- 两个案例都是:系统平均负载高,但cpu,内存,磁盘io都正常
-
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和CPU使用率并没有直接关系。
-
可运行状态的进程,是指正在使用CPU或者正在等待CPU的进程,也就是我们常用ps命令看到的,处于R状态(Running 或 Runnable)的进程
-
不可中断状态的进程则是正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最常见的是等待硬件设备的I/O响应,也就是我们在ps命令中看到的D状态(Uninterruptible Sleep,也称为Disk Sleep)的进程
-
我们常见的负载高一般有这几种情况引起,一个是cpu密集型,使用大量cpu会导致平均负载升高;
-
另外一个就是io密集型等待I/O会导致平均负载升高,但是CPU使用率 不一定很高;
-
还有就是大量等待CPU的进程调度也会导致平均负载升高,此时的CPU使用率也会比较高
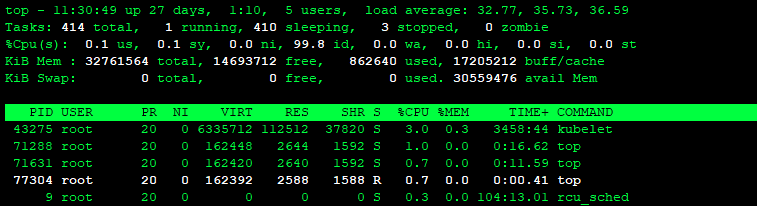
可以看到r,cs和us较高
procs:
r 表示运行和等待CPU时间片的进程数,这个值如果长期大于系统CPU个数,说明CPU不足。
b 表示等待资源的进程数,比如正在等待I/O、或者内存交换等。
memory:算是正常
swap:
si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够或者内存泄露了,要查找耗内存进程解决掉。
so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
一般情况下,si、so的值都为0,如果si、so的值长期不为0,则表示内存不足。
IO:
bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte
bo 块设备每秒发送的块数量
设置的bi+bo参考值为1000,如果超过1000,而且wa值较大,则表示系统磁盘IO有问题,应该考虑提高磁盘的读写性能。
system:
in 每秒CPU的中断次数,包括时间中断。(较高)
cs 每秒上下文切换次数(较高)
这两个值越大,内核消耗的CPU就越多
cpu:
us 用户进程消耗的CPU时间百分比,us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,就需要考虑优化程序或算法
sy 内核进程消耗的CPU时间百分比,sy值如果太高,说明内核消耗CPU资源很多,例如是IO操作频繁。
id CPU处于空闲状态的时间百分比。(cpu空闲)
wa io等待所占用的时间百分比,wa值越高,说明IO等待越严重,根据经验,wa的参考值为20%,如果wa超过20%,说明IO等待严重,引起IO等待的
原因可能是磁盘大量随机读写造成的,也可能是磁盘或者磁盘控制器的带宽瓶颈造成的(主要是块操作)
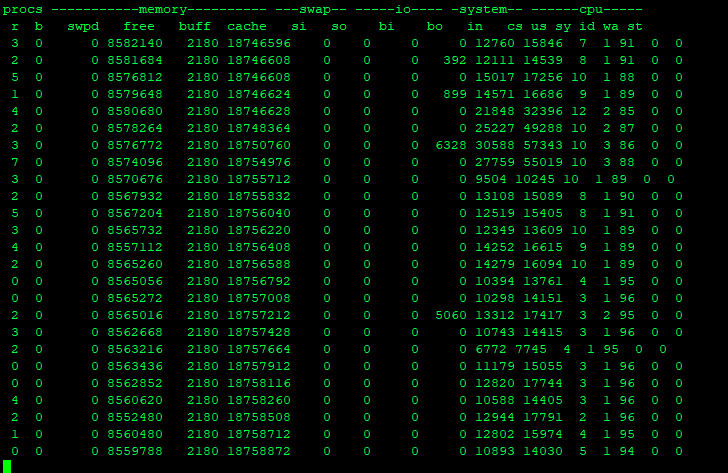
通过上面的分析,发现主要是cpu每秒中断次数以及 上下文切换较高
3、iostat查看io情况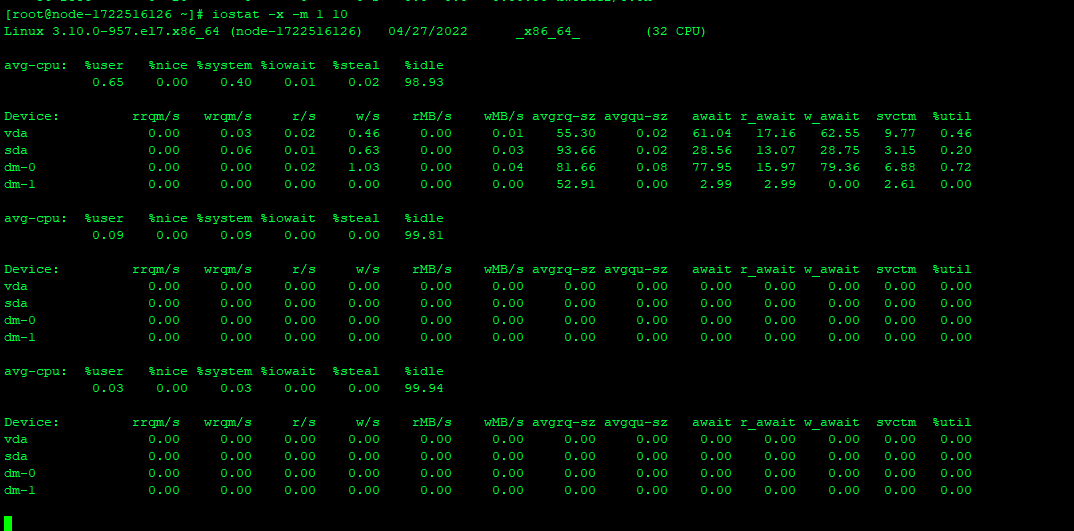
io无问题
4.1、使用pidstat分析上下文切换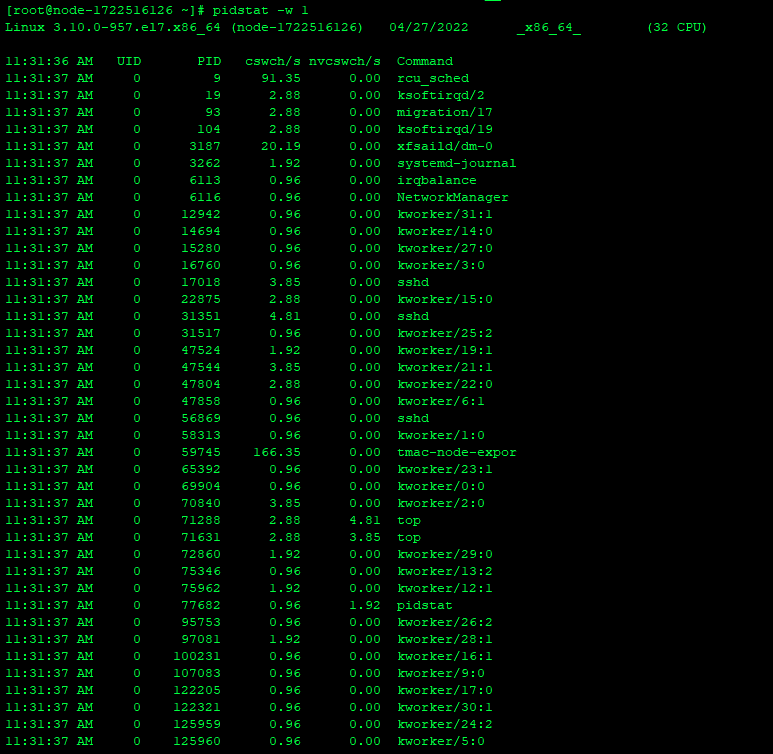
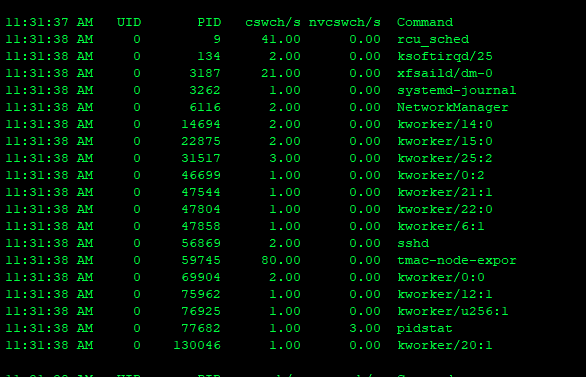
上下文切换并没有发现特别高的进程,这与vmstat的现象不太吻合,没有找到是哪个进程导致的负载高
4.2使用pidstat -wt 1pidstat -wt 1可以看到子进程的上下文切换,但并发现上下文切换较高的进程
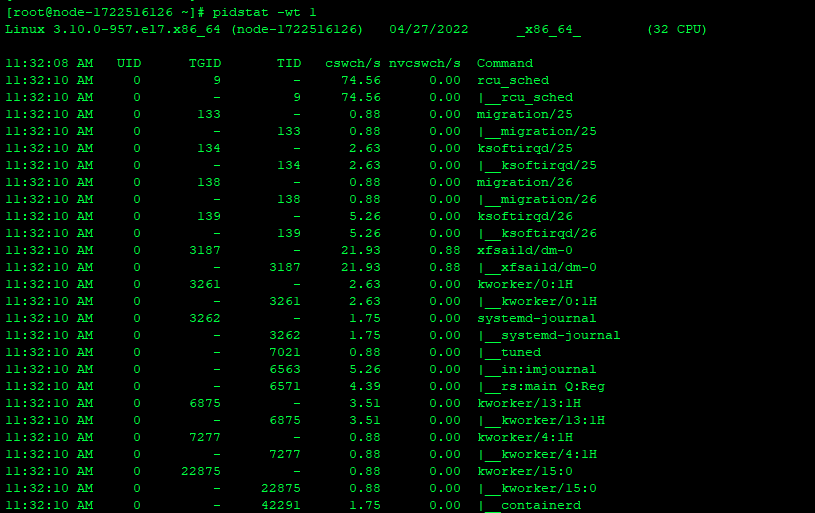
但是将所有的docker停了以后并没有效果
过程中比较奇怪的是,使用df会一直卡住,但是df -lh可以正常访问
可以看到挂载了许多k8s的tmpfs
tmpfs默认的大小是RM的一半,假如你的物理内存是32GB,那么tmpfs默认的大小就是16GB。
tmpfs 的另一个主要的好处是它闪电般的速度。因为典型的tmpfs文件系统会完全驻留在内存RAM中,读写几乎可以是瞬间的。同时它也有一个缺点tmpfs数据在重新启动之后不会保留,这点与内存的数据特性是一致的。
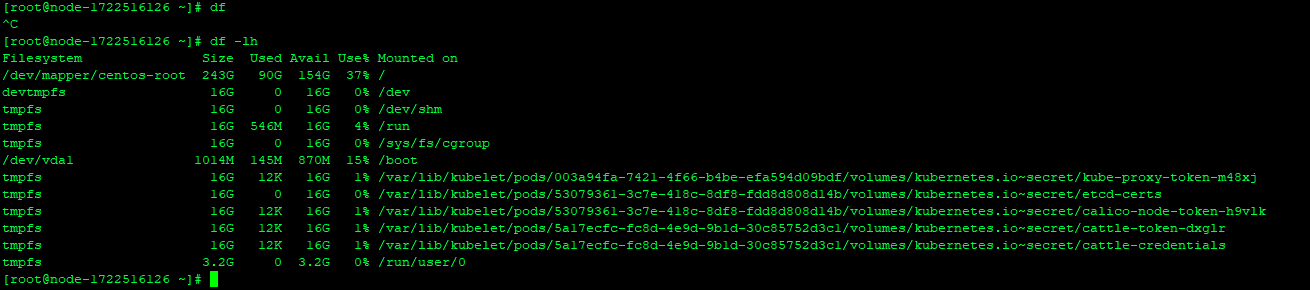
因为df打不开,怀疑是磁盘的问题
使用ps -aux,可以看到大量的D状态的进程,而且都是nfs文件系统的

仔细观察可以发现,这些D状态的进程基本都是在挂载 /var/lib/kublet/pods,就是在挂载k8s,但是一直是D状态,后面我们详细分析这个状态(TASK_UNINTERRUPTIBLE 不可中断的睡眠状态。)
3、kill掉D状态进程kill掉D状态进程后load average就降下来了。但是df还是打不开,重启服务器后,df能正常打开。

想起上周排查的一个问题,也是各项指标都很正常,但是负载高达300+,当时排查时主要去分析状态为R的进程了,由于当时没有发现有R状态的进程也就没有排查出原因,后面陈老师说kill了一个系统的exporter进程后面负载就降下来了,今天分析日志发现原来这个node_exporter的进程状态也是一直为D状态。
4、系统日志通过系统日志/var/log/messages可以看到确实有大量的nfs映射错误
什么是D状态的进程Apr 10 04:48:12 node-1722516126 nfsidmap[11838]: nss_getpwnam: name 'root@nfs-provisioner.nfs-provisioner.svc.cluster.local' does not map into domain 'localdomain' Apr 10 04:48:12 node-1722516126 nfsidmap[11852]: nss_name_to_gid: name 'root@nfs-provisioner.nfs-provisioner.svc.cluster.local' does not map into domain 'localdomain' Apr 19 16:05:24 node-1722516126 kubelet: E0419 16:05:24.039993 43275 kubelet_volumes.go:154] orphaned pod "033d41bc-502b-4142-bfb4-deac0330dd8b" found, but volume paths are still present on disk : There were a total of 5 errors similar to this. Turn up verbosity to see them. Apr 19 16:05:26 node-1722516126 kubelet: E0419 16:05:26.054950 43275 kubelet_volumes.go:154] orphaned pod "033d41bc-502b-4142-bfb4-deac0330dd8b" found, but volume paths are still present on disk : There were a total of 5 errors similar to this. Turn up verbosity to see them. Apr 19 16:05:28 node-1722516126 kubelet: E0419 16:05:28.054644 43275 kubelet_volumes.go:154] orphaned pod "033d41bc-502b-4142-bfb4-deac0330dd8b" found, but volume paths are still present on disk : There were a total of 5 errors similar to this. Turn up verbosity to see them. Apr 19 16:05:30 node-1722516126 kubelet: E0419 16:05:30.054966 43275 kubelet_volumes.go:154] orphaned pod "033d41bc-502b-4142-bfb4-deac0330dd8b" found, but volume paths are still present on disk : There were a total of 5 errors similar to this. Turn up verbosity to see them. Apr 19 16:05:32 node-1722516126 kubelet: E0419 16:05:32.040576 43275 kubelet_volumes.go:154] orphaned pod "033d41bc-502b-4142-bfb4-deac0330dd8b" found, but volume paths are still present on disk : There were a total of 5 errors similar to this. Turn up verbosity to see them.
进程为什么会被置于uninterruptible sleep(D)状态呢?处于uninterruptible sleep(D)状态的进程通常是在等待IO,比如磁盘IO,网络IO,其他外设IO,如果进程正在等待的IO在较长的时间内都没有响应,那么就很会不幸地被 ps看到了,同时也就意味着很有可能有IO出了问题,可能是外设本身出了故障,也可能是比如挂载的远程文件系统已经不可访问了,我这里遇到的问题就是由 down掉的NFS服务器引起的。
正是因为得不到IO的相应,进程才进入了uninterruptible sleep状态,所以要想使进程从uninterruptible sleep状态恢复,就得使进程等待的IO恢复,比如如果是因为从远程挂载的NFS卷不可访问导致进程进入uninterruptible sleep状态的,那么可以通过恢复该NFS卷的连接来使进程的IO请求得到满足,除此之外,要想干掉处在D状态进程就只能重启整个Linux系统了。
关于进程状态一、R TASK_RUNNING 可运行状态。如果一个进程处于该状态,那么说明它立刻就要或正在CPU上运行。不过运行的时机是不确定的,这有进程调度器来决定。
二、S TASK_INTERRUPTIBLE. 可中断的睡眠状态。当进程正在等待某个事件(比如网络连接或者信号量)到来时,会进入此状态。这样的进程会被放入对应事件的等待队列中。当事件发生时,对应的等待队列中的一个或者多个进程就会被唤醒。(大部分进程处于该状态)
三、D TASK_UNINTERRUPTIBLE 不可中断的睡眠状态。
与TASK_INTERRUPTIBLE状态类似,进程处于睡眠状态,但是此刻进程是不可中断的。不可中断,指的并不是CPU不响应外部硬件的中断,而是指进程不响应异步信号。
绝大多数情况下,进程处在睡眠状态时,总是应该能够响应异步信号的。否则你将惊奇的发现,kill -9竟然杀不死一个正在睡眠的进程了!于是我们也很好理解,为什么ps命令看到的进程几乎不会出现TASK_UNINTERRUPTIBLE状态,而总是TASK_INTERRUPTIBLE状态。
四、T TASK_STOPPED. 暂停状态或者跟踪状态。 向进程发送SIGSTOP信号,就会使该进程转入暂停状态,除非该进程正处于不可中断的睡眠状态。向正处于暂停状态的进程发送SIGCONT信号,会使该进程转向可运行状态。处于该状态的进程会暂停,并等待另一个进程(跟踪它的那个进程)对它进行操作。例如,我们使用调试工具GDB在某个程序中设置一个断点,然后对应的进程中运行到该断点处就会停下来。这时,该进程就处于跟踪状态。跟踪状态与暂停状态非常类似。但是,向处于跟踪状态的进程发送SIGCONT信号并不能使它恢复。只有当调试进程进行了相应的系统调用或者退出后才能恢复。
五、Z TASK_DEAD-EXIT_ZOMBIE 僵尸状态,处于此状态的进程即将结束运行,该进程占用的绝大多数资源也都已经被回收,不过还有一些信息未删除,比如退出码以及一些统计信息。之所以保留这些信息,可能是考虑到该进程的父进程需要这些信息。由于此时的父进程主体已经被删除而只留下一个空壳,故此状态才称为僵尸状态。
六、X TASK_DEAD-EXIT_DEAD 退出状态 在进程退出的过程中,有可能连退出码和统计信息都不需要保留。造成这种情况的原因可能是显式地让该进程的父进程忽略掉SIGCHILD信号,也可能是改进程已经被分离。分离后的子进程不会再使用和执行副进程共享的代码段中的指令,而是加载并运行一个全新的程序。在这些情况下,该进程的退出的时候就 不会转入僵尸状态,而会直接转入退出状态。处于退出状态的进程会立即被干净利落的结束掉,它占用的系统资源也会被操作系统自动回收。
在进程对某些硬件进行操作时(比如进程调用read系统调用对某个设备文件进行读操作,而read系统调用最终执行到对应设备驱动的代码,并与对应的物理设备进行交互),可能需要使用TASK_UNINTERRUPTIBLE状态对进程进行保护,以避免进程与设备交互的过程被打断,造成设备陷入不可控的状态。这种情况下的TASK_UNINTERRUPTIBLE状态总是非常短暂的,通过ps命令基本上不可能捕捉到。
进程为什么会被置于uninterruptible sleep状态呢?处于uninterruptiblesleep状态的进程通常是在等待IO,比如磁盘IO,网络IO,其他外设IO,如果进程正在等待的IO在较长的时间内都没有响应,那么就很会不幸地被ps看到了,同时也就意味着很有可能有IO出了问题,可能是外设本身出了故障,也可能是比如挂载的远程文件系统已经不可访问了(由down掉的NFS服务器引起的D状态)。
正是因为得不到IO的相应,进程才进入了uninterruptible sleep状态,所以要想使进程从uninterruptiblesleep状态恢复,就得使进程等待的IO恢复,比如如果是因为从远程挂载的NFS卷不可访问导致进程进入uninterruptiblesleep状态的,那么可以通过恢复该NFS卷的连接来使进程的IO请求得到满足。
D状态,往往是由于 I/O 资源得不到满足,而引发等待,在内核源码 fs/proc/array.c 里,其文字定义为“ "D (disk sleep)", /* 2 */ ”(由此可知 D 原是Disk的打头字母),对应着 include/linux/sched.h 里的“ #define TASK_UNINTERRUPTIBLE 2 ”。举个例子,当 NFS 服务端关闭之时,若未事先 umount 相关目录,在 NFS 客户端执行 df 就会挂住整个登录会话,按 Ctrl+C 、Ctrl+Z 都无济于事。断开连接再登录,执行 ps axf 则看到刚才的 df 进程状态位已变成了 D ,kill -9 无法杀灭。正确的处理方式,是马上恢复 NFS 服务端,再度提供服务,刚才挂起的 df 进程发现了其苦苦等待的资源,便完成任务,自动消亡。若 NFS 服务端无法恢复服务,在 reboot 之前也应将 /etc/mtab 里的相关 NFS mount 项删除,以免 reboot 过程例行调用 netfs stop 时再次发生等待资源,导致系统重启过程挂起。
参考资料:https://unix.stackexchange.com/questions/16738/when-a-process-will-go-to-d-state
https://blog.csdn.net/chinalinuxzend/article/details/4288784
https://www.cnblogs.com/embedded-linux/p/7043569.html
https://developer.aliyun.com/article/25448
https://blog.csdn.net/arkblue/article/details/46862751