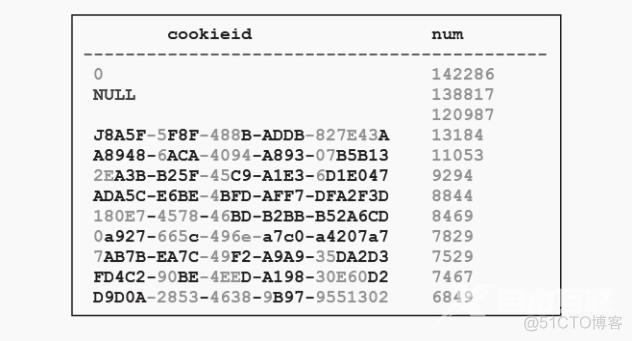
当少量key重复次数特别多,如果这种key不是业务需要的key,可以直接过滤掉。这里有一张埋点日志表 ods.page_event_log ,需要和订单表 dw.order_info_fact 做join关联。在执行Hive的过程中发现任务卡在map 100%、reduce 99%,最后的1%一直运行不完。考虑应该是在join的过程中出现了数据倾斜,下面进行排查。
对于ods.page_event_log表查看出现次数最多的key:
select cookieid,
count(*) as num
from ods.page_event_log
where data_date = "20190101"
group by cookieid
distribute by cookieid
sort by num
desc
limit 10;
将 key 按出现次数从多到少排序
同样地,对订单表dw.order_info_fact查看出现次数最多的key:
select cookieid,
count(*) as num
from dw.order_info_fact
group by cookieid
distribute by cookieid
sort by num desc
limit 10
将key按出现次数从多到少排序
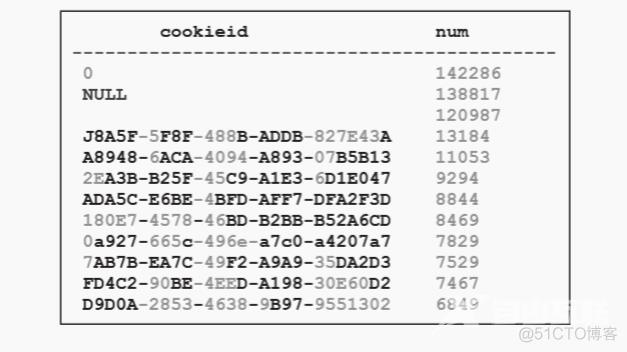
从上面的例子可以看出,日志表和订单表通过 cookieid 进行join,当 cookieid 为0的时候,join操作将会产生142286×142286条数据,数量如此庞大的节点系统无法处理过来。同样当 cookieid 为 NULL 值和 空值 时也会出现这种情况,而且 cookieid 为这3个值时并没有实际的业务意义。因此在对两个表做关联时,排除掉这3个值以后,就可以很快计算出结果了。
方案二:引入随机数
数据按照类型 group by 时,会将相同的key所需的数据拉取到一个节点进行聚合,而当某组数据量过大时,会出现其他组已经计算完成而当前任务未完成的情况。可以考虑加入随机数,将原来的一组key强制拆分为多组进行聚合。下面通过一个案例进行介绍。
现需要统计用户的订单量,执行如下代码:
select t1.user_id,
t2.order_num
from (select user_id
from dim.user_info_fact # 用户维度表
where data_date = "20190101"
and user_status_id=1
) t1
join ( select user_id,
count(*) as order_num
from dw.dw_order_fact # 订单表
where site_id in (600, 900)
and order_status_id in(1,2,3)
group by user_id
) t2
on t1.user_id = t2.user_id;
用户维度表中有2000万条数据,订单表有10亿条数据,任务在未优化前执行了1个小时也没有跑出结果,判断可能是出现了数据倾斜。
订单表中某些 key 值数量较多,在group by 的过程中拉取到一个 task 上执行时,会出现其他task执行完毕,等待该task执行的情况。
这里可以将原本相同的key通过添加随机前缀的方式变成多个 key ,这样将原本被一个 task 处理的 key 分散到多个 task 上先做一次聚合,然后去掉前缀再进行一次聚合得到最终结果。
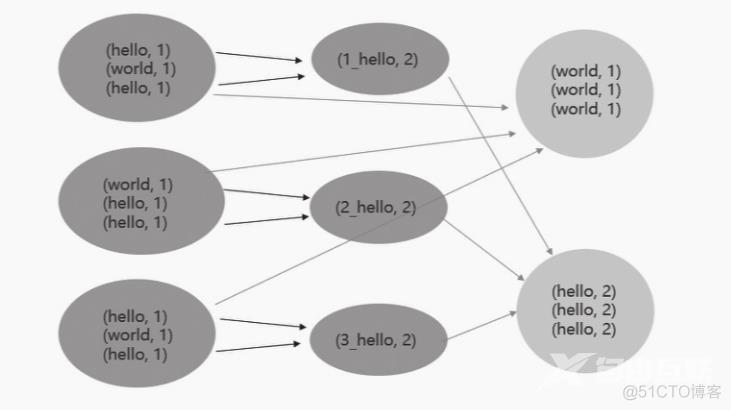
修改后代码执行如下:
select t1.user_id,
t2.order_num
from (select user_id
from dim_user_info_fact
where data_date = "20190101"
) t1
join (select t.user_id,
sum(t.order_num) as order_num
from (select user_id,
round(rand() * 1000) as rnd,
count(1) as order_num
from dw.order_info_fact
where pay_status in (1, 3)
group by user_id, round(rand() * 1000)
) t
group by t.user_id
) t2
on t1.user_id = t2.user_id
二、合并小文件
在Spark执行“insert overwrite table表名”的语句时,由于多线程并行向HDFS写入且RDD默认分区为200个,因此默认情况下会产生200个小文件。
Spark中可以使用 reparation 或 coalesce 对RDD的分区重新进行划分,reparation 是 coalesce 接口中 shuffle 为true的实现。
在Spark内部会对每一个分区分配一个task 执行,如果task过多,那么每个task处理的数据量很小,这就会造成线程频繁在task之间切换,导致集群工作效率低下。为解决这个问题,常采用RDD重分区函数来减少分区数量,将小分区合并为大分区,从而提高集群工作效率。
// 合并插入用户宽表数据的分区
val executesqls = spark.sql(
"""
| select user_id,
| org_id,
| org_name,
| sum(act_weight) as act_weight,
| sum(cnt) as cnt
| from dw.peasona_user_tag_relation
| where user_id is not null
| and user_id <> 'null'
| group by user_id,org_id,org_name
""".stripMargin).rdd.coalesce(1)
val datardd = executesqls.map(row => {
val user_id = row.getAs[String]("user_id")
val org_id = row.getAs[String]("org_id")
val org_name = row.getAs[String]("org_name")
val act_weight = row.getAs[String]("act_weight")
val cnt = row.getAs[String]("cnt")
Row(user_id,org_id,org_name,act_weight,cnt)
})
spark.createDataFrame(datardd, StructType(Seq(
StructField("user_id", StringType),
StructField("org_id", StringType),
StructField("org_name", StringType),
StructField("act_weight", StringType),
StructField("cnt", StringType)
))).createOrReplaceTempView("user_act_info")
spark.sql(
s"""
| INSERT OVERWRITE TABLE dw.peasona_user_tag_relation partition(data_date="$data_date")
| SELECT user_id,org_id,org_name,act_weight,cnt
| FROM user_act_info
""".stripMargin)
三、缓存中间数据
Spark的一个重要的能力就是将数据持久化缓存,这样在多个操作期间都可以访问这些持久化的数据。当持久化一个RDD时,每个节点的其他分区都可以使用RDD在内存中进行计算,在该数据上的其他action操作将直接使用内存中的数据,这样会使其操作计算速度加快。对RDD的复杂操作如果没有持久化,那么一切的操作都会从源头开始,一步步往后计算,不会复用原始数据。
在画像标签每天ETL的时候,对于一些中间计算结果可以不落磁盘,只需把数据缓存在内存中。而使用Hive进行ETL时需要将一些中间计算结果落在临时表中,使用完临时表后再将其删除。
RDD可以使用 persist 或 cache方法进行持久化,使用 StorageLevel 对象给 persist 方法设置存储级别时,常用的存储级别如下所示。
- MEMORY_ONLY:只存储在内存中
- MEMORY_ONLY_2:只存储在内存中,每个分区在集群中两个节点上建立副本;
- DISK_ONLY:只存储在磁盘中;
- MEMORY_AND_DISK:先存储在内存中,内存不够的话存储在磁盘中
其中 cache 方法等同于调用 persist()的 MEMORY_ONLY方法
在画像标签开发中,一般从Hive中读取数据,然后将需要做中间处理的DataFrame注册成缓存表。
这里介绍一个开发画像标签时缓存中间数据的案例。
执行如下代码:
// 读取原数据 下单用户
val peopleRDD = spark.sparkContext.textFile("C:\\Users\\king\\Desktop\\practice\\cookiesession")
.map(_.split(",")) // RDD[Array[String]]
.map( row => Row(row(0),row(1),row(2),row(3),row(4))) // RDD[Row]
peopleRDD.persist(StorageLevel.MEMORY_ONLY)
peopleRDD.createOrReplaceTempView(“user_base_info”)
这里将读取的用户数据缓存在内存中并注册为一张视图。后续直接从视图中读取对应用户数据。在该Spark任务执行完成后,释放内存,不需要清除该缓存数据。
四、开发中间表
在用户画像迭代开发的过程中,初期开发完标签后,通过对标签加工作业的血缘图整理,可以找到使用相同数据源的标签,对这部分标签,可以通过加工中间表缩减每日画像调度作业时间。
做中间层设计前需要明确几个重要的点:
1)这个中间层对应的业务场景、业务目标是什么?
2)业务方有了这份中间层数据以后可以进行哪些维度的分析,ETL时有了这份中间层数据可以减少对哪些数据的重复开发计算?
3) 这个业务场景分析中包含哪些分析维度和指标?
4)同时面向很多业务场景的中间层不一定是好的中间层。
在开发中间表前,首先需要梳理目前用户标签计算时依赖的上游数据仓库的表
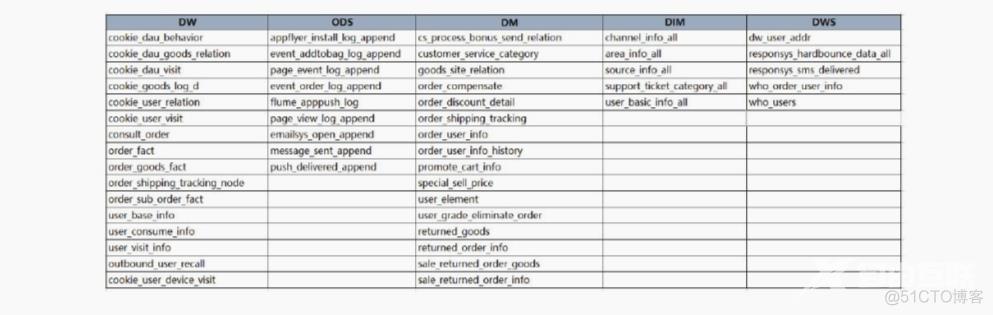
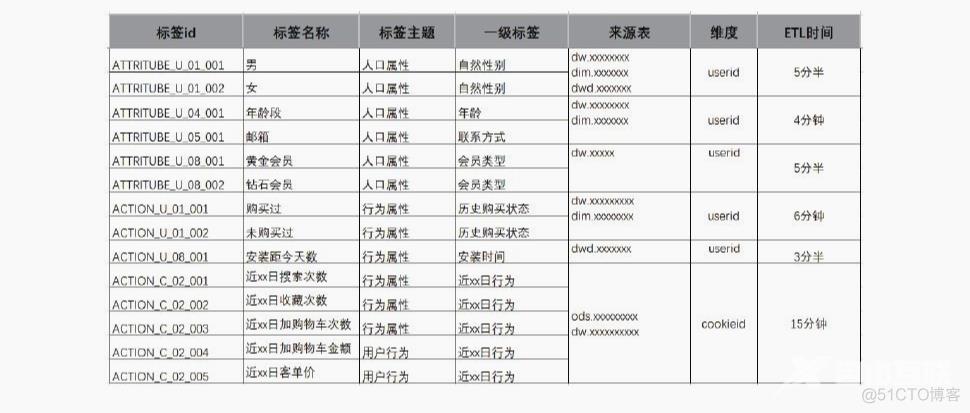
和标签的血缘依赖
例如在开发过程中,可以在 dwd 层的日分区存放当天日期对应的订单,而 dws层作为服务层,其日分区用于存放当天日期对应的全量数据。这样,在日常调度计算的过程中,可避免在dwd层重复计算历史数据,只需计算当天的新增数据,既节省了ETL时间,也不会影响服务层的数据。
通过对用户标签的血缘图进行梳理,找到共同依赖的上游数据。
本章小结
之前在笔者的项目开发过程中,ETL调度时间过长是一个较难解决的“瓶颈”,每天的调度在跑完计算标签、标签校验预警、计算人群、人群校验预警、同步到服务层等环节后往往需要几个小时,最后提供到服务层数据时也比较晚了。在这个过程中为了减少调度时间,我们也做了很多尝试,包括对一些Hive表设计多个分区,并行跑任务插入数据;对一些执行时间过长的脚本进行调优;梳理数据血缘开发中间层表,对一些常见的公共数据直接从中间层表获取数据,减少数据的重复开发计算等。在经过多次迭代后也取得了不错的效果,将整体调度时间压缩了1/3,可以满足每天及时将画像数据输出到服务层的需要。
本期介绍了画像系统在数据开发中可能遇到的需要调优的场景。通过对数据倾斜、合并小文件、缓存中间数据、开发中间表几个常见问题的处理,可以优化ETL作业流程,减少调度的整体时间。
看了赵老师的分享,对于该书有兴趣的同学,也可以点击下方链接进行购买,花几十块钱,学到大牛几年的工作经验,想想都是稳赚不赔的事,当然,前提是自己得花时间去看,去实践,而不是成为标准的“收藏家”。
好了,本篇文章就到这里,更多干货文章请关注下方我的公众号。你知道的越多,你不知道的也越多。我是Alice,我们下一期见!