1 Excel上传
针对Excel的上传,采用的是比较常规的方法,其实和文件上传是相同的。具体源码如下:
@PostMapping(value = "", consumes = "multipart/*", headers = "content-type=multipart/form-data")
public Map<String, Object> addBlacklist(
@RequestParam("file") MultipartFile multipartFile, HttpServletRequest request
) {
//判断上传内容是否符合要求
String fileName = multipartFile.getOriginalFilename();
if (!fileName.matches("^.+\\.(?i)(xls)$") && !fileName.matches("^.+\\.(?i)(xlsx)$")) {
return returnError(0,"上传的文件格式不正确");
}
String file = saveFile(multipartFile, request);
int result = 0;
try {
result = blacklistServcice.addBlackLists(file);
} catch (Exception e) {
e.printStackTrace();
}
return returnData(result);
}
private String saveFile(MultipartFile multipartFile, HttpServletRequest request) {
String path;
String fileName = multipartFile.getOriginalFilename();
// 判断文件类型
String realPath = request.getSession().getServletContext().getRealPath("/");
String trueFileName = fileName;
// 设置存放Excel文件的路径
path = realPath + trueFileName;
File file = new File(path);
if (file.exists() && file.isFile()) {
file.delete();
}
try {
multipartFile.transferTo(new File(path));
} catch (IOException e) {
e.printStackTrace();
}
return path;
}
上面的源码我们可以看见有一个saveFile方法,这个方法是将文件存在服务器本地,这样方便后续文件内容的读取,用不着一次读取所有的内容从而导致消耗大量的内存。当然这里大家如果有更好的方法希望能留言告知哈。
2 Excel处理工具源码
import org.apache.poi.openxml4j.opc.OPCPackage;
import org.apache.poi.xssf.eventusermodel.XSSFReader;
import org.apache.poi.xssf.model.SharedStringsTable;
import org.apache.poi.xssf.usermodel.XSSFRichTextString;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.helpers.XMLReaderFactory;
import java.io.InputStream;
import java.sql.SQLException;
import java.util.*;
/**
* XSSF and SAX (Event API)
*/
public abstract class XxlsAbstract extends DefaultHandler {
private SharedStringsTable sst;
private String lastContents;
private int sheetIndex = -1;
private List<String> rowlist = new ArrayList<>();
public List<Map<String, Object>> dataMap = new LinkedList<>(); //即将进行批量插入的数据
public int willSaveAmount; //将要插入的数据量
public int totalSavedAmount; //总共插入了多少数据
private int curRow = 0; //当前行
private int curCol = 0; //当前列索引
private int preCol = 0; //上一列列索引
private int titleRow = 0; //标题行,一般情况下为0
public int rowsize = 0; //列数
//excel记录行操作方法,以sheet索引,行索引和行元素列表为参数,对sheet的一行元素进行操作,元素为String类型
public abstract void optRows(int sheetIndex, int curRow, List<String> rowlist) throws SQLException;
//只遍历一个sheet,其中sheetId为要遍历的sheet索引,从1开始,1-3
/**
* @param filename
* @param sheetId sheetId为要遍历的sheet索引,从1开始,1-3
* @throws Exception
*/
public void processOneSheet(String filename, int sheetId) throws Exception {
OPCPackage pkg = OPCPackage.open(filename);
XSSFReader r = new XSSFReader(pkg);
SharedStringsTable sst = r.getSharedStringsTable();
XMLReader parser = fetchSheetParser(sst);
// rId2 found by processing the Workbook
// 根据 rId# 或 rSheet# 查找sheet
InputStream sheet2 = r.getSheet("rId" + sheetId);
sheetIndex++;
InputSource sheetSource = new InputSource(sheet2);
parser.parse(sheetSource);
sheet2.close();
}
public XMLReader fetchSheetParser(SharedStringsTable sst)
throws SAXException {
XMLReader parser = XMLReaderFactory.createXMLReader();
this.sst = sst;
parser.setContentHandler(this);
return parser;
}
public void endElement(String uri, String localName, String name) {
// 根据SST的索引值的到单元格的真正要存储的字符串
try {
int idx = Integer.parseInt(lastContents);
lastContents = new XSSFRichTextString(sst.getEntryAt(idx))
.toString();
} catch (Exception e) {
}
// v => 单元格的值,如果单元格是字符串则v标签的值为该字符串在SST中的索引
// 将单元格内容加入rowlist中,在这之前先去掉字符串前后的空白符
if (name.equals("v")) {
String value = lastContents.trim();
value = value.equals("") ? " " : value;
int cols = curCol - preCol;
if (cols > 1) {
for (int i = 0; i < cols - 1; i++) {
rowlist.add(preCol, "");
}
}
preCol = curCol;
rowlist.add(curCol - 1, value);
} else {
//如果标签名称为 row ,这说明已到行尾,调用 optRows() 方法
if (name.equals("row")) {
int tmpCols = rowlist.size();
if (curRow > this.titleRow && tmpCols < this.rowsize) {
for (int i = 0; i < this.rowsize - tmpCols; i++) {
rowlist.add(rowlist.size(), "");
}
}
try {
optRows(sheetIndex, curRow, rowlist);
} catch (SQLException e) {
e.printStackTrace();
}
if (curRow == this.titleRow) {
this.rowsize = rowlist.size();
}
rowlist.clear();
curRow++;
curCol = 0;
preCol = 0;
}
}
}
}
3 解析成功后的数据处理
首先我们将源码展示出来,然后再具体说明
public int addBlackLists(String file) throws ExecutionException, InterruptedException {
ArrayList<Future<Integer>> resultList = new ArrayList<>();
XxlsAbstract xxlsAbstract = new XxlsAbstract() {
//针对数据的具体处理
@Override
public void optRows(int sheetIndex, int curRow, List<String> rowlist) {
/**
* 判断即将插入的数据是否已经到达8000,如果到达8000,
* 进行数据插入
*/
if (this.willSaveAmount == 5000) {
//插入数据
List<Map<String, Object>> list = new LinkedList<>(this.dataMap);
Callable<Integer> callable = () -> {
int count = blacklistMasterDao.addBlackLists(list);
blacklistRecordMasterDao.addBlackListRecords(list);
return count;
};
this.willSaveAmount = 0;
this.dataMap = new LinkedList<>();
Future<Integer> future = executor.submit(callable);
resultList.add(future);
}
//汇总数据
Map<String, Object> map = new HashMap<>();
map.put("uid", rowlist.get(0));
map.put("createTime", rowlist.get(1));
map.put("regGame", rowlist.get(2));
map.put("banGame", rowlist.get(2));
this.dataMap.add(map);
this.willSaveAmount++;
this.totalSavedAmount++;
}
};
try {
xxlsAbstract.processOneSheet(file, 1);
} catch (Exception e) {
e.printStackTrace();
}
//针对没有存入的数据进行处理
if(xxlsAbstract.willSaveAmount != 0){
List<Map<String, Object>> list = new LinkedList<>(xxlsAbstract.dataMap);
Callable<Integer> callable = () -> {
int count = blacklistMasterDao.addBlackLists(list);
blacklistRecordMasterDao.addBlackListRecords(list);
return count;
};
Future<Integer> future = executor.submit(callable);
resultList.add(future);
}
executor.shutdown();
int total = 0;
for (Future<Integer> future : resultList) {
while (true) {
if (future.isDone() && !future.isCancelled()) {
int sum = future.get();
total += sum;
break;
} else {
Thread.sleep(100);
}
}
}
return total;
}
针对上面的源码,我们可以发现,我们需要将读取到的EXCEL数据插入到数据库中,这里为了减小数据库的IO和提高插入的效率,我们采用5000一批的批量插入(注意:如果数据量过大会导致组成的SQL语句无法执行)。
这里需要获取到一个最终执行成功的插入结果,并且插入执行很慢。所有采用了Java多线程的Future模式,采用异步的方式最终来获取J执行结果。
通过上面的实现,楼主测试得到最终一百万条数据需要四分钟左右的时间就可以搞定。如果大家有更好的方法,欢迎留言。
补充知识:Java API SXSSFWorkbook导出Excel大批量数据(百万级)解决导出超时
之前使用简单的HSSFWorkbook,导出的数据不能超过
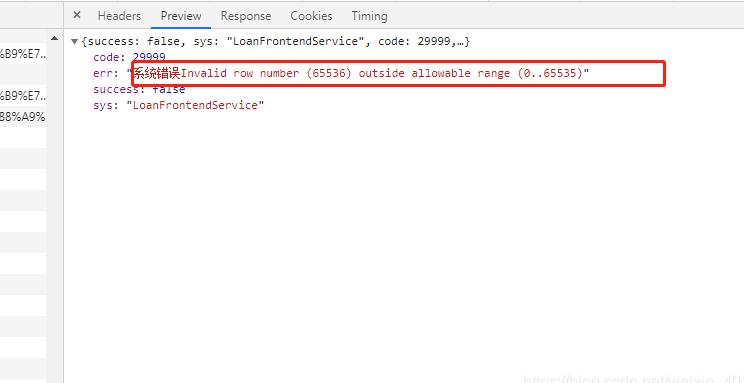
后来改成SXSSFWorkbook之后可以导出更多,但是
而且我之前的代码是一次性查出所有数据,几十万条,直接就超时了。
之前的代码是一次性查出所有的结果,list里面存了几十万条数据。因为功能设计的问题,我这一个接口要同时处理三个功能:
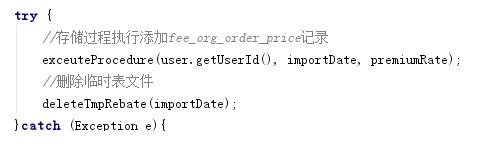
再加上查询SQL的效率问题,导致请求超时。
现在为了做到处更大量的数据只能选择优化。优化查询的sql这里就不讲了,只讲导出功能的优化。
其实就是分批次处理查询结果:
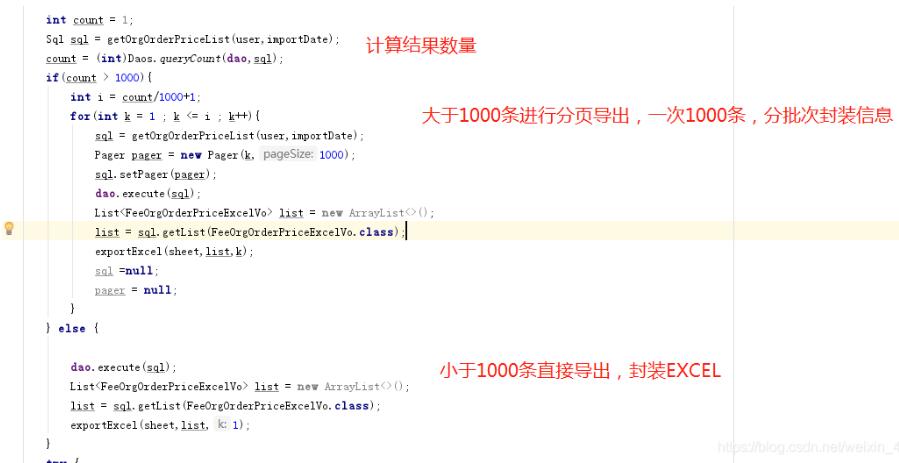
这样做的好处是查询速度变快,封装速度也变快,整体速度变快就不会出现超时,而且,每次分页查出的结果放到list中不会出现占用JVM内存过大的情况。避免出现内存溢出导致系统崩溃。
再次优化:
上面这样做虽然可以导出,但是代码看起来不美观:

这样看起来就简洁很多了。
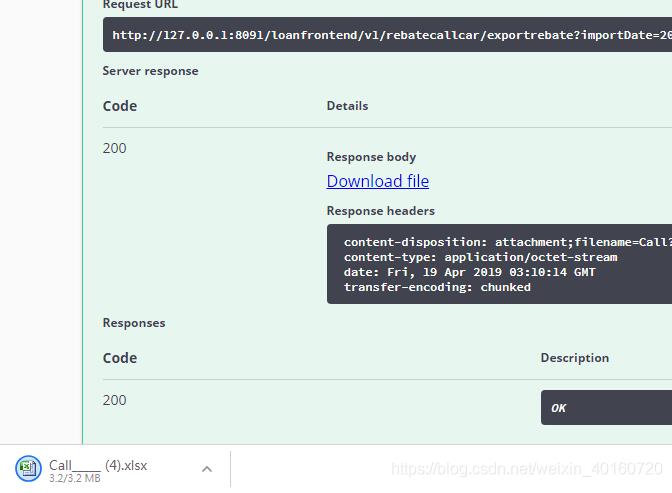
经验证,查询加封装EXCEL7000条数据处理只需要1秒

以上这篇使用Springboot+poi上传并处理百万级数据EXCEL就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持易盾网络。