1.1 什么是prometheus?
Prometheus是一个开源监控系统,它前身是SoundCloud的警告工具包。从2012年开始,许多公司和组织开始使用Prometheus。该项目的开发人员和用户社区非常活跃,越来越多的开发人员和用户参与到该项目中。目前它是一个独立的开源项目,且不依赖与任何公司。为了强调这点和明确该项目治理结构,Prometheus在2016年继Kurberntes之后,加入了Cloud Native Computing Foundation。主要具有如下功能:
-
多维 数据模型(时序由 metric 名字和 k/v 的 labels 构成)。
-
灵活的查询语句(PromQL)。
-
无依赖存储,支持 local 和 remote 不同模型。
-
采用 http 协议,使用 pull 模式,拉取数据,简单易懂。
-
监控目标,可以采用服务发现或静态配置的方式。
-
支持多种统计数据模型,图形化友好。
1.2 核心架构
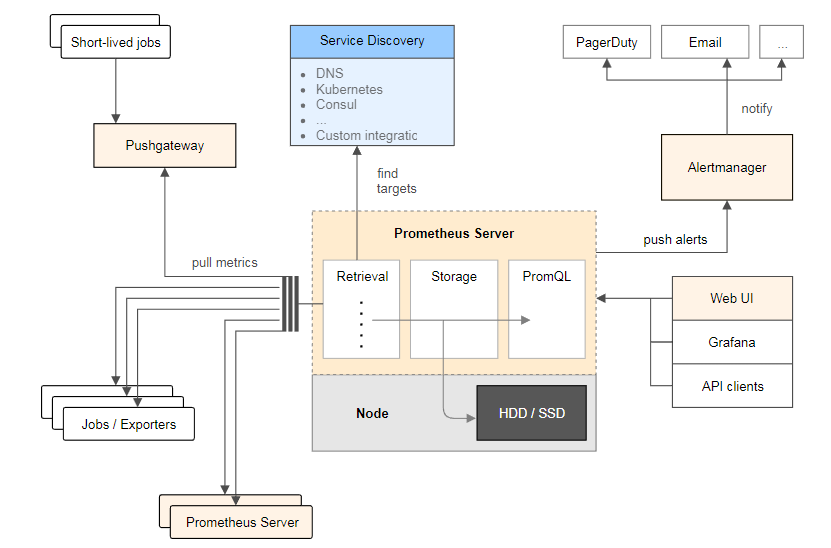
我们将通过prometheus的基础结构来详细了解,他的功能以及如何实现监控、告警的。如下如所示:

从这个架构图,也可以看出 Prometheus 的主要模块包含, prometheus server, exporters, pushgateway, PromQL, Alertmanager, WebUI 等。下面我就简单介绍各个组件实现的功能:
1. prometheus server: 定期从静态配置的 targets 或者服务发现(主要是DNS、consul、k8s、mesos等)的 targets 拉取数据。
2. exporters:负责向prometheus server做数据汇报的程序统。而不同的数据汇报由不同的exporters实现,比如监控主机有node-exporters,mysql有MySQL server exporter,更多请参考链接。
3. pushgateway:主要使用场景为:
Prometheus 采用 pull 模式,可能由于不在一个子网或者防火墙原因,导致 Prometheus 无法直接拉取各个 target 数据。在监控业务数据的时候,需要将不同数据汇总, 由 Prometheus 统一收集。
总结:实现类似于zabbix-proxy功能;
4. Alertmanager:实现prometheus的告警功能。
5. webui:主要通过grafana来实现webui展示。
1.3 适用场景
Prometheus在记录纯数字时间序列方面表现非常好。它既适用于面向服务器等硬件指标的监控,也适用于高动态的面向服务架构的监控。对于现在流行的微服务,Prometheus的多维度数据收集和数据筛选查询语言也是非常的强大。Prometheus是为服务的可靠性而设计的,当服务出现故障时,它可以使你快速定位和诊断问题。它的搭建过程对硬件和服务没有很强的依赖关系。
Prometheus,它的价值在于可靠性,甚至在很恶劣的环境下,你都可以随时访问它和查看系统服务各种指标的统计信息。 如果你对统计数据需要100%的精确,它并不适用,例如:它不适用于实时计费系统。
二、基础概念
2.1 数据模型
Prometheus 存储的是时序数据, 即按照相同时序(相同的名字和标签),以时间维度存储连续的数据的集合。时序(time series) 是由名字(Metric),以及一组 key/value 标签定义的,具有相同的名字以及标签属于相同时序。时序的名字由 ASCII 字符,数字,下划线,以及冒号组成,它必须满足正则表达式 [a-zA-Z_:][a-zA-Z0-9_:]*, 其名字应该具有语义化,一般表示一个可以度量的指标,例如 http_requests_total, 可以表示 http 请求的总数。
时序的标签可以使 Prometheus 的数据更加丰富,能够区分具体不同的实例,例如 http_requests_total{method="POST"} 可以表示所有 http 中的 POST 请求。标签名称由 ASCII 字符,数字,以及下划线组成, 其中 __ 开头属于 Prometheus 保留,标签的值可以是任何 Unicode 字符,支持中文。
2.2 时序4种类型
Prometheus 时序数据分为 Counter, Gauge, Histogram, Summary 四种类型。
-
Counter:表示收集的数据是按照某个趋势(增加/减少)一直变化的,我们往往用它记录服务请求总量,错误总数等。例如 Prometheus server 中
http_requests_total, 表示 Prometheus 处理的 http 请求总数,我们可以使用data, 很容易得到任意区间数据的增量。 -
Gauge:表示搜集的数据是一个瞬时的,与时间没有关系,可以任意变高变低,往往可以用来记录内存使用率、磁盘使用率等。
-
Histogram:Histogram 由
<basename>_bucket{le="<upper inclusive bound>"},<basename>_bucket{le="+Inf"},<basename>_sum,<basename>_count组成,主要用于表示一段时间范围内对数据进行采样,(通常是请求持续时间或响应大小),并能够对其指定区间以及总数进行统计,通常我们用它计算分位数的直方图。 -
Summary:Summary 和 Histogram 类似,由
<basename>{quantile="<φ>"},<basename>_sum,<basename>_count组成,主要用于表示一段时间内数据采样结果,(通常是请求持续时间或响应大小),它直接存储了 quantile 数据,而不是根据统计区间计算出来的。区别在于:
a. 都包含 <basename>_sum,<basename>_count。
` b. Histogram 需要通过<basename>_bucket` 计算 quantile, 而 Summary 直接存储了 quantile 的值。
2.3 总结
prometheus是属于下一代监控,现在企业中大部分通过使用zabbix来实现主机、服务、设备的监控。与zabbix相比,zabbix还是存在一定的优势,比如丰富的插件、webui能完成大部分工作,而prometheus更多的配置是通过配置文件还实现,并且prometheus相当消耗资源。建议在使用的过程中,认真对比慎重选择,如果使用prometheus,就要配置更好的服务器资源,因为它的监控粒度更细,需要计算相关数值,最好使用SSD硬盘来提高性能。