1、Scrapy框架 Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,
1、Scrapy框架
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了 Twisted'twɪstɪd异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
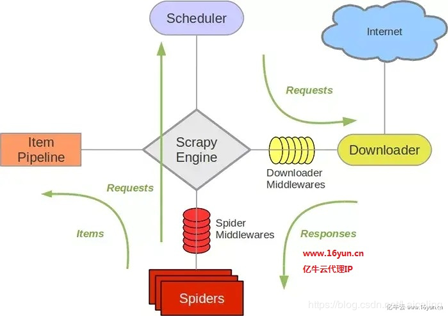
- Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
2、Puppeteer渲染
Puppeteer 是 Chrome 开发团队在 2017 年发布的一个 Node.js 包,用来模拟 Chrome 浏览器的运行。
为了爬取js渲染的html页面,我们需要用浏览器来解析js后生成html。在scrapy中可以利用pyppeteer来实现对应功能。
完整代码 📎scrapy-pyppeteer.zip
我们需要新建项目中middlewares.py文件(./项目名/middlewares.py)
import websockets
from scrapy.http import HtmlResponse
from logging import getLogger
import asyncio
import pyppeteer
import logging
from concurrent.futures._base import TimeoutError
import base64
import sys
import random
pyppeteer_level = logging.WARNING
logging.getLogger('websockets.protocol').setLevel(pyppeteer_level)
logging.getLogger('pyppeteer').setLevel(pyppeteer_level)
PY3 = sys.version_info[0] >= 3
def base64ify(bytes_or_str):
if PY3 and isinstance(bytes_or_str, str):
input_bytes = bytes_or_str.encode('utf8')
else:
input_bytes = bytes_or_str
output_bytes = base64.urlsafe_b64encode(input_bytes)
if PY3:
return output_bytes.decode('ascii')
else:
return output_bytes
class ProxyMiddleware(object):
USER_AGENT = open('useragents.txt').readlines()
def process_request(self, request, spider):
# 代理服务器
proxyHost = "t.16yun.cn"
proxyPort = "31111"
# 代理隧道验证信息
proxyUser = "username"
proxyPass = "password"
request.meta['proxy'] = "http://{0}:{1}".format(proxyHost, proxyPort)
# 添加验证头
encoded_user_pass = base64ify(proxyUser + ":" + proxyPass)
request.headers['Proxy-Authorization'] = 'Basic ' + encoded_user_pass
# 设置IP切换头(根据需求)
tunnel = random.randint(1, 10000)
request.headers['Proxy-Tunnel'] = str(tunnel)
request.headers['User-Agent'] = random.choice(self.USER_AGENT)
class PyppeteerMiddleware(object):
def __init__(self, **args):
"""
init logger, loop, browser
:param args:
"""
self.logger = getLogger(__name__)
self.loop = asyncio.get_event_loop()
self.browser = self.loop.run_until_complete(
pyppeteer.launch(headless=True))
self.args = args
def __del__(self):
"""
close loop
:return:
"""
self.loop.close()
def render(self, url, retries=1, script=None, wait=0.3, scrolldown=False, sleep=0,
timeout=8.0, keep_page=False):
"""
render page with pyppeteer
:param url: page url
:param retries: max retry times
:param script: js script to evaluate
:param wait: number of seconds to wait before loading the page, preventing timeouts
:param scrolldown: how many times to page down
:param sleep: how many long to sleep after initial render
:param timeout: the longest wait time, otherwise raise timeout error
:param keep_page: keep page not to be closed, browser object needed
:param browser: pyppetter browser object
:param with_result: return with js evaluation result
:return: content, [result]
"""
# define async render
async def async_render(url, script, scrolldown, sleep, wait, timeout, keep_page):
try:
# basic render
page = await self.browser.newPage()
await asyncio.sleep(wait)
response = await page.goto(url, options={'timeout': int(timeout * 1000)})
if response.status != 200:
return None, None, response.status
result = None
# evaluate with script
if script:
result = await page.evaluate(script)
# scroll down for {scrolldown} times
if scrolldown:
for _ in range(scrolldown):
await page._keyboard.down('PageDown')
await asyncio.sleep(sleep)
else:
await asyncio.sleep(sleep)
if scrolldown:
await page._keyboard.up('PageDown')
# get html of page
content = await page.content()
return content, result, response.status
except TimeoutError:
return None, None, 500
finally:
# if keep page, do not close it
if not keep_page:
await page.close()
content, result, status = [None] * 3
# retry for {retries} times
for i in range(retries):
if not content:
content, result, status = self.loop.run_until_complete(
async_render(url=url, script=script, sleep=sleep, wait=wait,
scrolldown=scrolldown, timeout=timeout, keep_page=keep_page))
else:
break
# if need to return js evaluation result
return content, result, status
def process_request(self, request, spider):
"""
:param request: request object
:param spider: spider object
:return: HtmlResponse
"""
if request.meta.get('render'):
try:
self.logger.debug('rendering %s', request.url)
html, result, status = self.render(request.url)
return HtmlResponse(url=request.url, body=html, request=request, encoding='utf-8',
status=status)
except websockets.exceptions.ConnectionClosed:
pass
@classmethod
def from_crawler(cls, crawler):
return cls(**crawler.settings.get('PYPPETEER_ARGS', {}))
然后修改项目配置文件 (./项目名/settings.py)
DOWNLOADER_MIDDLEWARES = {
'scrapypyppeteer.middlewares.PyppeteerMiddleware': 543,
'scrapypyppeteer.middlewares.ProxyMiddleware': 100,
}
然后我们运行程序

到此这篇关于Scrapy框架介绍之Puppeteer渲染的使用的文章就介绍到这了,更多相关Scrapy Puppeteer渲染内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!