简介
散列函数(英语:Hash function)又称散列算法、哈希函数,是一种从任何一种数据中创建小的数字“指纹”的方法。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。
Java语言对hashCode的应用
主要用途
- hashcode是Object中的函数,所有类都拥有的一个函数,主要返回每个对象的hash值,主要用于哈希表中,如HashMap、HashTable、HashSet。
- 在这里需要注意的是,他就是为了在一些对象数组里面存储的时候可以节省空间。(我在这里一直有个误会,就是hashCode 也会应用于对象的比较,主要比较的是对象的是否有被改变过,其实我们在进行比较的时候可以不进进行重写hashCode,单个的equals就可以保证这个对象是否相等。
- 但是很多面试官都会问到,你重写了equals 不重写hashcode 可以吗?不一定,当你重写的equals是那种两个对象所有值都相等的情况下的时候,我们就不需要重写。因为这样他就符合我们的正常逻辑,就是equals相等hashcode值一定相等。但是如果你的equals定义是只要这个对象中某个值相等就代表,这个对象相等,那么传统观念就被打破了。所以你就得按照你的equals来重写你的hashcode。保持一致。
Java 中hashcode存储的位置
存储在对象头markWord,如下图(深入理解Java虚拟机)
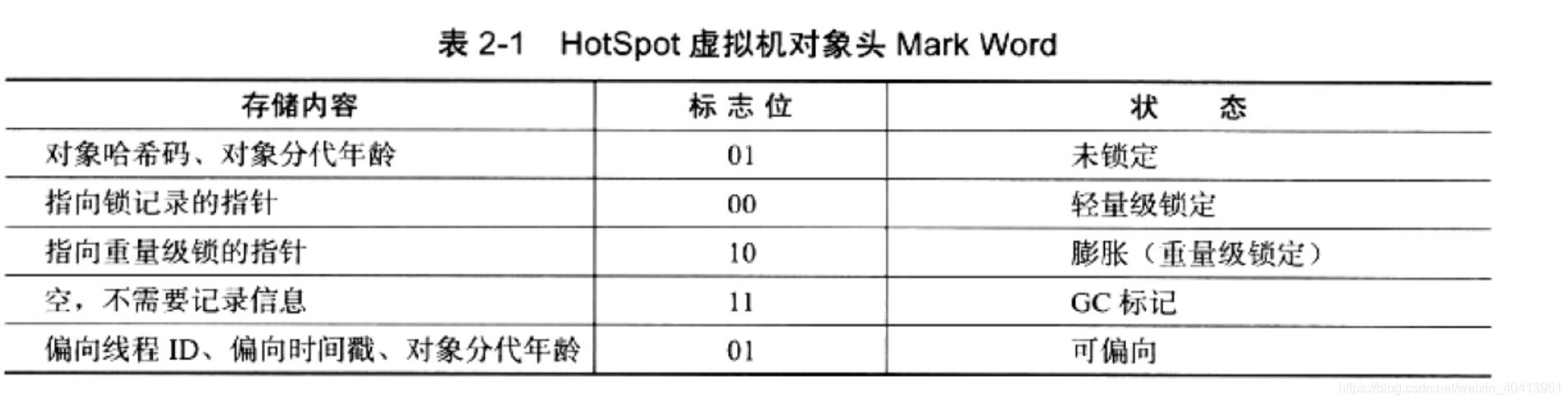
我们知道了他是存储的位置,那他是什么时候存储进去的呢? 在Java中所有的对象都是有hashcode吗?
Java中HashCode的实现:
在Java中Object.class中有hashCode方法,方法是native 方法,实现就是在JVM中实现的,也就是说他是使用C语言实现的。
实现方式:OpenJDK8 默认hashCode的计算方法是通过和当前线程有关的一个随机数+三个确定值,运用Marsaglia's xorshift scheme随机数算法得到的一个随机数。和对象内存地址无关。三个确定确定值分别是:
// thread-specific hashCode stream generator state - Marsaglia shift-xor form //随机数 _hashStateX = os::random() ; //确定值1 _hashStateY = 842502087 ; //确定值2 _hashStateZ = 0x8767 ; // (int)(3579807591LL & 0xffff) //确定值3 _hashStateW = 273326509 ;
可以通过在JVM启动参数中添加-XX:hashCode=4,改变默认的hashCode计算方式。
为什么要重写hashCode
如上文提到,我们不按传统规则重写了equals方法,所以为了不违反规则也就得重写hashCode。
源码中hashcode的重写,如hashMap中
如果m1.entrySet( ).equals(m2.entrySet()),则两个映射m1和 m2表示相同的映射 。这样可确保 equals方法可在Map接口的不同实现中正常工作。
static <K, V> boolean equals(Map<K, V> source, Object object) {
if (source == object) {
return true;
} else if (source != null && object instanceof Map) {
final Map<K, V> map = (Map<K, V>) object;
if (source.size() != map.size()) {
return false;
} else {
try {
return source.forAll(map::contains);
} catch (ClassCastException e) {
return false;
}
}
} else {
return false;
}
}
映射的哈希码定义为映射的entrySet()视图中每个条目的哈希码之和 。这确保了m1.equals(m2) 隐含了对任何两个映射 m1和m2的m1.hashCode()== m2.hashCode(),这是的总合同要求的 。Object.hashCode()
@Override
public int hashCode() {
return Collections.hashUnordered(this);
}
// hashes the elements regardless of their order
static int hashUnordered(Iterable<?> iterable) {
return hash(iterable, (acc, hash) -> acc + hash);
}
注意点 hashMap重写hashCode 和 计算hash桶位置的是不同的,这两个可不敢弄混了,我是弄混了。 下来我们再看看hash桶下表的计算。jdk 1.8中的。
/ ** *计算key.hashCode()并将(XOR)散列的较高位*扩展到较低位。
* 因为该表使用2的幂次掩码,所以*仅在当前掩码上方的位中发生变化的*哈希集将**总是发生冲突。 (众所周知的示例是Float键集*在小表中保存连续的整数。)
*因此,我们*应用了一种变换,向下扩展了较高位的影响。在速度,效用和比特扩展*质量之间需要权衡。由于许多常见的哈希集*已经合理地分布了(因此不能从*扩展*中受益),并且由于我们使用树来处理bin中的大量*冲突集,因此我们仅以*最便宜&的方式对一些移位后的位进行XOR运算,减少系统损失,以及*合并最高位的影响,否则由于表的限制,这些位将永远不会在索引计算中使用
* /
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
总结
- hashCode的简介
- Java 中 Object.hashCode()的实现
- 为什么要重写hashCode()?不打破传统规则
- HashMap中hashCode方法的重写。
- HashMap中hash桶的hash计算。
参考
https://docs.oracle.com/javase/8/docs/api/java/util/Map.html#hashCode()
https://docs.oracle.com/javase/8/docs/api/java/util/Map.html#equals(java.lang.Object)
https://juejin.cn/post/6844903487432556551
到此这篇关于细品Java8中hashCode方法的使用的文章就介绍到这了,更多相关Java8 hashCode内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!