在这篇文章中,我将使用python中的决策树(用于分类)。重点将放在基础知识和对最终决策树的理解上。
导入
因此,首先我们进行一些导入。
from __future__ import print_function
import os
import subprocess
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier, export_graphviz
数据
接下来,我们需要考虑一些数据。我将使用著名的iris数据集,该数据集可对各种不同的iris类型进行各种测量。pandas和sckit-learn都可以轻松导入这些数据,我将使用pandas编写一个从csv文件导入的函数。这样做的目的是演示如何将scikit-learn与pandas一起使用。因此,我们定义了一个获取iris数据的函数:
def get_iris_data():
"""Get the iris data, from local csv or pandas repo."""
if os.path.exists("iris.csv"):
print("-- iris.csv found locally")
df = pd.read_csv("iris.csv", index_col=0)
else:
print("-- trying to download from github")
fn = "https://raw.githubusercontent.com/pydata/pandas/" + \
"master/pandas/tests/data/iris.csv"
try:
df = pd.read_csv(fn)
except:
exit("-- Unable to download iris.csv")
with open("iris.csv", 'w') as f:
print("-- writing to local iris.csv file")
df.to_csv(f)
return df
- 此函数首先尝试在本地读取数据。利用os.path.exists() 方法。如果在本地目录中找到iris.csv文件,则使用pandas通过pd.read_csv()读取文件。
- 如果本地iris.csv没有发现,抓取URL数据来运行。
下一步是获取数据,并使用head()和tail()方法查看数据的样子。因此,首先获取数据:
df = get_iris_data()
-- iris.csv found locally
然后 :
print("* df.head()", df.head(), sep="\n", end="\n\n")
print("* df.tail()", df.tail(), sep="\n", end="\n\n")
* df.head()
SepalLength SepalWidth PetalLength PetalWidth Name
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
* df.tail()
SepalLength SepalWidth PetalLength PetalWidth Name
145 6.7 3.0 5.2 2.3 Iris-virginica
146 6.3 2.5 5.0 1.9 Iris-virginica
147 6.5 3.0 5.2 2.0 Iris-virginica
148 6.2 3.4 5.4 2.3 Iris-virginica
149 5.9 3.0 5.1 1.8 Iris-virginica
从这些信息中,我们可以讨论我们的目标:给定特征SepalLength, SepalWidth, PetalLength 和PetalWidth来预测iris类型。
预处理
为了将这些数据传递到scikit-learn,我们需要将Names编码为整数。为此,我们将编写另一个函数,并返回修改后的数据框以及目标(类)名称的列表:
让我们看看有什么:
* df2.head()
Target Name
0 0 Iris-setosa
1 0 Iris-setosa
2 0 Iris-setosa
3 0 Iris-setosa
4 0 Iris-setosa
* df2.tail()
Target Name
145 2 Iris-virginica
146 2 Iris-virginica
147 2 Iris-virginica
148 2 Iris-virginica
149 2 Iris-virginica
* targets
['Iris-setosa' 'Iris-versicolor' 'Iris-virginica']
接下来,我们获得列的名称:
features = list(df2.columns[:4])
print("* features:", features, sep="\n")
* features:
['SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth']
用scikit-learn拟合决策树
现在,我们可以使用 上面导入的DecisionTreeClassifier拟合决策树,如下所示:
- 我们使用简单的索引从数据框中提取X和y数据。
- 开始时导入的决策树用两个参数初始化:min_samples_split = 20需要一个节点中的20个样本才能拆分,并且 random_state = 99进行种子随机数生成器。
可视化树
我们可以使用以下功能生成图形:
- 从上面的scikit-learn导入的export_graphviz方法写入一个点文件。此文件用于生成图形。
- 生成图形 dt.png。
运行函数:
visualize_tree(dt, features)
结果
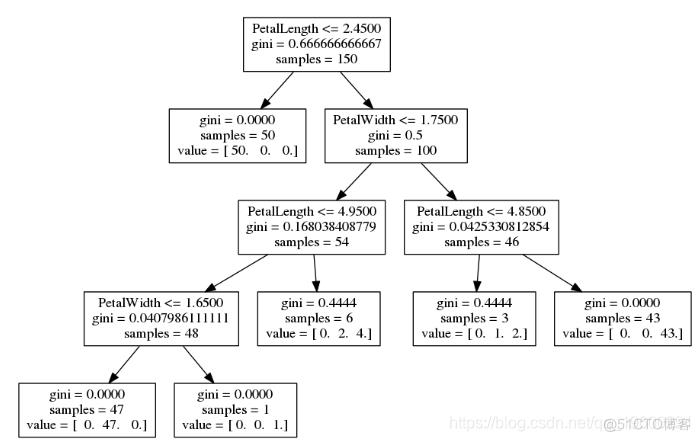
我们可以使用此图来了解决策树发现的模式:
- 所有数据(所有行)都从树顶部开始。
- 考虑了所有功能,以了解如何以最有用的方式拆分数据-默认情况下使用基尼度量。
- 在顶部,我们看到最有用的条件是 PetalLength <= 2.4500。
- 这种分裂一直持续到
- 拆分后仅具有一个类别。
- 或者,结果中的样本少于20个。
决策树的伪代码
最后,我们考虑生成代表学习的决策树的伪代码。
- 目标名称可以传递给函数,并包含在输出中。
- 使用spacer_base 参数,使输出更容易阅读。
应用于iris数据的结果输出为:
get_code(dt, features, targets)
if ( PetalLength <= 2.45000004768 ) {
return Iris-setosa ( 50 examples )
}
else {
if ( PetalWidth <= 1.75 ) {
if ( PetalLength <= 4.94999980927 ) {
if ( PetalWidth <= 1.65000009537 ) {
return Iris-versicolor ( 47 examples )
}
else {
return Iris-virginica ( 1 examples )
}
}
else {
return Iris-versicolor ( 2 examples )
return Iris-virginica ( 4 examples )
}
}
else {
if ( PetalLength <= 4.85000038147 ) {
return Iris-versicolor ( 1 examples )
return Iris-virginica ( 2 examples )
}
else {
return Iris-virginica ( 43 examples )
}
}
}
将其与上面的图形输出进行比较-这只是决策树的不同表示。
在python中进行决策树交叉验证
导入
首先,我们导入所有代码:
from __future__ import print_function
import os
import subprocess
from time import time
from operator import itemgetter
from scipy.stats import randint
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
from sklearn.grid_search import GridSearchCV
from sklearn.grid_search import RandomizedSearchCV
from sklearn.cross_validation import cross_val_score
主要添加的内容是sklearn.grid_search中的方法,它们可以:
- 时间搜索
- 使用itemgetter对结果进行排序
- 使用scipy.stats.randint生成随机整数。
现在我们可以开始编写函数了。
包括:
- get_code –为决策树编写伪代码,
- visualize_tree –生成决策树的图形。
- encode_target –处理原始数据以与scikit-learn一起使用。
- get_iris_data –如果需要,从网络上获取 iris.csv,并将副本写入本地目录。
新功能
接下来,我们添加一些新功能来进行网格和随机搜索,并报告找到的主要参数。首先是报告。此功能从网格或随机搜索中获取输出,打印模型的报告并返回最佳参数设置。
网格搜索
接下来是run_gridsearch。该功能需要
- 特征X,
- 目标y,
- (决策树)分类器clf,
- 尝试参数字典的param_grid
- 交叉验证cv的倍数,默认为5。
param_grid是一组参数,这将是作测试,要注意不要列表中有太多的选择。
随机搜寻
接下来是run_randomsearch函数,该函数从指定的列表或分布中采样参数。与网格搜索类似,参数为:
- 功能X
- 目标y
- (决策树)分类器clf
- 交叉验证cv的倍数,默认为5
- n_iter_search的随机参数设置数目,默认为20。
好的,我们已经定义了所有函数。
交叉验证
获取数据
接下来,让我们使用上面设置的搜索方法来找到合适的参数设置。首先进行一些初步准备-获取数据并构建目标数据:
print("\n-- get data:")
df = get_iris_data()
print("")
features = ["SepalLength", "SepalWidth",
"PetalLength", "PetalWidth"]
df, targets = encode_target(df, "Name")
y = df["Target"]
X = df[features]
-- get data:
-- iris.csv found locally
第一次交叉验证
在下面的所有示例中,我将使用10倍交叉验证。
- 将数据分为10部分
- 拟合9个部分
- 其余部分的测试准确性
使用当前参数设置,在所有组合上重复此操作,以产生十个模型精度估计。通常会报告十个评分的平均值和标准偏差。
print("-- 10-fold cross-validation "
"[using setup from previous post]")
dt_old = DecisionTreeClassifier(min_samples_split=20,
random_state=99)
dt_old.fit(X, y)
scores = cross_val_score(dt_old, X, y, cv=10)
print("mean: {:.3f} (std: {:.3f})".format(scores.mean(),
scores.std()),
end="\n\n" )
-- 10-fold cross-validation [using setup from previous post]
mean: 0.960 (std: 0.033)
0.960还不错。这意味着平均准确性(使用经过训练的模型进行正确分类的百分比)为96%。该精度非常高,但是让我们看看是否可以找到更好的参数。
网格搜索的应用
首先,我将尝试网格搜索。字典para_grid提供了要测试的不同参数设置。
print("-- Grid Parameter Search via 10-fold CV")
dt = DecisionTreeClassifier()
ts_gs = run_gridsearch(X, y, dt, param_grid, cv=10)
-- Grid Parameter Search via 10-fold CV
GridSearchCV took 5.02 seconds for 288 candidate parameter settings.
Model with rank: 1
Mean validation score: 0.967 (std: 0.033)
Parameters: {'min_samples_split': 10, 'max_leaf_nodes': 5,
'criterion': 'gini', 'max_depth': None, 'min_samples_leaf': 1}
Model with rank: 2
Mean validation score: 0.967 (std: 0.033)
Parameters: {'min_samples_split': 20, 'max_leaf_nodes': 5,
'criterion': 'gini', 'max_depth': None, 'min_samples_leaf': 1}
Model with rank: 3
Mean validation score: 0.967 (std: 0.033)
Parameters: {'min_samples_split': 10, 'max_leaf_nodes': 5,
'criterion': 'gini', 'max_depth': 5, 'min_samples_leaf': 1}
在大多数运行中,各种参数设置的平均值为0.967。这意味着从96%改善到96.7%!我们可以看到最佳的参数设置ts_gs,如下所示:
print("\n-- Best Parameters:")
for k, v in ts_gs.items():
print("parameter: {:<20s} setting: {}".format(k, v))
-- Best Parameters:
parameter: min_samples_split setting: 10
parameter: max_leaf_nodes setting: 5
parameter: criterion setting: gini
parameter: max_depth setting: None
parameter: min_samples_leaf setting: 1
并复制交叉验证结果:
# test the retuned best parameters
print("\n\n-- Testing best parameters [Grid]...")
dt_ts_gs = DecisionTreeClassifier(**ts_gs)
scores = cross_val_score(dt_ts_gs, X, y, cv=10)
print("mean: {:.3f} (std: {:.3f})".format(scores.mean(),
scores.std()),
end="\n\n" )
-- Testing best parameters [Grid]...
mean: 0.967 (std: 0.033)
接下来,让我们使用获取最佳树的伪代码:
print("\n-- get_code for best parameters [Grid]:", end="\n\n")
dt_ts_gs.fit(X,y)
get_code(dt_ts_gs, features, targets)
-- get_code for best parameters [Grid]:
if ( PetalWidth <= 0.800000011921 ) {
return Iris-setosa ( 50 examples )
}
else {
if ( PetalWidth <= 1.75 ) {
if ( PetalLength <= 4.94999980927 ) {
if ( PetalWidth <= 1.65000009537 ) {
return Iris-versicolor ( 47 examples )
}
else {
return Iris-virginica ( 1 examples )
}
}
else {
return Iris-versicolor ( 2 examples )
return Iris-virginica ( 4 examples )
}
}
else {
return Iris-versicolor ( 1 examples )
return Iris-virginica ( 45 examples )
}
}
我们还可以制作决策树的图形:
visualize_tree(dt_ts_gs, features, fn="grid_best")
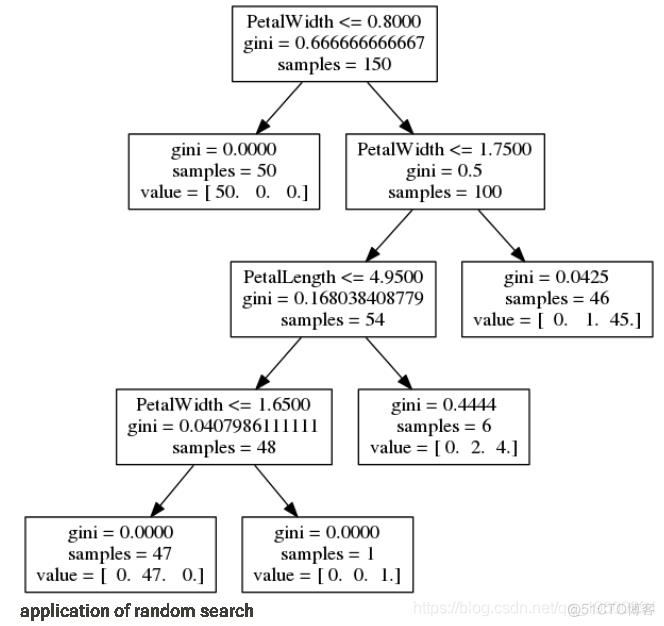
随机搜索的应用
接下来,我们尝试使用随机搜索方法来查找参数。在此示例中,我使用288个样本,以便测试的参数设置数量与上面的网格搜索相同:
与网格搜索一样,这通常会找到平均精度为0.967或96.7%的多个参数设置。如上所述,最佳交叉验证的参数为:
print("\n-- Best Parameters:")
for k, v in ts_rs.items():
print("parameters: {:<20s} setting: {}".format(k, v))
-- Best Parameters:
parameters: min_samples_split setting: 12
parameters: max_leaf_nodes setting: 5
parameters: criterion setting: gini
parameters: max_depth setting: 19
parameters: min_samples_leaf setting: 1
并且,我们可以再次测试最佳参数:
# test the retuned best parameters
)
-- Testing best parameters [Random]...
mean: 0.967 (std: 0.033)
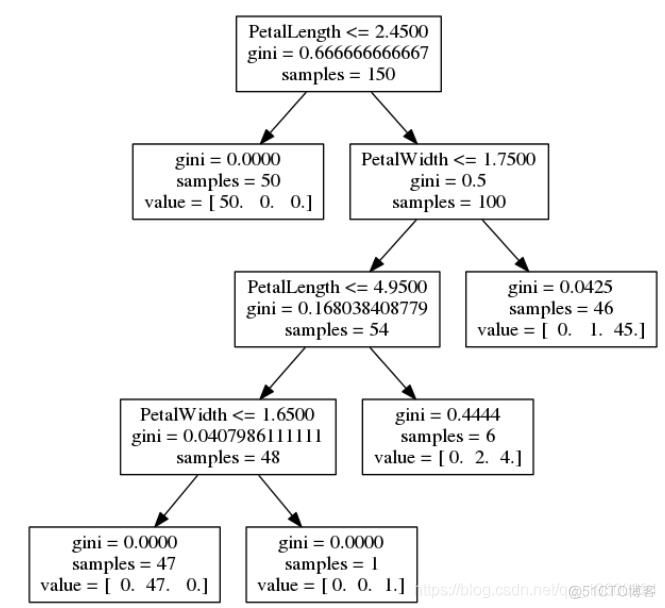
要查看决策树是什么样的,我们可以生成伪代码以获得最佳随机搜索结果
并可视化树
visualize_tree(dt_ts_rs, features, fn="rand_best")
结论
因此,我们使用了带有交叉验证的网格和随机搜索来调整决策树的参数。在这两种情况下,从96%到96.7%的改善都很小。当然,在更复杂的问题中,这种影响会更大。最后几点注意事项:
- 通过交叉验证搜索找到最佳参数设置后,通常使用找到的最佳参数对所有数据进行训练。
- 传统观点认为,对于实际应用而言,随机搜索比网格搜索更有效。网格搜索确实花费的时间太长,这当然是有意义的。
- 此处开发的基本交叉验证想法可以应用于许多其他scikit学习模型-随机森林,逻辑回归,SVM等。