目录 知识点 爬虫基本步骤: 爬虫代码 导入所需模块 获取网页地址 发送请求 数据解析 保存数据 运行代码,得到数据 知识点 1.爬虫基本步骤 2.requests模块 3.parsel模块 4.xpath数据解析方法
目录
- 知识点
- 爬虫基本步骤:
- 爬虫代码
- 导入所需模块
- 获取网页地址
- 发送请求
- 数据解析
- 保存数据
- 运行代码,得到数据
知识点
1.爬虫基本步骤
2.requests模块
3.parsel模块
4.xpath数据解析方法
5.分页功能
爬虫基本步骤:
1.获取网页地址 (糗事百科的段子的地址)
2.发送请求
3.数据解析
4.保存 本地
爬虫代码
导入所需模块
import re import requests import parsel
获取网页地址
url = 'https://www.qiushibaike.com/text/'
# 请求头 伪装客户端向服务器发送请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
发送请求
requ = requests.get(url=url, headers=headers).text
数据解析
sel = parsel.Selector(requ) # 解析对象 <Selector xpath=None data='<html xmlns="http://www.w3.org/1999/x...'>
href = sel.xpath('//body/div/div/div[2]/div/a[1]/@href').getall()
for html in href:
txt_href = 'https://www.qiushibaike.com' + html
requ2 = requests.get(url=txt_href, headers=headers).text
sel2 = parsel.Selector(requ2)
title = sel2.xpath('//body/div[2]/div/div[2]/h1/text()').get().strip()
title = re.sub(r'[|/\:?<>*]','_',title)
# content = sel2.xpath('//div[@class="content"]/text()').getall()
content = sel2.xpath('//body/div[2]/div/div[2]/div[2]/div[1]/div/text()').getall()
contents = '\n'.join(content)
保存数据
with open('糗事百科text\\'+title + '.txt', mode='w', encoding='utf-8') as fp:
fp.write(contents)
print(title, '下载成功')
运行代码,得到数据

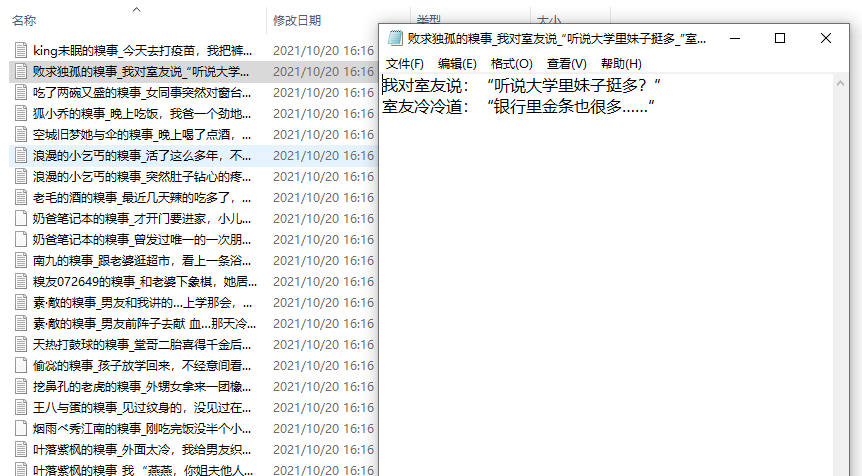
【付费VIP完整版】只要看了就能学会的教程,80集Python基础入门视频教学
点这里即可免费在线观看
到此这篇关于Python爬虫实战演练之采集糗事百科段子数据的文章就介绍到这了,更多相关Python 采集糗事百科段子内容请搜索易盾网络以前的文章或继续浏览下面的相关文章希望大家以后多多支持易盾网络!