- 函数剩余部分
函数的三种定义方式
- 无参函数 不需要接受外部传入的参数
- 有参函数 需要接受外部传入的参数 注意传参数时多一不可、少一不可


1 # 函数的三种定义方式 2 # 无参函数 3 # 不需要接收外部传入的参数 4 def foo(): 5 print(‘from foo..‘) 6 foo() 7 8 9 10 # 有参函数 11 # 需要接收外部传入的参数 12 def login(user, pwd): 13 14 print(user, pwd) 15 # 16 # # 传参多一或少一不可 17 login(‘tank‘, ‘123‘) 18 # login(‘tank‘, ‘123‘, 111) # 多,报错 19 # login(‘tank‘) # 少,报错 20 21 # x = 10 22 # y = 20 23 # 24 # if x > y: 25 # 26 # print(x) 27 # 28 # else: 29 # print(y) 30 31 # 比较两数大小 32 def max2(x, y): 33 34 if x > y: 35 36 print(x) 37 38 else: 39 print(y) 40 41 max2(10, 30) 42 43 44 45 # 空函数 46 # 遇到一些比较难实现的功能,会导致暂时无法继续编写代码。 47 # 所以一般在生产开发中,都会将所有功能实现定义成空函数。 48 def func(): 49 pass # pass代表什么都不做View Code
注意:空函数(遇到一些比较难的功能,会导致暂时无法编写代码,所以一般在生产开发中,都会将所有功能实现定义为空函数)
def func():
pass //pass代表什么都不做
调用函数 你需要调用这个函数时,需要接受函数体内部产生的结果,用return返回值
有ruturn 和无return:
x = 10
y = 20
if x > y:
print(x)
else:
print(y)

注意:调用阶段才会执行函数体代码,定义阶段不会执行函数体代码!!
Print(函数名) 指向的是该函数的内存地址
函数名 返回的是函数的地址
函数名()返回的是调用函数的参数
字典选择 通过key的值选择内容

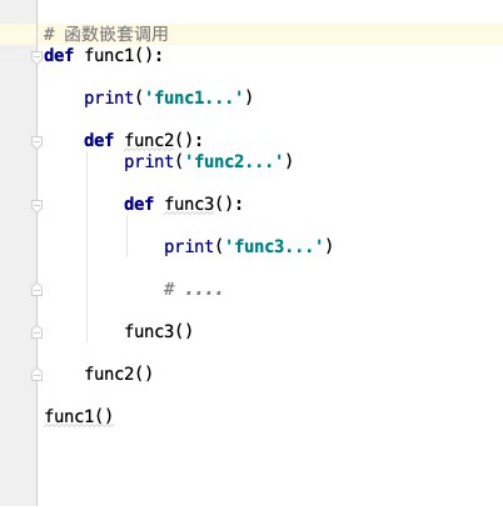
函数嵌套
嵌套定义:
在函数内,定义函数
函数调用
...
Way1

Way2
调用阶段才会执行函数体代码,定义阶段不会执行函数体代码
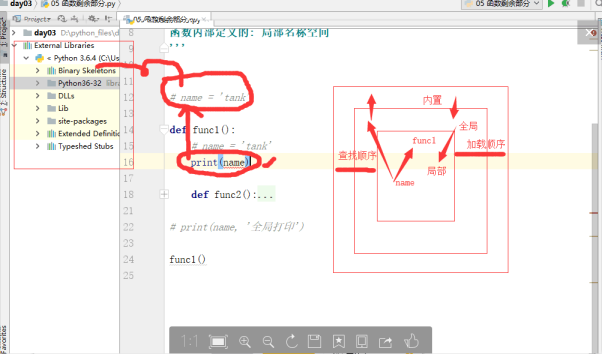
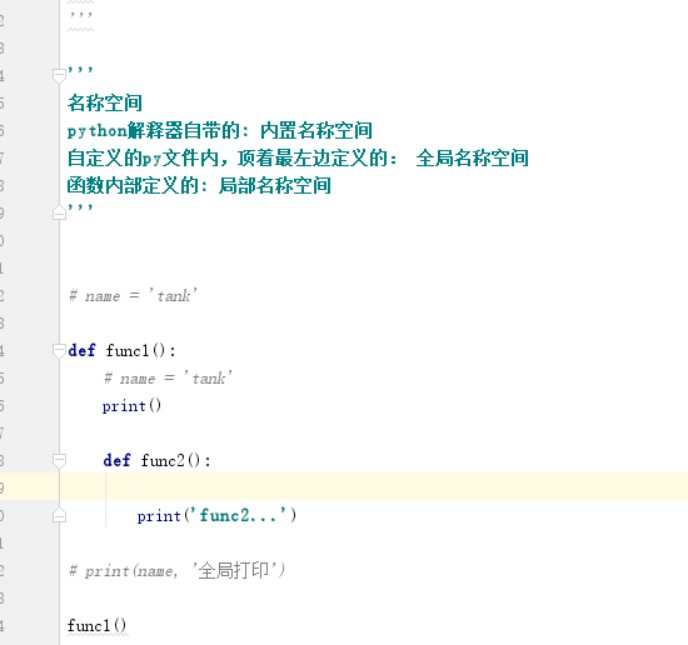
函数的名称空间 和作用域
Python解释器 冒蓝光说明这个各模块是解释器自带给你的:内置名称空间(python自带的)
自定义的py文件内,顶着最左边定义的:全局名称空间
函数体内部定义的:局部名称空间
内置名称空间
找变量
(查找顺序) 先在局部里找,再去全局里找 ,再到内置 python解释器终找
(加载顺序) 启动python解释器 再去全局 再去局部
面向对象的意思
模块与包 看一下博客 不太明白
文件夹称为模块
把文件.py导入进来来了 会自动执行里面的内容

- 内置模块(常用模块)
Import 模块名
Json第三方数据格式 picklepython自带数据格式 字典python语言独有的
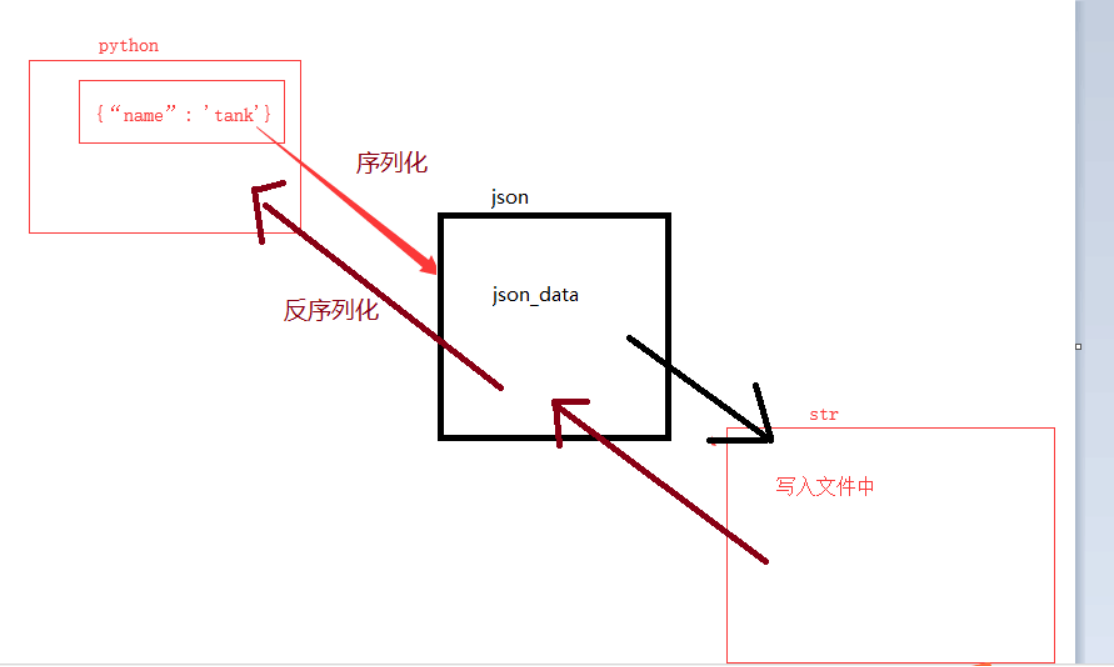
把python数据字典的给java程序用 存到数据库里 转成json格式 其他种类的程序员才可以用
把字典内容变成json数据 写入文件中 json_data (序列化)然后转化成字符串str形式写入文件中
从文件中读出字符串 转成json格式 再反序列化变成python格式
user_info={
‘name’:‘tank’
‘pwd’:‘123’
}
Dumps

Loads

Dump 自动触发f.write功能

Load 自动触发f.read方法

Time时间戳
Import time //导入time模块
//获取时间戳
print(time.time())
//等待10秒
time.Sleep(10)
Os
Import os 可以与操作系统中的文件交互
Os.path //拿到os里的所有操作路径
Print(os.path.exeits(‘tank.txt’)) //判断是否在当前目录下,这里的例子只输入了一个相对路径 正确返回True 错误False
Print(os.path.exeits(r‘。。。。。。。。。。。。’)) //绝对路径
拿到路径,判断路径是否存在

获取当前目录的根目录 见上
sys
Import sys
Print(sys.path) //获取pytho在环境变量中的文件路径
将项目的路径追加到用户安装的python.Exe路径

- 爬虫基本原理
只提取到有价值的信息,
爬虫就是模拟成浏览器 向目标站点发送请求,获得想要的有价值的部分
只需要关注http协议即可
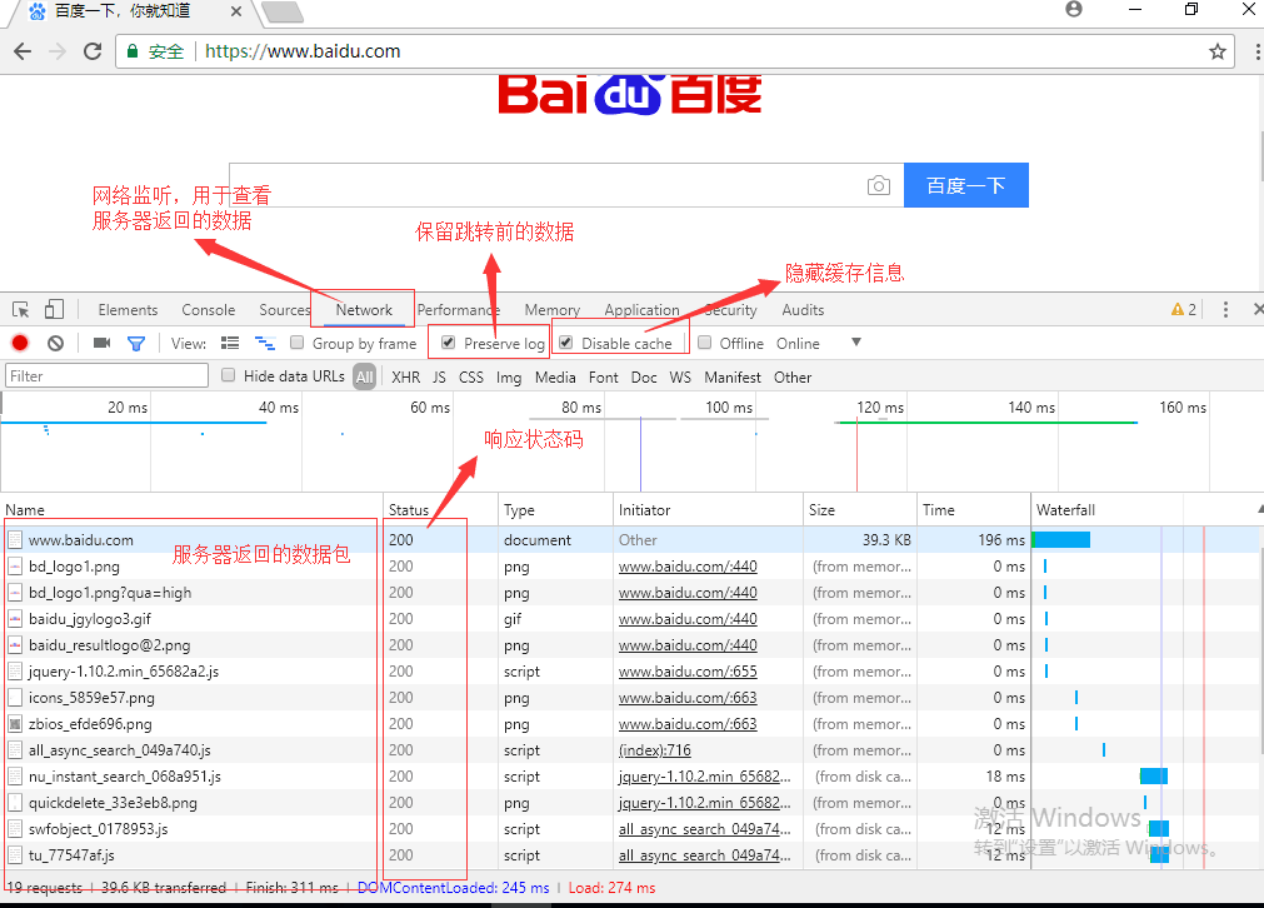
需要关注的信息:
Cookie 可能需要关注 有时候需要跳过认证 才能获得信息
User-agent他来判断你的浏览器和设备 证明你是浏览器 而不是机器人
Host 要确定目标网站的访问流程 确定需不需要带上
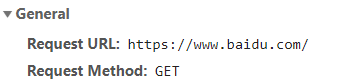
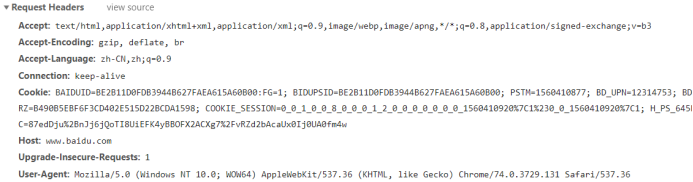
-
- Requests模块
可以从国内清华源里下载 加快速度
<>返回的都是一个对象
爬取视频
检查 左上角箭头 定位到网页的某一部分(视频)位置
双击鼠标得到视频路径
点击视频那快 就可以得到视频的路径
网视频的url发送请求
图片 视频返回的都是二进制流 res.content
把这些二进制流写进本地 就是一个完整视频
with open(‘视频.mp4’,‘wb’)as f:
f.write(res.content)
打开你爬取到的视频的文件夹