一.布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为:O(n), O(log n), O(n/k)。
布隆过滤器的原理是,当一个元素被加入集合时,通过K个Hash函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
布隆过滤器数据结构
布隆过滤器是一个 bit 向量或者说 bit 数组,长这样:
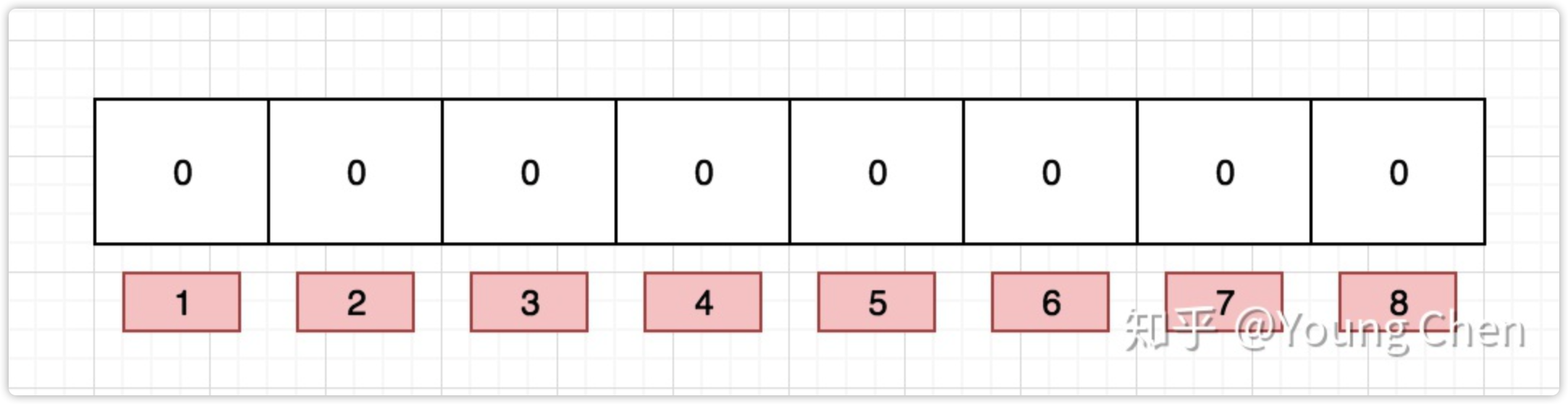
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:

值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “dianping” 这个值是否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “dianping” 这个值不存在。而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。
这是为什么呢?答案跟简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。
支持删除么
目前我们知道布隆过滤器可以支持 add 和 isExist 操作,那么 delete 操作可以么,答案是不可以,例如上图中的 bit 位 4 被两个值共同覆盖的话,一旦你删除其中一个值例如 “tencent” 而将其置位 0,那么下次判断另一个值例如 “baidu” 是否存在的话,会直接返回 false,而实际上你并没有删除它。
如何解决这个问题,答案是计数删除。但是计数删除需要存储一个数值,而不是原先的 bit 位,会增大占用的内存大小。这样的话,增加一个值就是将对应索引槽上存储的值加一,删除则是减一,判断是否存在则是看值是否大于0。
代码简单实现布隆过滤器
package com.jd.demo.test;
import java.util.Arrays;
import java.util.BitSet;
import java.util.concurrent.atomic.AtomicBoolean;
public class MyBloomFilter {
//你的布隆过滤器容量
private static final int DEFAULT_SIZE = 2 << 28;
//bit数组,用来存放结果
private static BitSet bitSet = new BitSet(DEFAULT_SIZE);
//后面hash函数会用到,用来生成不同的hash值,可随意设置,别问我为什么这么多8,图个吉利
private static final int[] ints = {1, 6, 16, 38, 58, 68};
//add方法,计算出key的hash值,并将对应下标置为true
public void add(Object key) {
Arrays.stream(ints).forEach(i -> bitSet.set(hash(key, i)));
}
//判断key是否存在,true不一定说明key存在,但是false一定说明不存在
public boolean isContain(Object key) {
boolean result = true;
for (int i : ints) {
//短路与,只要有一个bit位为false,则返回false
result = result && bitSet.get(hash(key, i));
}
return result;
}
//hash函数,借鉴了hashmap的扰动算法
private int hash(Object key, int i) {
int h;
return key == null ? 0 : (i * (DEFAULT_SIZE - 1) & ((h = key.hashCode()) ^ (h >>> 16)));
}
}
测试
public static void main(String[] args) {
MyNewBloomFilter myNewBloomFilter = new MyNewBloomFilter();
myNewBloomFilter.add("张学友");
myNewBloomFilter.add("郭德纲");
myNewBloomFilter.add(666);
System.out.println(myNewBloomFilter.isContain("张学友"));//true
System.out.println(myNewBloomFilter.isContain("张学友 "));//false
System.out.println(myNewBloomFilter.isContain("张学友1"));//false
System.out.println(myNewBloomFilter.isContain("郭德纲"));//true
System.out.println(myNewBloomFilter.isContain(666));//true
System.out.println(myNewBloomFilter.isContain(888));//false
}
二.具体代码使用
在实际应用当中,我们不需要自己去实现BloomFilter。可以使用Guava提供的相关类库即可。
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>25.1-jre</version> </dependency>12345
判断一个元素是否在集合中
public class Test1 {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
long startTime = System.nanoTime(); // 获取开始时间
//判断这一百万个数中是否包含29999这个数
if (bloomFilter.mightContain(29999)) {
System.out.println("命中了");
}
long endTime = System.nanoTime(); // 获取结束时间
System.out.println("程序运行时间: " + (endTime - startTime) + "纳秒");
}
}
运行结果如下:
命中了 程序运行时间: 441616纳秒
自定义错误率
public class Test3 {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size, 0.01);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
List<Integer> list = new ArrayList<Integer>(1000);
// 故意取10000个不在过滤器里的值,看看有多少个会被认为在过滤器里
for (int i = size + 10000; i < size + 20000; i++) {
if (bloomFilter.mightContain(i)) {
list.add(i);
}
}
System.out.println("误判的数量:" + list.size());
}
}
运行结果如下:
误判的数量:941
对于缓存宕机的场景,使用白名单或者布隆过滤器都有可能会造成一定程度的误判。原因是除了Bloom Filter 本身有误判率,宕机之前的缓存不一定能覆盖到所有DB中的数据,当宕机后用户请求了一个以前从未请求的数据,这个时候就会产生误判。当然,缓存宕机时使用白名单/布隆过滤器作为应急的方式,这种情况应该也是可以忍受的。
以上就是布隆过滤器的原理以及java 简单实现的详细内容,更多关于java 布隆过滤器的资料请关注易盾网络其它相关文章!