1、问题发现 ??????Prometheus报警某服务的一个节点 Old GC过多,需要排查。 2、查看GC日志 ??????使用 tail -f gc.log 命令查看异常节点的GC日志,从日志可以看出Young GC过于频繁,竟然在1s内有
1、问题发现
??????Prometheus报警某服务的一个节点 Old GC过多,需要排查。
2、查看GC日志
??????使用tail -f gc.log命令查看异常节点的GC日志,从日志可以看出Young GC过于频繁,竟然在1s内有9次Young GC:

??????使用tail -f gc.log命令查看正常节点的GC日志,从日志可以看出,正常节点,很久才进行一次Young GC:

??????两个节点的JVM参数配置是完全一样的,并且负载均衡策略使用的是Ribbon默认的轮询策略,也就是说,两个节点能够接受到的请求是均衡的,不存在一个节点比另一个阶段负载大的情况。
??????使用jstat命令查看异常节点的Young GC频率,发现确实存在异常:

3、使用jps命令找出该应用进程的pid,再使用top -Hp pid命令查看该进程下占用CPU最多的线程id:
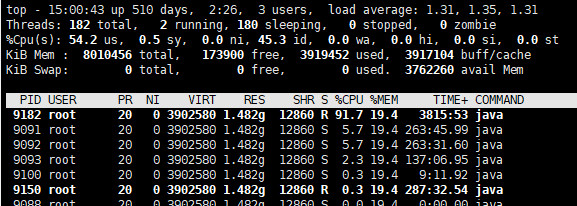
4、将查到的线程id 9182,使用printf "%x\n" 9182命令,转换为16进制:

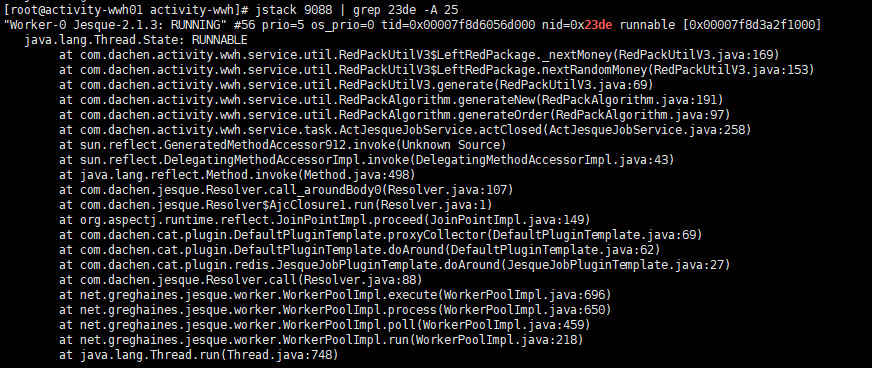
5、使用jstack 9088 | grep 23de -A 30命令查看堆栈信息(多次查看):
??????第一次:
??????第二次:
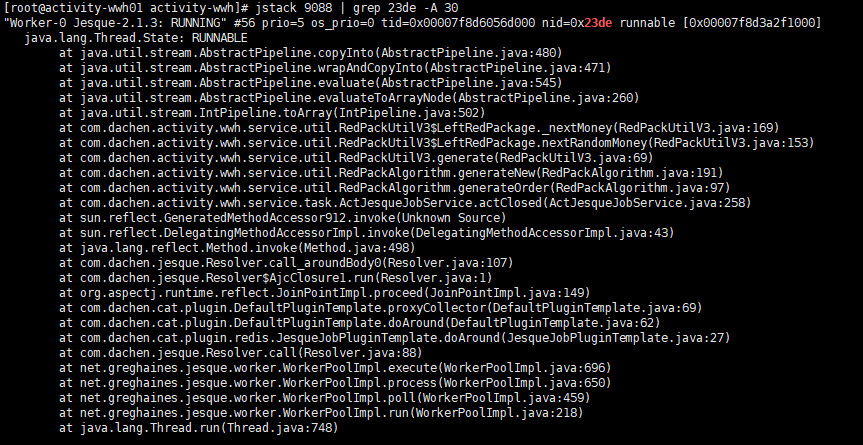
??????该线程一直处于Running状态,并且两次查看中发现,堆栈中有共同的方法调用,怀疑问题可能发生在RedPackUtilV3.java:169处,需要查看业务同学代码。
6、查看业务同学代码
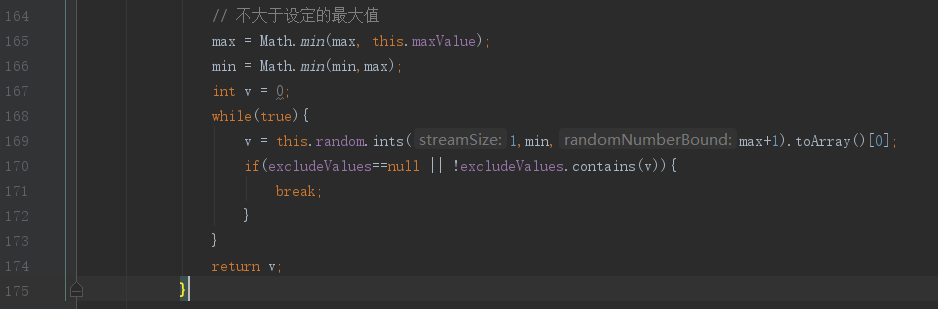 发现极有可能是while循环中break条件一直没成立,导致了死循环,最后就请业务同学自己检查代码逻辑了。
发现极有可能是while循环中break条件一直没成立,导致了死循环,最后就请业务同学自己检查代码逻辑了。