
编 辑:朱哥
彭友们好,我是老彭啊。作为数据行业的一名从业者,不仅要关注当前数据技术发展,还要关注数据技术未来发展趋势。
为什么?哎,这个社会内卷太厉害,牛人一大堆,稍有不小心,懈怠,没有核心竞争力,就会失业,丢饭碗,但仍然还要面对各种贷款,各种压力。
2022年初再回顾2021年的时候,发现数据技术界有个名词非常的火热-[data fabric],这不是在中国,而是在国外,国内呢,数据中台火的一塌糊涂。
到处都在谈数据中台,面试的时候,制定计划会议的时候,搞数据战略的时候,圆桌论坛上,到处都在谈。今天本文就不会再说这个话题了,来聊聊data fabric。
今天从以下四个方面来聊一聊:

data fabric起源
互联网世界,每隔10年,就会出现一个风口。15年前是数据仓库,5年前的大数据和数据湖,国内几天数据湖才热起来。今天有一个名叫Data Fabric的数据架构浮出水面,开始引发人们的广泛关注。
我们先来看看,当前的数据架构和十多年前有什么不同。在数据仓库时代,企业的数据量还不算大,一般几十个TB, 数据仓库的建设一般采用中心化的方式,将各个应用系统的数据,从各个系统抽取出来,清洗转换后,加载到数据仓库里。
由于架构相对简单,各种数据模型比较直观,相关的数据集成的工具软件及元数据管理的重要性并不突出,很多人选择了忽视这一部分。而到了大数据时代,由于非结构化数据的导入,数据量大了,企业拥有上PB的数据如家常便饭一样。但数据架构还是集中式,工具软件及元数据还是没有被广泛地应用,并且还不成熟。
今天已经到了一个云的时代,大家都在搞云原生。在企业内部,有各种业务系统,数据仓库(Data Warehouse)和很多针对各个部门的数据集市(Data Mart),大数据平台( Big Data Platform)和数据湖(Data Lake)往往也是不可缺少。
除了本地私有云平台,往往很多应用也会放到公有云平台之上,构建混合云,包括猪猪现在公司也是混合云的方式。在这样一个混合云,且分布式的数据架构中,如果我们为了获取数据,还要把数据搬移复制,集中到某一个地方去,其成本将会非常之大。
因此,是否有办法既不需要搬动数据,允许数据还是保留在各个应用系统里,又能让数数据科学家们和使用者,在需要的时候能够非常方便快捷地获取这些数据呢?于是,一个名为Data Fabric 的数据架构因此而诞生了。

到底什么是Data Fabric
Forrester是这样说的:“Data Fabric是以一种智能和安全的并且是自服务的方式,动态地协调分布式的数据源,跨数据平台地提供集成和可信赖的数据,支持广泛的不同应用的分析和使用场景”。
Gartner是这样说的:Gartner defines data fabric as a design concept that serves as an integrated layer (fabric) of data and connecting processes. A data fabric utilizes continuous analytics over existing, discoverable and inferenced metadata assets to support the design, deployment and utilization of integrated and reusable data across all environments, including hybrid and multi-cloud platforms.
Gartner 将数据结构定义为一种设计概念,它充当数据和连接过程的集成层(结构)。数据结构利用对现有、可发现和推断的元数据资产的持续分析,以支持跨所有环境(包括混合云和多云平台)设计、部署和利用集成和可重用数据。
Data Fabric 利用人和机器的能力来访问数据或在适当的情况下支持其整合。它不断地识别和连接来自不同应用程序的数据,以发现可用数据之间独特的、与业务相关的关系。洞察力支持重新设计的决策,通过快速访问和理解提供比传统数据管理实践更多的价值。
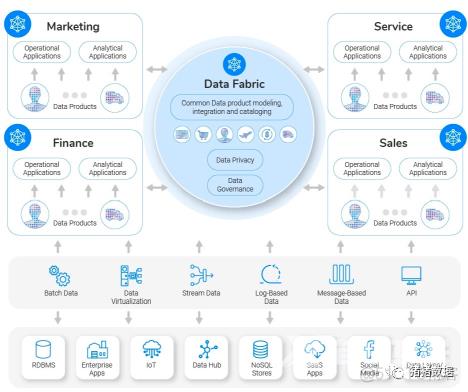
看到这里,大家有没有发现很难表述清楚,在和别人反复沟通和讨论,有人这样说:“使需要用数据的人,随时能够知道到他要的数据在哪里,数据质量如何,他可以如何方便地获取他需要的数据。Data Fabric 的主要作用:把正确的数据,在正确的时间,传送给正确的人。通过 Data Fabric , 对的人可以从对的地点,在对的时间,获取对的数据。

架构是什么样
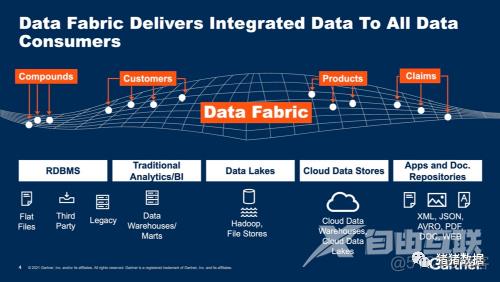
data fabric架构:

Gartner: An ideal, complete data fabric design with its many components.
Data Fabric 可以同时给业务和技术团队带来明确的价值。从业务层面来看,由于企业能更容易地获得高质量的数据,从而能更快和更精确地获得企业数据洞察。数据科学家和业务人员能够花更多时间在数据分析上,而不是去寻找和准备数据,可以给数据使用者提供完美的自我服务的数据消费体验。
优质和全面的数据,可以避免由于数据访问的限制而造成的数据分析偏差,从而可以提升企业数据的合规性和安全性。
从技术层面来说,由于较少的数据复制的次数和数量,从而减少了数据集成的工作,方便维护数据质量和标准,也减少了硬件架构和存储的开销。 由于减少了数据复制和大大优化了数据流程,加快并简化了数据处理过程,从而通过实施自动化的整体数据策略,减少了数据访问管理的工作。
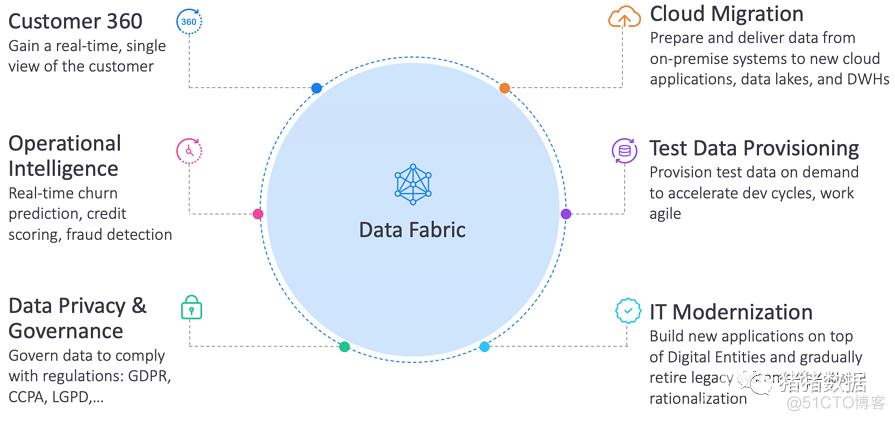
要实现上述的Data Fabric 的目标,至少需要四个方面的基本能力:
1.能够在数据之间建立虚拟链接,简化数据访问的模式,从而减少数据复制的数量。
2. 需要建立一个企业的数据目录,并需要利用AI技术,自动化地实现基于语义和知识的分析,理解数据及其业务含义,并建立知识图谱, 从而使数据目录变得智能化和自动化。能够让需要数据的用户,随时了解他所需要的数据在哪里、数据质量如何等。
3. 建立自动化的数据平台,并且允许用户通过自服务的方式,访问并获取数据。
4. 通过提供整体的自动化策略,确保数据安全,增加数据的隐私和权限保护,并提高数据的质量。

各个厂商的解决方案
Data Fabric 目前是一个IT热点,众多国际著名的 IT公司包括IBM、informatica和 Telend等,均推出了针对 Data Fabric 的解决方案。
其中,IBM 公司的Cloud Pak for Data针对上述Data Fabric 必须具备的四个基本能力,都能给予很好的支持。IBM早在十多年前,就已经推出了有关数据虚拟化的方案Data Virtualization, 目前这个方案的功能日趋丰富。
IBM的数据目录Watson Knowledge Catalog是业界最强大的智能数据目录解决方案,其中大量使用了IBM企业级 AI和机器学习的技术,使数据目录智能化和自动化,并具有知识图谱的能力,方便业务用户使用。
IBM数据目录方案内嵌了数据安全和数据隐私保护的功能,确保在数据共享的过程中能符合GDPR的数据隐私保护要求。同时,IBM作为一个老牌的专业数据集成的供应商,其数据复制和数据集成的自服务能力也日趋完善。IBM Cloud Pak for Data 应该是目前业界应对 Data Fabric 功能最为完善的数据平台。
Data Fabric 这个概念在国际上已经热起来了,但目前国内的IT用户知道的人还不多。20年前数据仓库在国外兴起后,用了6到8年才传到中国。10年前大数据的概念在国外兴起后,不到三年就被中国用户广泛接受。目前这个 Data Fabric 概念,中国可以用多快的速度接受并加以应用呢?我们拭目以待!
扩展阅读:公众号“大数据架构师”后台回复“数据编织”即可下载4份数据编织高质量资料及IBM数据编织解决方案~~~

排版 | 老彭
审校 主编 | 朱哥