目录
- 1. 概述
- 1.1 querySelector() 和 querySelectorAll() 的用法
- 1.2 getElement(s)Byxxxx 的用法
- 2. 区别
- 2.1 getElement(s)Byxxxx 获取的是动态集合,querySelector 获取的是静态集合
- 2.2 接收的参数不同
- 2.3 浏览器兼容不同
- 2.4 querySelector 属于 W3C 中的 Selectors API 规范 ,而 getElementsBy 系列属于 W3C 的 DOM 规范
1. 概述
在看代码的时候发现基本上都是用 querySelector() 和 querySelectorAll() 来获取元素,疑惑为什么不用 getElementById()。
可能因为自己没用过那两个,所以并不清楚原因所在。
1.1 querySelector() 和 querySelectorAll() 的用法
querySelector() 方法
定义: querySelector() 方法返回文档中匹配指定 CSS 选择器的一个元素;
注意: querySelector() 方法仅返回匹配指定选择器的第一个元素。如果你需要返回所有的元素,请用 querySelectorAll() 方法替代;
语法: document.querySelector(CSS selectors);
参数值: String 必须。指定一个或多个匹配元素的 CSS 选择器。使用它们的 id, 类, 类型, 属性, 属性值等来选取元素。
对于多个选择器,使用逗号隔开,返回一个匹配的元素。
返回值: 匹配指定 CSS 选择器的第一个元素。 如果没有找到,返回 null。如果指定了非法选择器则 抛出 SYNTAX_ERR 异常。
querySelectorAll() 方法
定义: querySelectorAll() 方法返回文档中匹配指定 CSS 选择器的所有元素,返回 NodeList 对象;
NodeList 对象表示节点的集合。可以通过索引访问,索引值从 0 开始;
提示: 可使用 NodeList 对象的 length 属性来获取匹配选择器的元素属性,然后遍历所有元素,从而获取想要的信息;
语法: elementList = document.querySelectorAll(selectors);
elementList 是一个静态的 NodeList 类型的对象;
selectors 是一个由逗号连接的包含一个或多个 CSS 选择器的字符串;
参数值: String 必须。指定一个或多个匹配 CSS 选择器的元素。可以通过 id, class, 类型, 属性, 属性值等作为选择器来获取元素。
多个选择器使用逗号(,)分隔。
返回值: 一个 NodeList 对象,表示文档中匹配指定 CSS 选择器的所有元素。
NodeList 是一个静态的 NodeList 类型的对象。如果指定的选择器不合法,则抛出一个 SYNTAX_ERR 异常。
1.2 getElement(s)Byxxxx 的用法
getElementById() 方法
定义: getElementById() 方法可返回对拥有指定 ID 的第一个对象的引用。
如果没有指定 ID 的元素返回 null;
如果存在多个指定 ID 的元素则返回第一个;
如果需要查找到那些没有 ID 的元素,你可以考虑通过CSS选择器使用 querySelector();
语法: document.getElementById(elementID);
参数值: String 必须。元素ID属性值。
返回值: 元素对象 指定ID的元素
getElementsByTagName() 方法
定义: getElementsByTagName() 方法可返回带有指定标签名的对象的集合;
提示: 参数值 "*" 返回文档的所有元素;
语法: document.getElementsByTagName(tagname)
参数: String 必须 要获取元素的标签名;
返回值: NodeList 对象 指定标签名的元素集合
getElementsByClassName() 方法
定义: getElementsByClassName() 方法返回文档中所有指定类名的元素集合,作为 NodeList 对象。
NodeList 对象代表一个有顺序的节点列表。NodeList 对象 可通过节点列表中的节点索引号来访问表中的节点(索引号由0开始)。
提示: 可使用 NodeList 对象的 length 属性来确定指定类名的元素个数,并循环各个元素来获取需要的那个元素。
语法: document.getElementsByClassName(classname)
参数: String 必须 需要获取的元素类名。 多个类名使用空格分隔,如 "test demo";
返回值: NodeList 对象,表示指定类名的元素集合。元素在集合中的顺序以其在代码中的出现次序排序。
2. 区别
2.1 getElement(s)Byxxxx 获取的是动态集合,querySelector 获取的是静态集合
动态就是选出的元素会随文档改变,静态的不会 取出来之后就和文档的改变无关了。
示例1:
<body>
<ul id="box">
<li class="a">测试1</li>
<li class="a">测试2</li>
<li class="a">测试3</li>
</ul>
</body>
<script type="text/javascript">
//获取到ul,为了之后动态的添加li
var ul = document.getElementById('box');
//获取到现有ul里面的li
var list = ul.getElementsByTagName('li');
for(var i =0; i < list.length; i++){
ul.appendChild(document.createElement('li')); //动态追加li
}
</script>
上述代码会陷入死循环,i < list.length 这个循环条件。
因为在第一次获取到里面的 3 个 li 后,每当往 ul 里添加了新元素后,list便会更新其值,重新获取ul里的所有li。
也就是 getElement(s)Byxxxx 获取的是动态集合,它总会随着 dom 结构的变化而变化。
也就是每一次调用 list 都会重新对文档进行查询,导致无限循环的问题。
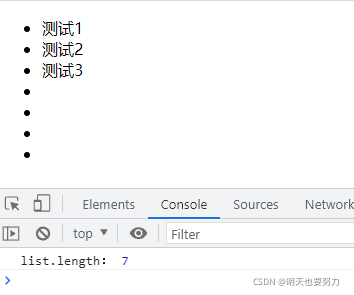
示例1 修改:
将 for 循环条件修改为 i < 4,结果 在 ul 里新添加了4个元素,所有现在插入的 li 标签数量是7。
<body>
<ul id="box">
<li class="a">测试1</li>
<li class="a">测试2</li>
<li class="a">测试3</li>
</ul>
</body>
<script type="text/javascript">
var ul = document.getElementById('box');
var list = ul.getElementsByTagName('li');
for(var i = 0; i < 4; i++){
ul.appendChild(document.createElement('li'));
}
console.log('list.length:',list.length);
</script>
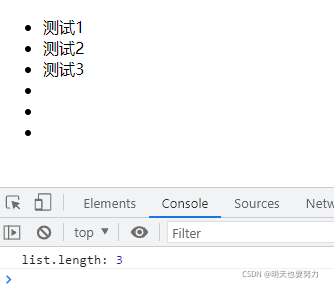
示例2:
下述代码静态集合体现在 .querySelectorAll(‘li') 获取到 ul 里所有 li 后,不管后续再动态添加了多少 li,都是不会对其参数影响。
<body>
<ul id="box">
<li class="a">测试1</li>
<li class="a">测试2</li>
<li class="a">测试3</li>
</ul>
</body>
<script type="text/javascript">
var ul = document.querySelector('ul');
var list = ul.querySelectorAll('li');
for(var i = 0; i < list.length; i++){
ul.appendChild(document.createElement('li'));
}
console.log('list.length:',list.length); //输出的结果仍然是 3,不是此时 li 的数量 6
</script>
为什么要这样设计呢?
在 W3C 规范中对 querySelectorAll 方法有明确规定:
The NodeList object returned by the querySelectorAll() method must be static ([DOM], section 8).
我们再看看在 Chrome 上面是个什么样的情况:
document.querySelectorAll('a').toString(); // return "[object NodeList]"
document.getElementsByTagName('a').toString(); // return "[object HTMLCollection]"
HTMLCollection 在 W3C 的定义如下:
An HTMLCollection is a list of nodes. An individual node may be accessed by either ordinal index or the node's name or id attributes.Note: Collections in the HTML DOM are assumed to be live meaning that they are automatically updated when the underlying document is changed.
实际上,HTMLCollection 和 NodeList 十分相似,都是一个动态的元素集合,每次访问都需要重新对文档进行查询。
区别:HTMLCollection 属于 Document Object Model HTML 规范,而 NodeList 属于 Document Object Model Core 规范。
这样说有点难理解,看看下面的例子会比较好理解:
var ul = document.getElementsByTagName('ul')[0],
lis1 = ul.childNodes,
lis2 = ul.children;
console.log(lis1.toString(), lis1.length); // "[object NodeList]" 11
console.log(lis2.toString(), lis2.length); // "[object HTMLCollection]" 4
NodeList 对象会包含文档中的所有节点,如 Element、Text 和 Comment 等;
HTMLCollection 对象只会包含文档中的 Element 节点;
另外,HTMLCollection 对象比 NodeList 对象 多提供了一个 namedItem 方法;
因此在浏览器中,querySelectorAll 的返回值是一个静态的 NodeList 对象,而 getElementsBy 系列的返回值实际上是一个 HTMLCollection 对象 。
2.2 接收的参数不同
querySelectorAll 方法接收的参数是一个 CSS 选择符;
getElementsBy 系列接收的参数只能是单一的 className、tagName 和 name;
var c1 = document.querySelectorAll('.b1 .c');
var c2 = document.getElementsByClassName('c');
var c3 = document.getElementsByClassName('b2')[0].getElementsByClassName('c');
注意:querySelectorAll 所接收的参数是必须严格符合 CSS 选择符规范的
下面这种写法,将会抛出异常(CSS 选择器中的元素名,类和 ID 均不能以数字为开头)。
try {
var e1 = document.getElementsByClassName('1a2b3c');
var e2 = document.querySelectorAll('.1a2b3c');
} catch (e) {
console.error(e.message);
}
console.log(e1 && e1[0].className);
console.log(e2 && e2[0].className);
2.3 浏览器兼容不同
querySelectorAll 已被 IE 8+、FF 3.5+、Safari 3.1+、Chrome 和 Opera 10+ 支持 ;
getElementsBy 系列,以最迟添加规范中的 getElementsByClassName 为例,IE 9+、FF 3 +、Safari 3.1+、Chrome 和 Opera 9+ 都已经支持;
2.4 querySelector 属于 W3C 中的 Selectors API 规范 ,而 getElementsBy 系列属于 W3C 的 DOM 规范
参考文章 (侵删)
到此这篇关于JavaScript中 querySelector 与 getElementById 方法的区别的文章就介绍到这了,更多相关js中 querySelector 与 getElementById 方法内容请搜索自由互联以前的文章或继续浏览下面的相关文章希望大家以后多多支持自由互联!
【文章转自:香港多IP服务器 http://www.558idc.com/hkzq.html提供,感恩】