目录 1.从csv文件中读取数据 2.数据切割 数据保存在csv文件中 1.从csv文件中读取数据 参数header=None的有无 (1)没有header=None——直接将csv表中的第一行当作表头 # 读取数据import pandas as
目录
- 1.从csv文件中读取数据
- 2.数据切割
数据保存在csv文件中
1.从csv文件中读取数据
参数header=None的有无
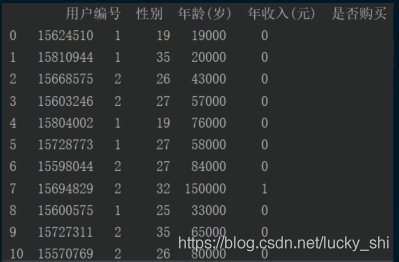
(1)没有header=None——直接将csv表中的第一行当作表头
# 读取数据
import pandas as pd
data = pd.read_csv("data1.csv")
print(data)
打印结果为:
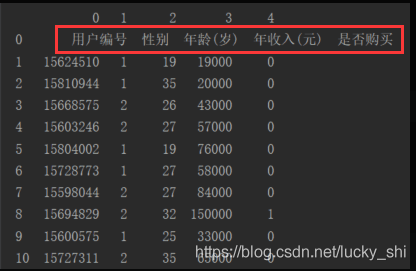
(2)有header=None——自动添加第一行当作表头
# 读取数据
import pandas as pd
data = pd.read_csv("data1.csv",header=None)
print(data)
打印结果为:
2.数据切割
(这里根据csv表的格式,将header=None不写)
(1)获取所有列,并存入一个数组中
# 读取数据
import pandas as pd
data = pd.read_csv("data1.csv")
# print(data)
# ①获取所有列,并存入一个数组中
import numpy as np
data = np.array(data)
print(data) # 用户编号 性别 年龄(岁) 年收入(元) 是否购买
# [[15624510 1 19 19000 0]
# [15810944 1 35 20000 0]
# [15668575 2 26 43000 0]
# [15603246 2 27 57000 0]
# [ ... ... ... ... ...]]
(2)获取指定列的数据,并存入一个数组中
方法一:从csv文件获取data,data[ ] ——需要考虑数据的维度问题
# 读取数据
import pandas as pd
data = pd.read_csv("data1.csv")
print(data) # 用户编号 性别 年龄(岁) 年收入(元) 是否购买
# (1)获取第1列,并存入一个数组中
import numpy as np
col_1 = data["用户编号"] #获取一列,用一维数据
data_1 = np.array(col_1)
print(data_1)
# [15624510 15810944 15668575 15603246 15804002 15728773 15598044 15694829
# 15600575 15727311 15570769 15606274 15746139 15704987 15628972 15697686
# 15733883 15617482 15704583 15621083 15649487 15736760 15714658 15599081
# 15705113 15631159 15792818 15633531 15744529]
# (2)获取第1,2列
col_12 = data[["用户编号","性别"]] #获取两列,要用二维数据
data_12 = np.array(col_12)
print(data_12)
# [[15624510 1]
# [15810944 1]
# [15668575 2]
# [15603246 2]
# [ ... ..]]
方法二:usecols=[ ] —— 直接写入获取的列数
import pandas as pd
import numpy as np
data_1 = pd.read_csv("data1.csv",usecols=["用户编号"])
data_1 = np.array(data_1)
print(data_1)
# [[15624510]
# [15810944]
# [15668575]
# [15603246]
# [ ... ]]
# (2)如获取第1,2列
data_12 = pd.read_csv("data1.csv",usecols=["用户编号","性别"])
data_12 = np.array(data_12)
print(data_12)
# [[15624510 1]
# [15810944 1]
# [15668575 2]
# [15603246 2]
# [ ... ..]]
方法三:iloc[ ] ——实质就是切片操作
import pandas as pd
import numpy as np
data = pd.read_csv("data1.csv")
# (1)获取第1列
data_1 = data.iloc[:,0]
data_1 =np.array(data_1)
print(data_1)
# [15624510 15810944 15668575 15603246 15804002 15728773 15598044 15694829
# 15600575 15727311 15570769 15606274 15746139 15704987 15628972 15697686
# 15733883 15617482 15704583 15621083 15649487 15736760 15714658 15599081
# 15705113 15631159 15792818 15633531 15744529]
# (2)获取第1,2列
data_12 = data.iloc[:,0:2]
data_12 = np.array(data_12)
print(data_12)
# [[15624510 1]
# [15810944 1]
# [15668575 2]
# [15603246 2]
# [ ... ..]]
# 获取最后两列
data_last = data.iloc[:,-2:]
data_last = np.array(data_last)
print(data_last)
# [[ 19000 0]
# [ 20000 0]
# [ 26 43000 0]
# [ 27 57000 0]
# [ ... ... ...]]
到此这篇关于Python从csv文件中读取数据并提取数据的方法的文章就介绍到这了,更多相关Python csv文件中读取数据内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!