目录
- dabl
- 1、数据预处理
- 2、探索性数据分析
- 3、建模
- 结论
数据科学模型开发涉及各种组件,包括数据收集、数据处理、探索性数据分析、建模和部署。在训练机器学习或深度学习模型之前,必须清洗数据集并使其适合训练。通常这些过程是重复的,且占用了大部时间。
为了克服这个问题,今天我分享一个名为 dabl 的开源 Python 工具包,它可以自动化机器学习模型开发,包括数据预处理、特征可视化和分析、建模。欢迎收藏学习,喜欢点赞支持。
dabl
dabl 是一个数据分析基线库,可以让机器学习建模更容易,它包括各种特性,我们只需几行 Python 代码就可以处理、分析和建模。
安装
pip install dabl
1、数据预处理
dabl 在几行 Python 代码中自动执行数据预处理管道。dabl执行的预处理步骤包括识别缺失值、删除冗余特征以及理解特征的数据类型以进一步执行特征工程。
dabl检测到的特征类型列表包括:
continuous
categorical
date
Dirty_float
Low_card_int
free_string
Useless
dabl 使用一行 Python 代码将所有数据集特征自动归类为上述数据类型。
df_clean = dabl.clean(df, verbose=1)
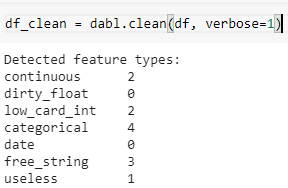
原始 Titanic 数据集有12个特征,dabl 会自动将它们分类为上述数据类型,以便进行进一步的特征工程。dabl还提供了根据需求更改任何特性的数据类型的功能。
db_clean = dabl.clean(db, type_hints={"Cabin": "categorical"})
可以使用 detect_types() 函数查看为每个特征分配的数据类型。

2、探索性数据分析
EDA 是数据科学模型开发生命周期的重要组成部分。Seaborn、Matplotlib 等是执行各种分析以更好地理解数据集的可视化库。dabl 使 EDA 变得非常简单且节省大量时间。
dabl.plot(df_clean, target_col="Survived")
dabl 中 plot()函数可以通过绘制各种图来实现可视化,包括:
- 目标分布的条形图
- 散点对图
- 线性判别分析
dabl 自动对数据集执行 PCA,并显示数据集中所有特征的判别 PCA 图。
3、建模
dabl 在训练数据上训练各种基线机器学习算法来加速建模工作流程,并返回性能最佳的模型。dabl 做出简单的假设并为基线模型生成指标。
可以使用 dabl 中 SimpleClassifier() 函数进行建模,它很快就可以返回最佳模型。

结论
Dabl 是一个方便的工具,它使机器学习更易于容易和快速,你只需几行 Python 代码就可以完成数据清理、特征可视化和基线模型的开发。
如果你想了解更多,可以查看GitHub: https://github.com/amueller/dabl
以上就是python使用dabl几行代码实现数据处理分析及ML自动化的详细内容,更多关于dabl数据处理分析及ML自动化的资料请关注易盾网络其它相关文章!