Word文档在日常工作中应用十分广泛;可以储存文本、图片等多种类型的信息。当文档中包含对我们有用文本或图片时,我们可以选择将它们从文档中提取出来用于其他用处。在这篇文章
Word文档在日常工作中应用十分广泛;可以储存文本、图片等多种类型的信息。当文档中包含对我们有用文本或图片时,我们可以选择将它们从文档中提取出来用于其他用处。在这篇文章中,我就将演示如何使用Free Spire.Doc for .NET在C#和VB.NET程序中快速提取Word文档中文本或图片。以下是详细操作步骤。
- 从Word文档中提取文本
- 从Word文档中提取图片
安装Free Spire.Doc for .NET
方法一,通过NuGet安装Free Spire.Doc for .NET:
依次选择工具>NuGet包管理器>程序包管理器控制台,然后执行以下命令:
PM> Install-Package FreeSpire.Doc
方法二,在程序中手动引入Spire.doc.dll文件:
将Free Spire.Doc for .NET(dll only)下载到本地并进行解压。解压之后,打开 Visual Studio创建新项目,在右边的“解决方案资源管理器”中右键点击“引用”,再依次选择“添加引用”> “浏览”,找到安装路径下BIN文件夹中的dll文件,点击“确定”,将其添加引用至程序中。
从Word文档中提取文本
下面是具体操作步骤和代码。
- 创建Document实例。
- 使用Document.LoadFromFile()方法,加载示例Word文档。
- 创建StringBuilder实例。
- 获取文档中每个节中的每个段落,并使用Paragraph.Text属性获取指定段落的文本;然后使用StringBuilder.AppendLine()方法,将所提取的文本附加到String Builder实例中。
- 创建一个新的txt文件,并使用File.WriteAllText()方法将提取的文本写入该文件。
C#:
using Spire.Doc;
using Spire.Doc.Documents;
using System.Text;
using System.IO;
namespace ExtractTextfromWord
{
class ExtractText
{
static void Main(string[] args)
{
//创建Document实例
Document document = new Document();
//加载Word示例文档
document.LoadFromFile("input.docx");
//创建StringBuilder实例
StringBuilder sb = new StringBuilder();
//获取每个节中的每个段落,并从Word中提取文本并保存到StringBuilder实例中
foreach (Section section in document.Sections)
{
foreach (Paragraph paragraph in section.Paragraphs)
{
sb.AppendLine(paragraph.Text);
}
}
//创建一个新的txt文档以保存所提取的文本
File.WriteAllText("Extract.txt", sb.ToString());
}
}
}
VB.NET:
Imports Spire.Doc
Imports Spire.Doc.Documents
Imports System.Text
Imports System.IO
Namespace ExtractTextfromWord
Class ExtractText
Private Shared Sub Main(ByVal args() As String)
'创建Document实例
Dim document As Document = New Document
'加载Word示例文档
document.LoadFromFile("input.docx")
'创建StringBuilder实例
Dim sb As StringBuilder = New StringBuilder
'获取每个节中的每个段落,并从Word中提取文本并保存到StringBuilder实例中
For Each section As Section In document.Sections
For Each paragraph As Paragraph In section.Paragraphs
sb.AppendLine(paragraph.Text)
Next
Next
'创建一个新的txt文档以保存所提取的文本
File.WriteAllText("Extract.txt", sb.ToString)
End Sub
End Class
End Namespace

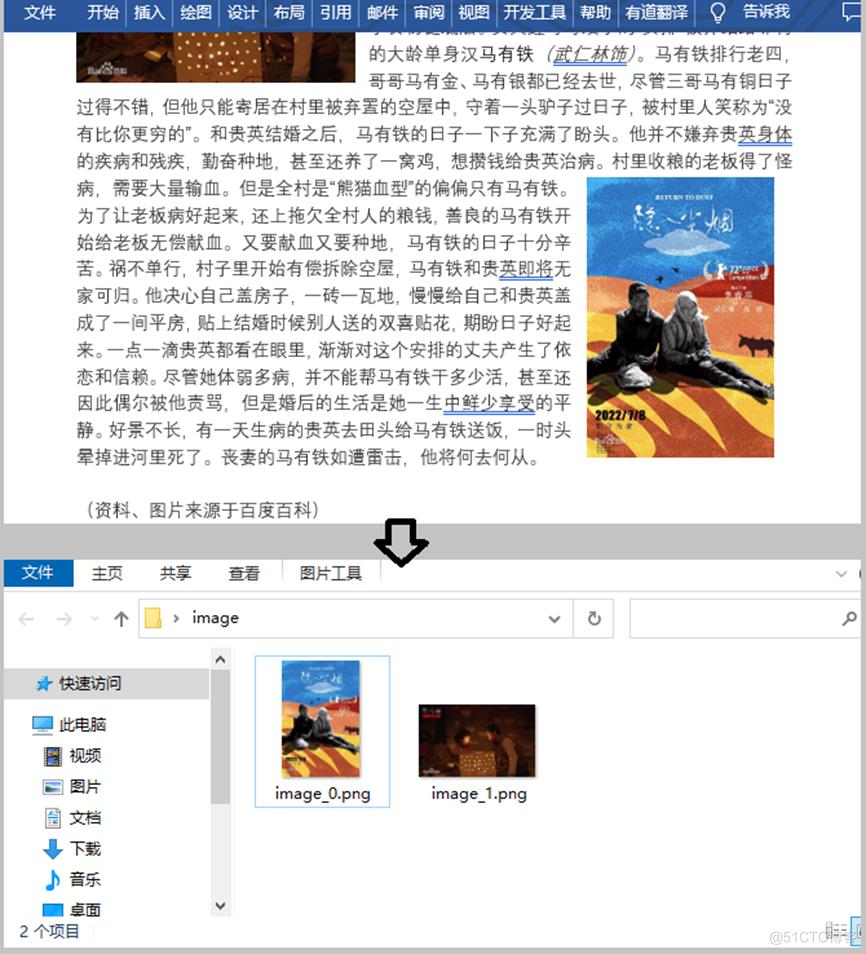
从Word文档中提取图片
下面是具体操作步骤和代码。
- 创建Document实例,使用Document.LoadFromFile()方法,加载示例Word文档。
- 获取文档中的每个节。
- 获取文档中每个节中的每个段落
- 获取特定段落中的每个Document 对象。
- 确定Document对象类型是否为图片。如果是,请使用DocPicture.Image.Save(String, ImageFormat) 方法,从文档中提取并保存图片。
C#:
using Spire.Doc;
using Spire.Doc.Documents;
using Spire.Doc.Fields;
using System;
namespace ExtractImage
{
class Program
{
static void Main(string[] args)
{
//创建Document实例并加载Word示例文档
Document document = new Document("input.docx");
int index = 0;
//获取文档中每个节
foreach (Section section in document.Sections)
{
//获取文档中每个节中的每个段落
foreach (Paragraph paragraph in section.Paragraphs)
{
//获取特定段落中的每个Document 对象
foreach (DocumentObject docObject in paragraph.ChildObjects)
{
//如果DocumentObjectType为图片,从文档中提取并保存图片
if (docObject.DocumentObjectType == DocumentObjectType.Picture)
{
DocPicture picture = docObject as DocPicture;
picture.Image.Save(string.Format("image_{0}.png", index), System.Drawing.Imaging.ImageFormat.Png);
index++;
}
}
}
}
}
}
}
VB.NET:
Imports Spire.Doc
Imports Spire.Doc.Documents
Imports Spire.Doc.Fields
Imports System
Namespace ExtractImage
Class Program
Private Shared Sub Main(ByVal args() As String)
'创建Document实例并加载Word示例文档
Dim document As Document = New Document("input.docx")
Dim index As Integer = 0
'获取文档中每个节
For Each section As Section In document.Sections
'获取文档中每个节中的每个段落
For Each paragraph As Paragraph In section.Paragraphs
'获取特定段落中的每个Document 对象
For Each docObject As DocumentObject In paragraph.ChildObjects
'如果DocumentObjectType为图片,从文档中提取并保存图片
If (docObject.DocumentObjectType = DocumentObjectType.Picture) Then
Dim picture As DocPicture = CType(docObject,DocPicture)
picture.Image.Save(String.Format("image_{0}.png", index), System.Drawing.Imaging.ImageFormat.Png)
index = (index + 1)
End If
Next
Next
Next
End Sub
End Class
End Namespace