Java全能学习+面试指南:https://javaxiaobear.cn
今天我们一起看看大型互联网系统架构的演进之路,主要包含三部分内容。
-
第一部分是大型互联网系统的特点,分析大型互联网有哪些特点和挑战,它们是现在一些技术和架构方案产生的原因。
-
第二部分是系统处理能力提升的两种途径,提供了两种面对挑战的解决思路。
-
第三部分是大型互联网系统架构演化过程,这个过程几乎包含了现在所有主要的互联网架构的考量点、技术方案、要解决的问题等,是整个互联网系统架构的一个综述,可以了解互联网架构的全貌。
大型互联网系统的特点
首先我们来看下,大型互联网系统的特点有哪些?
高并发和大流量
大型互联网需要面对高并发的访问用户,比如在天猫“双11”的时候,一分钟之内,有超过一千万的独立用户访问整个天猫系统,大规模的并发用户访问会对系统的处理能力造成巨大的冲击,系统必须要有足够强的处理能力才能够满足。同时有这么多用户来访问,产生了巨大的访问流量,对系统的抗压能力形成了考验。
高可用
大型互联网系统必须要 7×24 小时不间断地提供服务,和传统软件系统不同,银行或者是电信甚至零售业,它们都有下班时间,下了班以后可以对系统进行停机维护和升级发布,但是互联网没有下班时间,所以一直要保持高可用,7×24 小时永不间断。为了保证系统的高可用,必须要进行特别的系统架构设计。
海量的数据存储
因为互联网需要满足大量的用户使用,所以这些用户会产生很多的数据,需要对这些数据进行重组和管理。除了用户提交的数据,互联网还会采集很多其它的数据,包括一些用户行为的数据、第三方的数据以及网络爬虫获取的数据,通过大数据技术对这些数据做进一步分析,对用户进行更精准的营销和服务,以发现新的业务增长点。
用户分布广泛,网络情况复杂
互联网是为全球用户提供服务的,用户分布范围广,各地的网络情况千差万别,为了使所有用户能够得到统一的良好的体验,需要对系统架构进行相关的设计。
安全环境恶劣
因为互联网是开放的,所以互联网站很容易就会受到gongji。
需求变化快,发布频繁
和传统的软件版本发布频率比,互联网产品为了快速适应市场,满足用户需求,发布频率是非常高的。比如 Office 这样的产品发布版本是以年为单位的,而大型网站的产品发布一般是以周为单位的,每个星期都会发布新的版本来更新产品特性。
系统处理能力提升的两种途径
因为互联网主要面对的技术挑战就是用户量不断上升产生的并发访问压力以及数据存储压力,所以系统需要更强的处理能力才能解决这些问题。那么如何解决这些问题?主要有两种途径。
垂直伸缩
提升系统处理能力有两种途径,其中一种叫作垂直伸缩,如下图所示。

所谓的垂直伸缩就是提升单台服务器的处理能力,比如说用更快频率、更多核的 CPU,用更大的内存,用更快的网卡,用更多的磁盘组成一台服务器,使单台服务器的处理能力得到提升,通过这种手段提升系统的处理能力。
水平伸缩
除了垂直伸缩,还有一种手段叫作水平伸缩,如下图所示。

所谓的水平伸缩,是说不提升单机的处理能力,并不使用更昂贵的、更快的、更厉害的硬件,而是使用更多的服务器,将这些服务器构成一个分布式集群。这个集群统一对外提供服务,来提高系统整体的处理能力。
垂直伸缩的局限
在大型互联网出现之前,传统的软件,比如银行、电信这些企业的软件系统,主要是使用垂直伸缩这种手段实现系统能力提升的,先是提升服务器的硬件水平,就像我们刚才说的,提升 CPU 的能力、提升网卡的能力、提升内存和磁盘的能力。当某种类型的服务器能力提升到了瓶颈以后,就会用更强大的服务器,比如说从服务器升级到小型机,从小型机提升到中型机,从中型机提升到大型机,服务器越来越强大,处理能力也越来越强大,当然价格也越来越昂贵,运维越来越复杂。
而在互联网行业中多采用水平伸缩的手段。这主要是因为垂直伸缩有一些缺点。

-
当垂直伸缩达到一定程度以后,继续增加计算需要花费更多的钱。如果你服务器的内存条没有插满,这个时候你插一条内存不会花费太多的钱。但是如果内存条已经插满了,你想要更强大的容量、更大内存空间,就需要购买更强大的服务器对整体进行升级,这个时候就需要花更多的钱。而从服务器到小型机,到中型机,再到大型机,每一次这种硬件的升级,都意味着成本数十倍的增加。
-
垂直伸缩是有物理极限的。单单一台机器的处理能力是有极限的,即使是大型机,也有自己的物理极限,它不可能无限地伸缩下去。相对于硬件的极限,互联网的用户需求几乎是没有极限的。更何况到了物联网时代,数据产生的速度和对系统处理能力的要求更是成千上万倍的增加。
-
操作系统的设计或者应用程序的设计制约着垂直伸缩。因为垂直伸缩就意味着程序在单一服务器上运行,那么这个程序应用以及操作系统要相应具备管理这么庞大的计算资源的能力。要使用这些计算资源,就需要应用程序本身去管理、调度这些资源,这对应用程序以及操作系统的设计提出了极大的挑战。并且,我们知道,应用程序的核心价值是处理业务逻辑,从而满足用户需求,如果应用程序里有大量的代码是去管理系统资源的,必然导致应用程序复杂度提高,难以开发和维护。
与之相比,水平伸缩就没有这些问题。采用水平伸缩,只要架构合理,能够将服务器添加到集群中,你的系统是可以始终正常运行的。它没有极限,成本也不会在某个临界点突然增加。甚至,逐渐增加服务器,获得更强的计算处理能力,还比以前的服务器更便宜,因为硬件的价格总是在不断下降的。
同时,你的应用程序虽然是为单一服务器而设计的,但水平伸缩只是让程序部署在更多的服务器上,并不需要对应用程序进行太多的改变,应用程序不会受到硬件制约。
但是要让更多的服务器构成一个整体,需要在架构上进行设计,让这些服务器成为整体系统中的一个部分,把它们有效地组织起来,统一提升系统的处理能力。
大型互联网架构演化进程
下面我们通过大型互联网系统架构的演进过程,来详细讲解如何通过水平伸缩方式逐步提升系统处理能力。
这个过程看起来像是一个业务演进过程,也是用户量不断增长的过程。实际上驱动大型互联网的技术发展的就是不断增加的用户量。数据量随着用户量的增加而增加,导致并发访问压力持续增大,产生了一系列技术挑战。为了应对这些挑战,要不断地增强系统的技术处理能力,优化系统的架构,如下图所示。
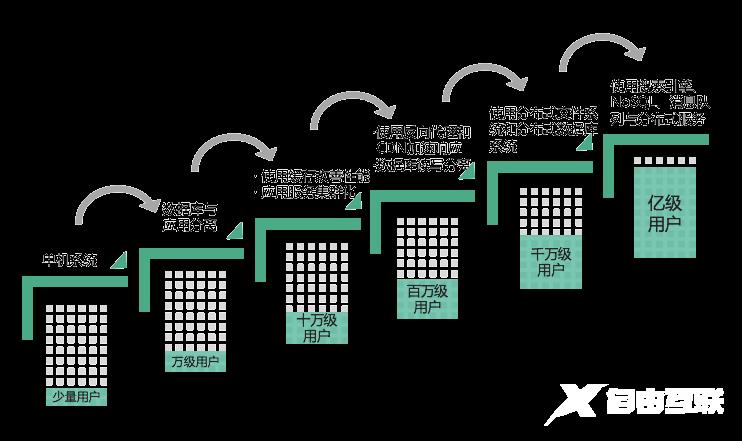
最早的时候是单机系统,这时候可以满足少量用户的使用;随着数据量提升,需要进行应用服务器与数据库分离,这时候可以满足万级用户的使用;再然后需要通过分布式缓存和服务器集群提升系统性能,可以满足十万级的用户;之后需要进行反向代理,CDN 加速,还需要数据库读写分离,以满足百万用户级的访问;随着数据量爆发式增长,使用分布式文件系统和分布式数据库系统,以满足千万级用户的访问;最后使用搜索引擎、NoSQL、消息队列、分布式服务等更复杂的技术方案,以满足亿级用户的访问。
单机系统
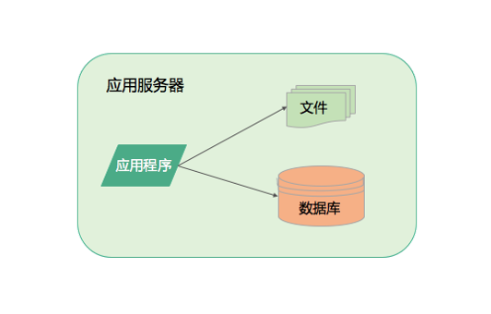
先来看单机系统,在最早的时候,系统因为用户量比较少,可能只是有限的几个用户,这个阶段系统主要是用来验证技术以及业务模式是否可行,系统也不需要太复杂,只需要具备有限的几个主要功能。应用程序开发完以后,部署在应用服务器上,一个应用访问自己服务器上的数据库,访问自己服务器的文件系统,如下图所示,这就构成了一个单机系统,这个系统就可以满足少量用户使用了。
如果这个系统被证明是可行的、有价值的、好用的,比如 Google 的搜索引擎系统,会逐渐吸引其他用户,造成用户访问增长。Google 最早就是部署在斯坦福的实验室里面,给实验室的同学和老师使用的。这些同学和老师使用后发现 Google 的搜索引擎比以前的搜索引擎(比如说像 Yahoo 这样的搜索引擎)要好用的多,这个消息很快就扩散出去了,整个斯坦福大学的老师同学可能都会过来访问这个服务器。这时候服务器就不能够承受访问压力了,需要进行第一次升级——数据库与应用分离。数据库与应用分离如下图所示,而前面单机的时候,数据库和应用程序是部署在一起的。

缓存
进行第一次分离的时候,应用程序、数据库、文件系统分别部署在不同的服务器上,从 1 台服务器变成了 3 台服务器,那么相应的处理能力就提升了 3 倍。这种分离几乎是不需要技术成本的,只需要把数据库文件系统进行远程部署和远程访问就可以了,这个时候的处理能力提升了 3 倍。
然而随着用户进一步的增加,更多的用户过来访,3 台服务器也不能够承受这样的压力了,那么就需要使用缓存改善性能,如下图所示。

通过这样一种手段,将一台数据库服务器水平伸缩成两台数据库服务器,可以提供更强大的数据处理能力。
反向代理和 CDN 加速
在对数据库做读写分离以后,要想更进一步增加系统的处理能力,需要使用反向代理和 CDN 加速,如下图所示。

所谓的 CDN 是指距离用户最近的一个服务器,当访问一个互联网应用的时候,我们的访问请求并不是直接到达互联网站的数据中心的,而是通过运营服务商进行数据转发的。那么在进行数据转发的时候,最好已经有我们想要访问的数据,这样就不需要访问互联网数据中心了。这个服务就叫作 CDN 服务。
CDN 服务就是部署在网络运营商机房里的离用户最近的一个服务器,用户请求先到这里查询有没有用户需要的数据,如果有,就从 CDN 直接返回,如果没有,再通过 CDN 进一步访问网站的数据中心,得到数据后再缓存到 CDN 供其他用户访问或下一次访问,所以 CDN 的本质还是一个缓存。
用户请求到达网站的数据中心后,也不是直接请求应用服务器,依然是查找一次缓存,这个缓存叫作反向代理服务器。
反向代理服务器是指通过反向代理的方式代理整个网站的请求服务,先在反向代理服务器中查找是否有用户请求的数据,如果有,就从反向代理服务器直接返回;如果没有,再去请求应用服务器。通过这样的 CDN 和反向代理两级缓存,可以返回绝大部分用户请求的网络数据,极大地减少应用服务器的负载压力,提升服务器数据中心的处理能力,响应更多的用户并发处理请求。
分布式文件系统和分布式数据库系统
更进一步思考,虽然 CDN 和反向代理已经缓存了大量的用户数据,返回了大量的用户请求,但是随着用户量的增加,还是有很多的用户请求会到达数据中心。这个时候文件系统和数据库系统依然会成为瓶颈点。
那么如何解决这个瓶颈点?解决方案主要是分布式的文件系统和分布式的数据库系统。如下图所示。

所谓的分布式文件系统就是通过一组服务器集群统一对外提供文件服务。像淘宝的商品图片服务以及 Facebook 这样的相册服务,每天都有大量的用户上传大量的图片,那么如何管理这些海量的文件图片?这就要使用一个分布式的文件服务器系统。
随着数据量逐渐增加,前面讲的主从数据库也不能够承受这么大的访问压力和存储容量要求,那么就需要对数据库做进一步水平伸缩,使用分布式的数据库。即通过数据分片的方式,将一张表的数据分布在多个物理服务器上,以减少单一数据库的服务器访问压力。通过这样的手段可以进一步提升系统的处理能力。
消息队列与分布式服务
最后,随着用户量进一步增加,要想实现更强大的计算处理能力,可以使用的技术手段有分布式消息队列服务、搜索引擎和 NoSQL,以及通过分布式服务,将可复用的业务分离开来,部署在不同的服务器集群上。
用户量增加,除了意味着用户对系统的访问压力增加,还伴随着业务复杂度增加。使用分布式消息队列和分布式的服务,主要解决的就是业务增加时系统的复杂度问题。如下图所示。

随着业务的增加,很多的业务都有一些重复的服务功能需要复用,这时候使用分布式的服务去解决服务的复用问题。而不同的服务、不同的应用之间,它们的耦合关系会使得系统更加复杂,这时候使用分布式消息队列服务,将不同的应用服务器进行解耦,通过消息进行连接,而不是服务调用的方式或者应用调用的方式进行连接,使它们之间的关系变得低耦合,使服务变得更加简单,使系统的处理能力和扩容能力变得更加的强大。
总结
首先,大型互联网系统的挑战主要包括:高并发和大流量请求的挑战,高可用的挑战,海量数据的挑战,网络情况复杂、安全性差的挑战,以及需求快速变更、发布频繁的挑战。为了应对这样的挑战,需要提升系统的处理能力。处理能力提升有两种手段,一种是垂直伸缩,一种是水平伸缩。垂直伸缩有自身的局限性,所以在互联网企业中主要使用的手段是水平伸缩。
水平伸缩的原理就是不断地增加服务器以提高系统的处理能力。而如何添加新服务器,使新的服务器和原有的服务器构成一个完整的整体对外提供服务,就是互联网架构的主要技术挑战和技术内容。
在应对挑战的过程中,互联网架构主要的应对方法,就是从单机系统到分布式系统。即通过服务器拆分的方式,系统架构从单机系统一个服务器变成很多个服务器。这是整个发展思路以及发展过程。
其中最主要的发展阶段包括:
-
使用分布式的缓存,提高系统的访问特性,减少数据存储的压力;
-
使用负载均衡,提供更多的应用服务器提高系统计算处理能力;
-
使用分布式存储,提供更多的服务器,分摊数据的读写压力;
-
使用微服务与异步架构,使系统变得更加低耦合,使应用业务变得更加可复用,提升业务处理能力,从而支撑起一个大型网站系统架构。
本课技术架构演化提到的各种技术,比如分布式缓存,异步架构,分布式数据库,分布式微服务架构,高性能、高可用、安全的系统架构和案例分析等,都会在后续课程中详细阐述。