前言 “ 等不到风中你的脸颊 眼泪都美到很融洽 等不到掩饰的雨落下 我的眼泪被你察觉 ” 听着循环的歌曲,写着久违的bug。好吧,还是一天。正好一个小伙伴说,要不要做个工具站玩
前言
“ 等不到风中你的脸颊
眼泪都美到很融洽
等不到掩饰的雨落下
我的眼泪被你察觉 ”
听着循环的歌曲,写着久违的bug。好吧,还是一天。正好一个小伙伴说,要不要做个工具站玩一下。我就随意的找了个工具站,看了下,发现很多都有文字的OCR识别功能。因此,我想起来之前了解的非常流行的开源的OCR大神级别的项目,Tesseract OCR。
简单介绍
官网如下所示

tesseract-ocr.github.io/
简洁明了,挂在github上的网站。
详细的不再介绍,感兴趣的,可以进入同志网站:https://github.com/tesseract-ocr/tesseract ,观摩学习。
实操准备
要想在开发中使用,还是需要接入对应的API。
对于开发者来说,提供了众多的Wrapper,来实现Api调用。
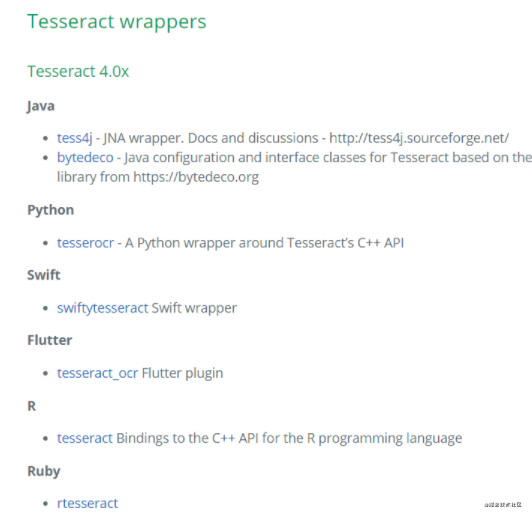
对于Java一名小开发,来讲,还是使用tess4j,作为Api来使用。官网如下:
tess4j.sourceforge.net/
可以直接下载jar包,或者采用Maven依赖下载。
<!-- https://mvnrepository.com/artifact/net.sourceforge.tess4j/tess4j --> <dependency> <groupId>net.sourceforge.tess4j</groupId> <artifactId>tess4j</artifactId> <version>4.5.3</version> </dependency>
开发实现
First 创建工程
Second 添加依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>test-textocr</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!-- https://mvnrepository.com/artifact/net.sourceforge.tess4j/tess4j -->
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>4.5.3</version>
</dependency>
</dependencies>
</project>
Third 填写类文件
package ocr;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.IOException;
/**
* ocr测试.
*
* @author huc_逆天
* @since 2021/1/12 17:42
*/
public class TestTextOcr {
public static void main(String[] args) throws IOException {
// 创建实例
ITesseract instance = new Tesseract();
// 设置识别语言
instance.setLanguage("chi_sim");
// 设置识别引擎
instance.setOcrEngineMode(1);
// 读取文件
BufferedImage image = ImageIO.read(TestTextOcr.class.getResourceAsStream("/2.jpg"));
try {
// 识别
String result = instance.doOCR(image);
System.out.println(result);
} catch (TesseractException e) {
System.err.println(e.getMessage());
}
}
}
Fifth 添加训练语言环境配置
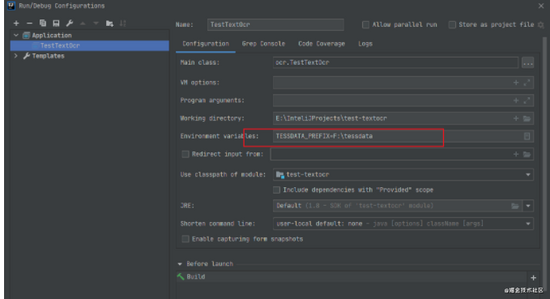
TESSDATA_PREFIX=F:\tessdata ,变量名,固定,值为官网下载文件 https://github.com/tesseract-ocr/tessdata
Sixth 运行
结果如下:

可能识别模式,不是很合适,切换下
instance.setOcrEngineMode(0);
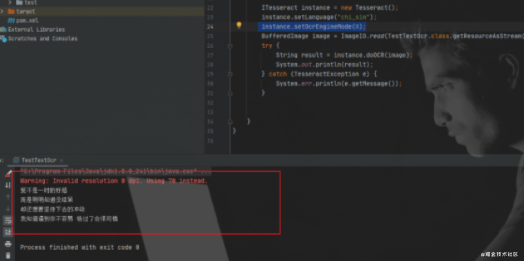
是不是舒服多了,哈哈。识别率瞬间上涨。
大家可以自行测试。
总结
好了,今天就到这了。技术在于折腾。多学习,让自己武装起来,变强大。
到此这篇关于SpringBoot+Tess4j实现牛逼的OCR识别工具的示例代码的文章就介绍到这了,更多相关SpringBoot Tess4j OCR识别内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!