一直知道redis可以用来实现计数器功能,但是之前没有实际使用过,昨天碰到一个需求:用户扫码当天达到20次即提示:当日扫码次数达到上限!
当时就想到使用redis的递增方法increment()来实现计数器功能,一定要注意redisTemplate和stringRedisTemplate的使用
首先设置key:
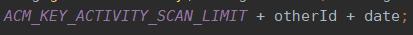
该key我使用了用户id和当天日期作为key的一部分,date:xxxx-xx-xx格式,这样一来该用户在第二天扫码的时候又是一个新key,因为日期不同了
设置key的过期时间:

实现计数器功能:
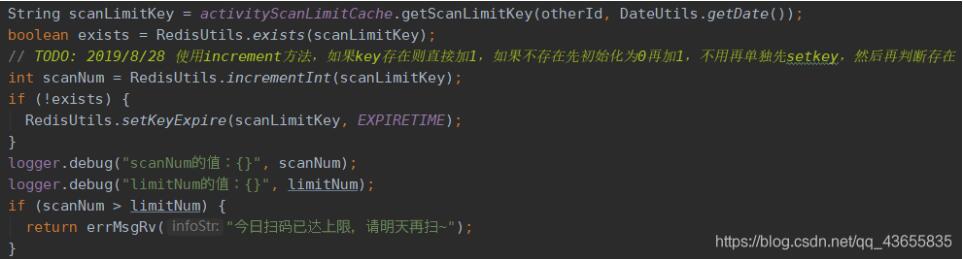


通过使用上面的方法,redis的计数器功能就可以实现了。
在使用过程过遇到的问题:
在使用的过程中,老是会抛错:ERR value is not an integer or out of range
后来发现当时我使用的方法底层用的redisTemplate和stringRedisTemplate串了,当时setKey的时候用的方法底层是
stringRedisTemplate,后面我想get(key)的时候方法底层的模板使用的是redisTemplate,后面统一了一下模板的使用,然后计数
器功能正常运行不再抛错。
看过很多文章说是序列化器的锅,increment方法必须是stringRedisTemplate模板才能使用,但是我在实际使用的时候也确实是
用了redisTemplate,这个具体原因我还在看,此次使用中最主要的问题是setKey的时候使用的模板和取key的时候使用的模板不
一致导致的。写个笔记记录一下,一个坑不踩第二遍。大家如果遇到一样的问题可以一起讨论学习一下。
补充知识:认识redis:redis计数器与数量控制
这篇文章是我个人对redis的一些理解,可以帮助大家系统的认识redis。本文的目标读者是使用过redis,但对redis了解不深的朋友。文章内容以redis为主,也会少量提到memcached。文章从redis的设计目的、工作模式、应用场景等方面阐述,最后会讲解一些具体的应用场景,还会夹带一些代码作为“干货”。
鉴于本人水平有限,文中如有不准确的内容,敬请斧正。
redis是什么
redis是一种内存型的数据存储器,使用场景
数据库
缓存
消息代理(message broker)
同memcached对比
memcached是分布式的内存对象缓存系统,设计意图为通过缓解数据库压力来加快web应用的响应速度。
上面的描述分别被放在了redis和memcached的官网首页最显眼的位置,这也回答了redis和memcached的本质区别。
redis的工作模式
redis的工作模式为单进程,这意味着redis只能利用到一个cpu内核。 redis对请求的处理是串行的,对于同时涌进来的多个请求,redis首先把请求存入队列,按请求到达的先后顺序串行处理。
了解单进程和串行这两个特点,有助于我们使用redis时“扬长避短”。
之前有同事提到过,为何redis不适合存储大块的数据?从redis的工作模式我们可以窥知一二:大块的数据意味着需要较长的io时间,包括内存io和网络的io,cpu资源在io过程中是一直被占用的,这会阻塞其它请求,从而影响redis的整体性能。
数据类型
大家对redis的数据类型已经比较熟悉了,主要有以下5种。
string
list
hash
set
sorted set
各种数据类型的常用操作
string
set,get,setnx,setex,psetex
拼接
增加、减少(整数型字符串)
位操作
list
入列,出列(这两个命令都有阻塞模式)
按排位获取部分元素
hash
设置某个索引
获取某个索引
增加/减少某个索引的值(整数型字符串)
获取所有索引的值
set
集合是一个数学概念,啰嗦提一下:集合中的元素都是唯一的
加入元素
删除元素
检查元素是否在集合
获取集合中的元素数量
取差集/并集/交集
元素转移(从集合a移至集合b)
zset
有序集合,每个元素都有一个分值,用于对元素进行排序
取交集/并集
获取一个元素的rank
获取分值在某个范围内的元素数量
获取分值在某个范围内的元素
按rank范围获取元素
redis事务
redis事务和我们熟悉的mysql事务有所区别,它们的相同在于都是对一个或一组命令的打包执行,不同的地方在于redis事务不可回滚。
redis的事务具有原子性,一个事务的执行有两种结果
完全执行
完全不执行
一些不可抗力因素除外,如服务挂掉,服务器断电。redis事务是一个独立的请求,执行过程中会阻塞其它请求。
实现redis事务有以下两种方式
multi-exec
lua脚本
multi-exec
127.0.0.1:6380[1]> set counter1 1 OK 127.0.0.1:6380[1]> set counter2 2 OK 127.0.0.1:6380[1]> set counter3 3 OK 127.0.0.1:6380[1]> 127.0.0.1:6380[1]> 127.0.0.1:6380[1]> multi OK 127.0.0.1:6380[1]> incr counter1 QUEUED 127.0.0.1:6380[1]> sadd counter2 1 QUEUED 127.0.0.1:6380[1]> incr counter3 QUEUED 127.0.0.1:6380[1]> exec 1) (integer) 2 2) (error) WRONGTYPE Operation against a key holding the wrong kind of value 3) (integer) 4
从上面的事务执行输出可以看到,我们的sadd执行出错了,原因是操作的数据类型不正确,但redis没有中止整个事务,而是继续往下执行。redis这么做是有道理的,见参考文献1。
multi-exec和watch的组合可以实现类似于mysql事务的功能,如果被watch的key在事务执行前被修改了,redis会放弃执行事务。
lua脚本
和multi-exec相比,lua脚本的优势在于灵活性,也可以减少一定的网络时间消耗(为什么?)。
鉴于redis的工作模式,不建议用lua脚本实现耗时较长的事务。
下面模拟了lua脚本的执行阻塞其它请求的场景,大家可以亲自试一下。
client 1
eval "local i=0; while(i<1000000) do redis.call('keys', '*'); i=i+1; end" 0
client 2
incr counter
redis的实际应用
锁
类型:string
命令:setnx name alice |set name alice NX
返回true则锁定成功,否则锁定失败
了解了redis的工作模式,就知道为什么用redis实现锁是如此容易了。用memcache也可以实现锁,但代码层面要复杂一些,参见memcached.cas。
事件队列
类型:zset
命令:zadd,zrangebyscore,zrem
适合存储一些需要顺序处理的事件,将事件的score值设为时间戳或自增id即可。为什么用list不可以?
计数器
类型:string
命令:incr
抽奖限额
类型:string
命令:incrby
某活动的现金红包每天最多只能发送10000元。下面是这段逻辑的伪代码,如果能够举一反三,这段代码将大有用武之地。大家可以用并发测试工具测试这段代码,如果发现了bug,或者能有更好的实现方式,请不要告诉我 -_-
$key = 'max_amount';
$amountLimit = 10000;
if (!$currAmount = Redis::get($key)) {
$currAmount = 9990; // 从持久化数据库获取当前已发放金额
// 初始化
Redis::setnx($key, $currAmount);
}
if ($currAmount >= $amountLimit) {
// 超出限额退出
}
// 抽奖金额
$rewardAmount = 10;
if ($rewardAmount > $amountLimit - $currAmount) {
$rewardAmount = $amountLimit - $currAmount;
}
if (Redis::incrby($key, $rewardAmount) > $amountLimit) {
// 超出限额退出
} else {
// 成功抽奖
}
初始化为何用setnx,用set可以吗?
最后为何使用incrby,不用可以吗?
总结
文章内容不多,所谓的干货更少,这和作者的水平有关,也和文章的定位有关。细心的朋友可能发现了,文中有一些内容是带有问号的,有兴趣的朋友可以加以思考。希望能给大家一个参考,也希望大家多多支持易盾网络