
作者:Edison_G
在现在人工智能化时代,幼儿园也是一个众多家长关注的教育机构,在幼儿园小孩的安全是独一,在人工智能监控下,绝对保障了所有儿童的安全!

一、简要
对计算和内存的高需求是将现有目标检测网络部署到嵌入式设备中的最大挑战。现有的轻量级目标检测器直接使用轻量级神经网络架构,如MobileNet或在大尺度分类数据集上预先训练,导致网络结构灵活性差,不适用于某些特定场景。

在今天分享中,有研究者提出了一种轻量级目标检测网络Single-Shot MultiBox Detector(SSD)7种特征融合和注意机制(FFAM),该网络通过减少卷积层数,节省了存储空间,减少了计算量。研究者有提出了一种新的特征融合和注意机制(FFAM)方法来提高检测精度。首先,FFAM方法将高级语义信息丰富的特征图与低级特征图进行融合,提高了小目标的检测精度。采用由通道和空间注意模块级联的轻量级注意机制,增强目标的上下文信息,引导网络关注其易于识别的特征。
在NWPU VHR-10数据集上,SSD7-FFAM实现了83.7%的mAP、1.66MB参数和0.033s的平均运行时间。结果表明,该SSD7-FFAM更适合于部署到嵌入式设备上进行实时目标检测。

如果这种技术应用在现在的幼儿园,再和行为识别共同作用,是不是就可以保障小孩子的安全及行迹跟踪。
二、背景及动机

近年来,对可应用于嵌入式设备的轻量级目标检测网络的研究吸引了越来越多的研究者。不同的人工设计的轻量级神经网络架构已被用于目标检测,如谷歌提出的轻量级网络架构MobileNet,它使用深度可分离卷积而不是标准卷积。Face++通过逐点群卷积核信道变换技术,提出了ShuffleNet。
由Iandola等人介绍的SqueezeNet,它由两个部分组成,一个压缩层(压缩)和一个膨胀层(膨胀),通过减少压缩层中的通道数,减少了整个模型所需的计算量。AF-SSD应用了MobileNetV2和额外的卷积层,以ShuffleNetV2和深度可分离卷积作为轻量级主干。实验结果表明,AF-SSD是一种快速、准确、参数较少的检测器。许多其他研究表明,使用这些轻量级网络作为主干的目标探测器取得了最先进的结果。然而,这些轻量级网络在使用它们作为目标检测的主干网络之前,需要在通用数据集如ImageNet上进行预训练。预训练通常在一般图像分类任务的数据集上进行,因此很难将它们移植到特定的应用场景中,如医学图像检测。同时,这些预训练的网络模型具有大量的参数和固定的结构,使得难以优化。
- Single-Shot MultiBox Detector
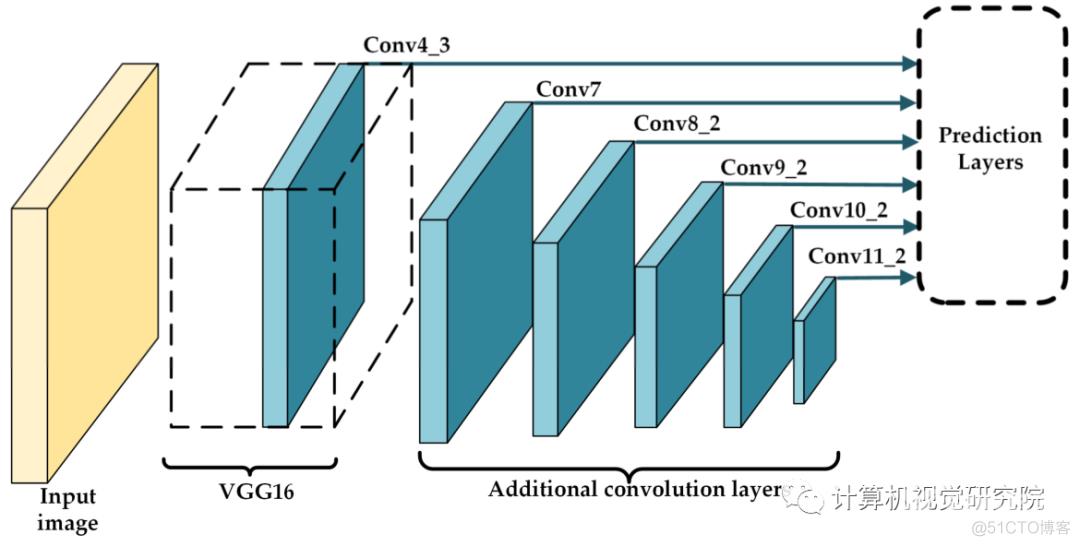
Single-Stage Detectors代表之一——SSD
yolo我们“计算机视觉研究院”已经分享了很多,如:
- Deep Feature Fusion
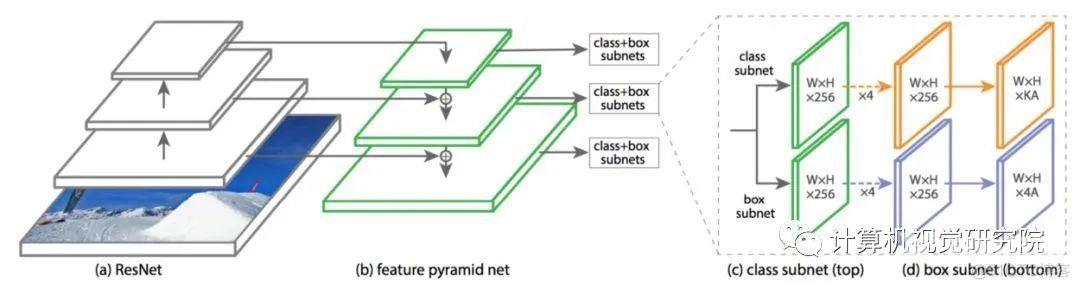
特征融合就有很多类似的案例,我们今天就不专门讲解了!
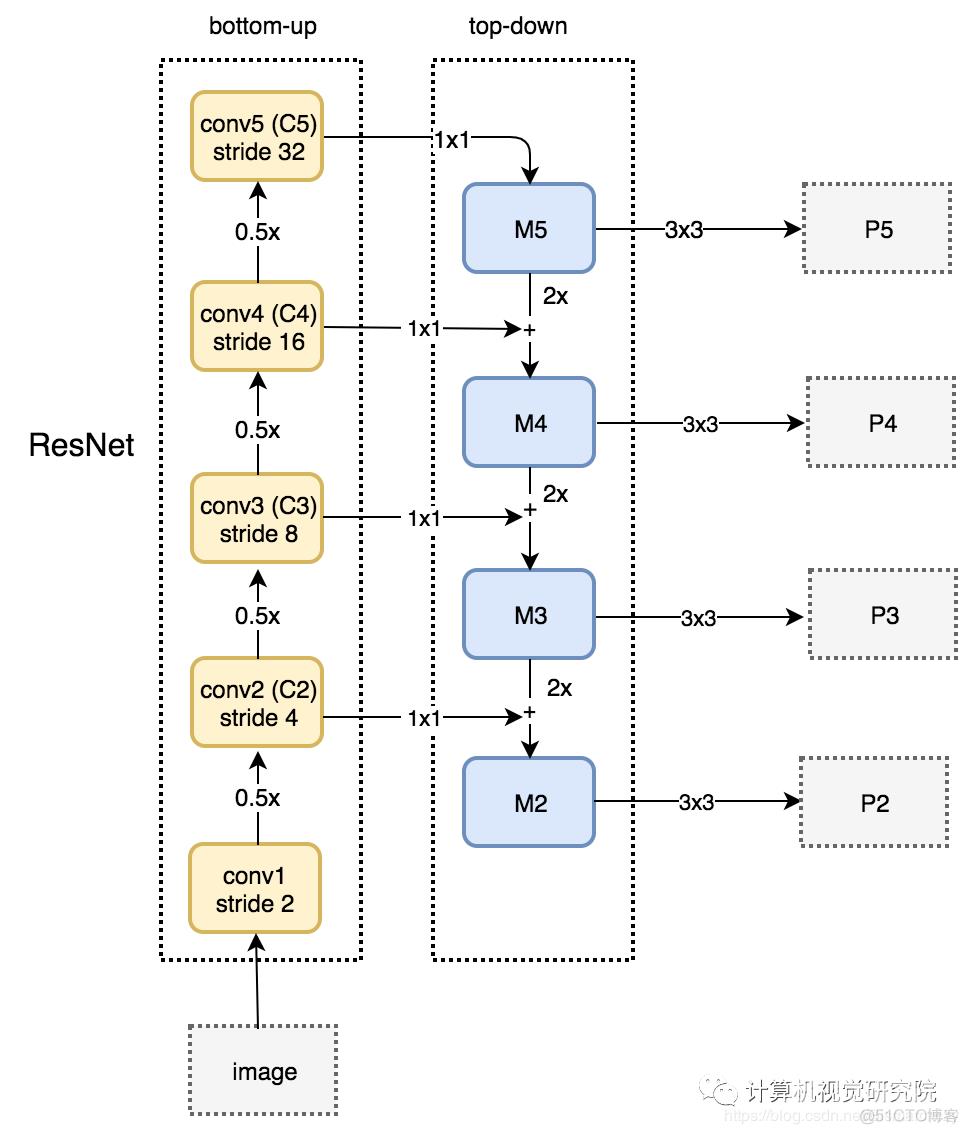
三、新框架
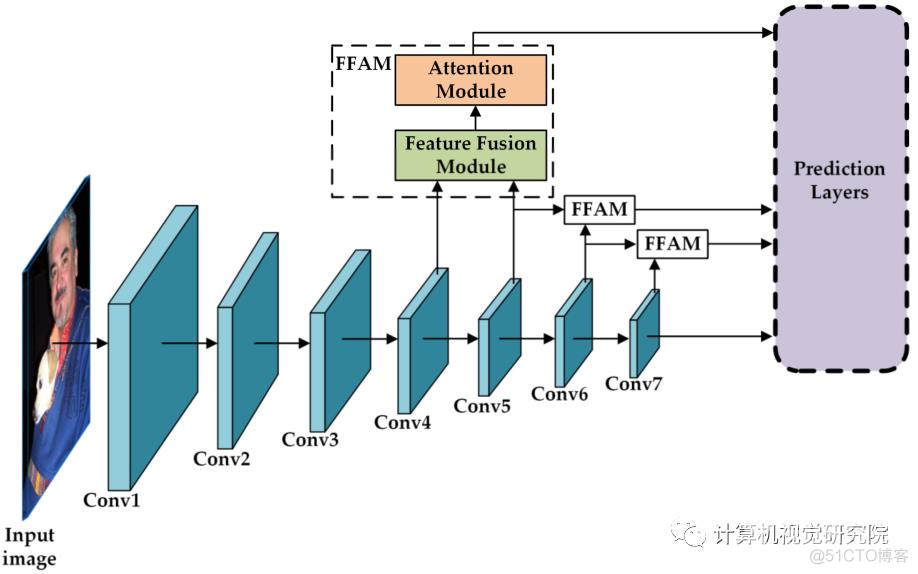
- Specific Structure of SSD7-FFAM
上图就描述了提出的SSD7-FFAM的具体结构。在SSD中,由VGG提取的特征图和附加卷积层分别用于目标的定位和分类。然而,初始的浅层特征图缺乏重要的语义信息,这个问题导致检测精度低于两级检测器。因此,SSD不利于对小物体的检测。
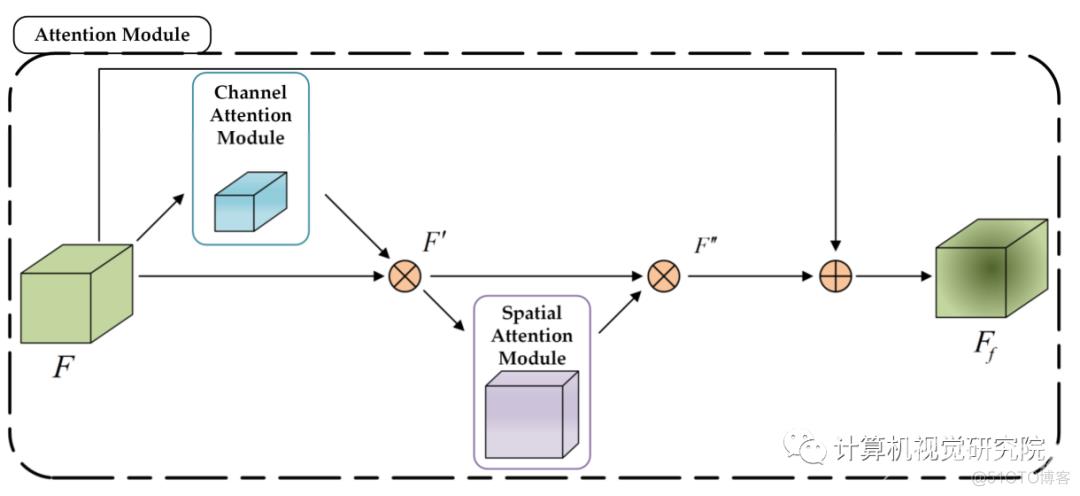
与SSD7不同的是,所提出的SSD7-FFAM采用了两个新的模块:特征融合模块和基于SSD7的注意模块,以弥补由于卷积层的下降所导致的检测精度的降低。特征融合模块将两个不同尺度的特征图组合成转换后的新的特征图。该模块增强了浅层特征图的语义信息。注意模块是一个结合了通道注意和空间注意的轻量级模块。它显著地提高了网络性能,同时提供了少量的计算和参数。
- Feature Fusion Module

上图显示了SSD7-FFAM中使用的特征融合模块结构示例。新的Conv4特征图与其他两个特征图一起传递到注意模块。
- Attention Module
Channel Attention Module
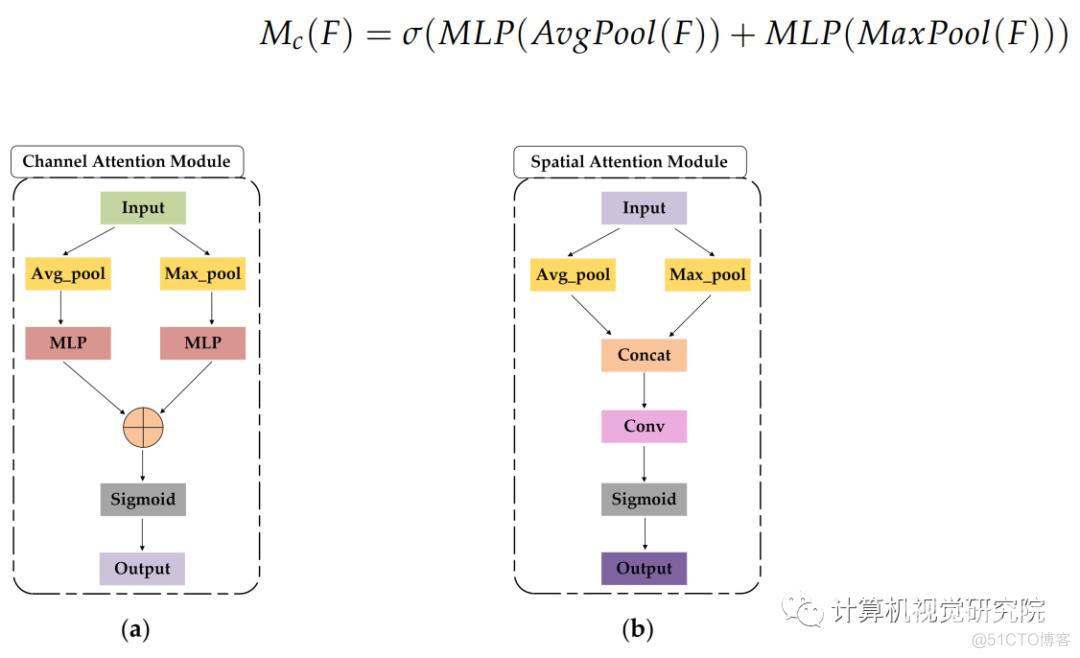
Spatial Attention Module
[Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. In Proceedings of the ICLR 2017]的作者指出,通道维度中的合并操作可以突出显示特征图的信息区域。在通道注意模块之后,研究者引入了一个空间注意模块,以关注特征有意义的地方。
与信道注意类似,鉴于信道注意模块之后的特征图F0,空间注意模块首先执行信道尺寸的平均池化和最大池化,以获得两个H×W×1信道特征,并根据信道将这两个特征缝合在一起。然后,在7×7卷积层后得到权重系数MS,激活函数为sigmoid。空间注意模块如上图b所示,计算结果为:
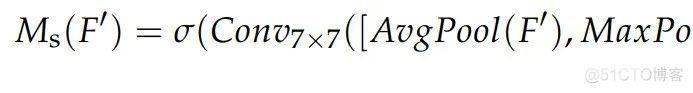
四、实验及分析
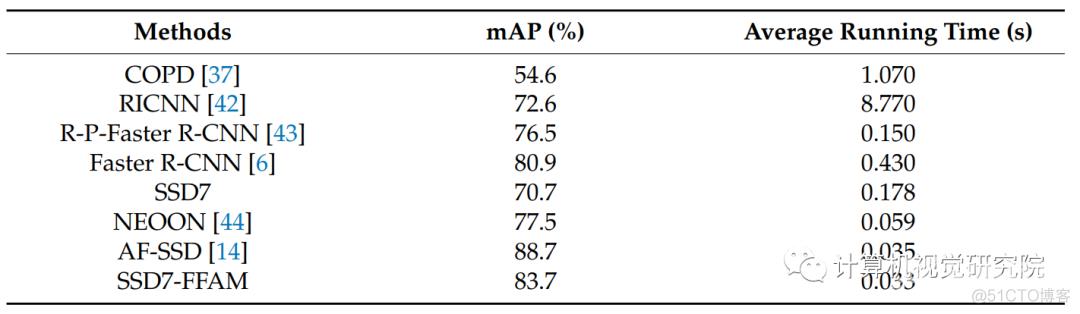
在NWPU VHR-10数据集上的测试结果
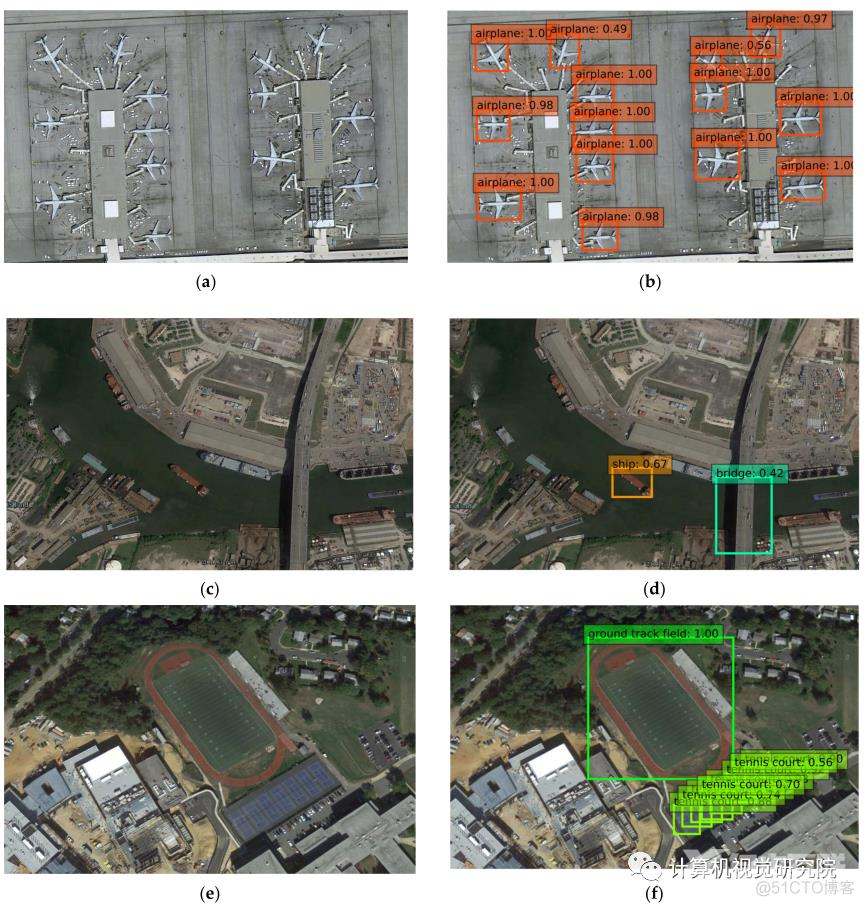
For each pair, the left (a,c,e) is the original image and right (b,d,f) is the result of the SSD7-FFAM. Each color corresponds to an object category in that image.
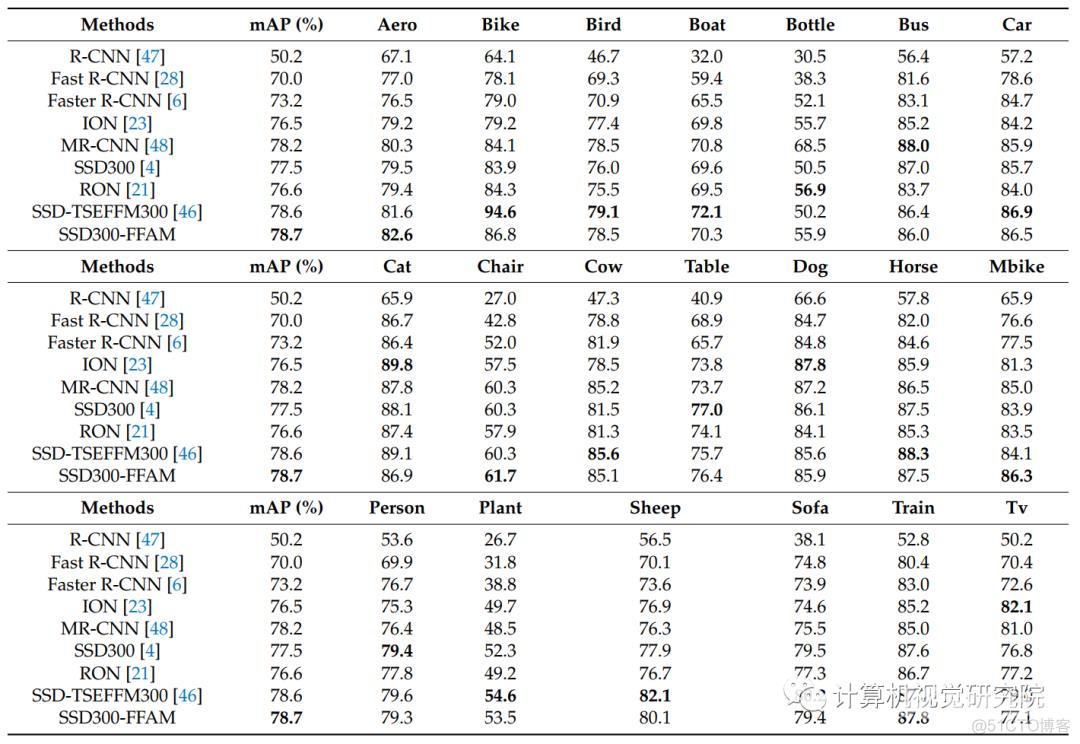
在VOC数据上的结果,如下表:
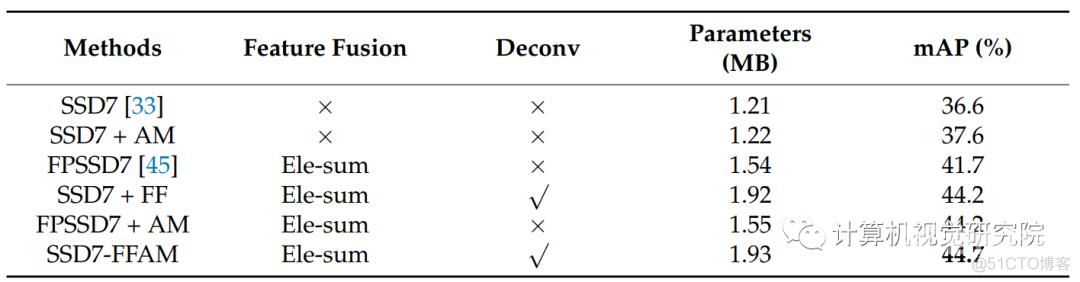
不同平均运行时间:


© THE END
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
