对于Kafka的学习,在研究其系统模块时,有些核心组件是指的我们去了解。今天给大家来剖析一下Kafka的一些核心组件,让大家能够更好的理解Kafka的运作流程。
2.内容Kafka系统设计的非常优秀,它的核心组件由生产者、消费者、主题、代理节点、以及Zookeeper组成。这些核心组件彼此独立、却又相互存在一定的联系来支持Kafka系统正常运作。
2.1 核心组件术语 2.1.1 生产者生产者即消息数据产生的来源头,通常情况下,将原始数据(如数据库、审计日志、系统日志)写入到Kafka系统的应用程序称之为生产者实例。
生产者的主要作用是发送业务数据到Kafka系统,它在Kafka系统中承担着“搬运工”的角色,负责将分布在不同地方的原始数据,集中“搬运”到Kafka系统中进行存储。
2.1.2 消费者消费者即消息数据流出的出口,通常情况下,读取Kafka系统中业务数据的应用程序被称为消费者实例。
消费者的主要作用是读取Kafka系统中的业务数据,然后在消费者实例中经过逻辑处理后将结果写到不同的及时查询存储介质中。例如,将经过处理后的结果分别写入到分布式文件系统(HDFS)、非关系型海量存储数据库(HBase)等。消费者在Kafka系统中承担着数据分流的角色。
提示:
数据分流顾名思义就是将一份数据分别写入到不同的地方。在大数据领域中,例如Kafka系统中集中存储了业务数据,用户通过消费者实例,读取了Kafka系统中的业务数据,经过业务处理后,结果需要写到不同的及时查询存储介质中。这个过程就是一个典型的数据分流过程。
2.1.3 Topic(主题)
主题即业务数据在Kafka系统中的分类集合,通常情况下,相同类型的业务数据会存储在同一个主题下。 主题的主要作用是将不同的业务数据分类存储,便于Kafka系统统一维护和管理业务数据。对比关系型数据库,主题在Kafka系统中“扮演”的角色和关系型数据库中表的角色很类似。
2.1.4 Broker(代理节点)代理节点即Kafka系统中服务节点,通常情况下,Kafka系统中一台服务器主机被称为Kafka系统的一个代理节点。
代理节点的主要作用是负责消息数据的存储、为客户端提供服务、保证Kafka系统的正常运行等。代理节点是Kafka系统组建集群的最小单位,一个Kafka集群由一个代理节点或者多个代理节点组成。
2.1.5 ZookeeperZookeeper即Kafka集群元数据管理系统,由于Kafka系统是一个分布式消息系统,由于分布式的原因,Kafka系统需要Zookeeper来协调管理服务。
Zookeeper在Kafka系统中主要作用是选举主题分区Leader、协调各个代理节点服务、存储Kafka元数据信息等。
在新版本Kafka系统中,Kafka系统对于新的消费者实例使用了Kafka内部的消费者组协调协议,减少了对Zookeeper的依赖。这时的Zookeeper对于Kafka系统来说,更像是一个小型的分布式元数据存储系统。
2.2 核心组件元数据分布Kafka系统中,核心组件的元数据信息均存储在Zookeeper系统。这些元数据信息具体包含控制器选举次数、代理节点和主题、配置、管理员操作、控制器、以及老版本消费者实例。这些元数据信息在Zookeeper系统中的分布,如下图所示:
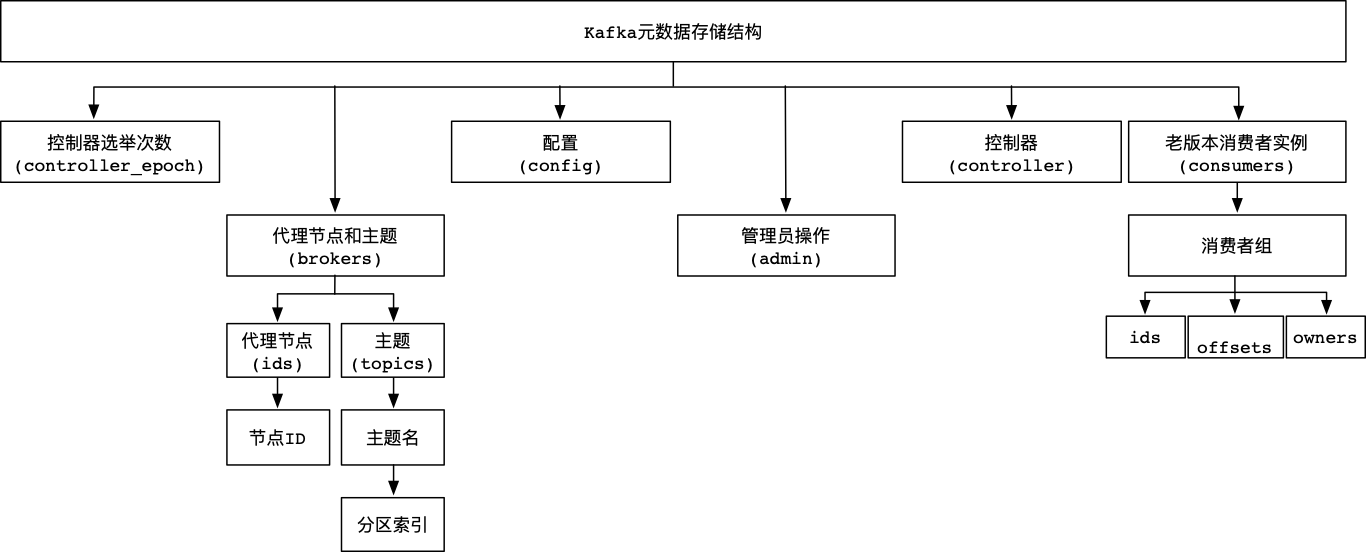
2.2.1 控制器选举次数
Kafka系统中的控制器每进行一次选举次数,都会在Zookeeper系统/controller_epoch节点下进行记录。该值为一个数字,Kafka集群中第一个代理节点(Broker)启动时该值为1。
Kafka集群中,如果遇到代理节点宕机或者变更,那么Kafka集群会重新选举新的控制器。每次控制器发生变化时,在Zookeeper系统/controller_epoch节点中的值就会加1。
2.2.2 Broker和Topic在Zookeeper系统/brokers节点中存储着Kafka代理节点和主题的元数据信息。
其中,Zookeeper系统/brokers/ids节点中存储着代理节点的ID值。Zookeeper系统/brokers/topics节点中存储着主题和分区的元数据信息。
2.2.3 配置Kafka系统中修改主题属性这类操作,会被存储到Zookeeper系统/config节点,/config节点主要包含三个子节点,分别是:
- topic:存储Kafka集群主题的额外属性,比如修改过主题的属性操作;
- client:客户端和主题配置被重写,包含消费者应用和生产者应用;
- changes:配置修改通知。
在执行管理员操作时,比如删除、分配等。在Zookeeper系统/admin节点会生成相应的子节点,内容如下:
- delete_topics:标记待删除的主题名;
- reassign_partitions:重新分配分区操作;
- preferred_replica_election:恢复Leader分区平衡操作。
Kafka系统正常运行时,在Zookeeper系统/controller节点下会存储一个Kafka代理节点的ID值,该ID值与Kafka代理节点ID相同,表示代理节点上存在控制器功能。
2.2.6 老版本消费者实例在消费者实例中,如果使用kafka.tools.ConsoleConsumer接口去读取Kafka主题数据,则会产生Zookeeper系统/consumers节点。
在Zookeeper系统/consumers节点中,存在若干个消费者组子节点,每个消费者组子节点下又会存在三个子子节点:
- 消费者线程ID(Zookeeper系统/consumers/ids);
- 消费者产生的偏移量(Zookeeper系统/consumers/offsets);
- 消费者线程和分区的对应关系(Zookeeper系统/consumers/owners)。
注意:
如果使用的是Kafka新版本消费者接口,则消费者实例产生的元数据信息不会存储在Zookeeper系统/consumers节点中,而是存储在Kafka系统的内部主题中。
3.分区存储与过期数据删除
- Broker:Kafka集群组建的最小单位,消息中间件的代理节点;
- Topic:用来区分不同的业务消息,类似于数据库中的表;
- Partition:Topic物理意义上的分组,一个Topic可以分为多个Partition,每个Partition是一个有序的队列;
- Segment:每个Partition又可以分为多个Segment文件;
- Offset:每个Partition都由一系列有序的、不可修改的消息组成,这些消息被持续追加到Partition中,Partition中的每条消息记录都有一个连续的序号,用来标识这条消息的唯一性;
- Message:Kafka系统中,文件存储的最小存储单位。
Kafka系统中的Message是以Topic为基本单位,不同的Topic之间是相互独立、互不干扰的。每个Topic又可以分为若干个Partition,每个Partition用来存储一部分的Message。
3.1 分区存储Kafka系统在创建主题时,它会规划将分区分配到各个代理节点(Broker)。例如,现有3个代理节点,准备创建一个包含6个分区、3个副本的主题,那么Kafka系统就会有18个分区副本,这18个分区副本能够被分配到3个代理节点。
在Kafka系统中,一个主题(Topic)下包含多个不同的分区(Partition),每个分区为单独的一个目录,分区的命名规则为:主题名+有序序号,第一个分区的序号从正整数0开始,序号最大值等于分区总数减1。 主题的存储路径由“log.dirs”属性决定,切换到代理节点中主题分区的存储分布,结果如图所示:
每个分区相当于一个超大的文件被均匀分配成若干个大小相等的片段(Segment),但是每个片段的消息数据量不一定是相等的,正因为这种特性的存在,方面过期的片段数据能够被快速的删除。 片段文件的生命周期由代理节点server.properties文件中配置的参数决定,这样快速删除无用的数据,可以有效的提高磁盘利用率。
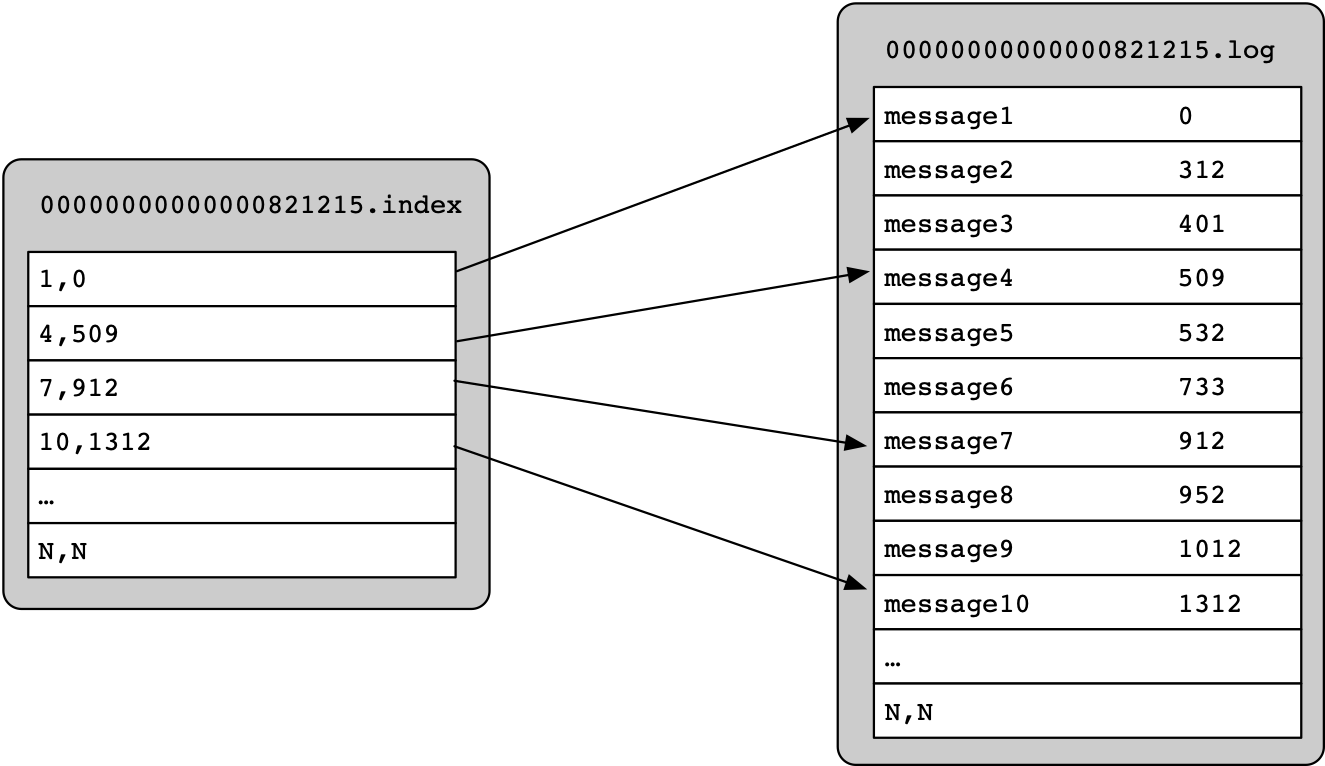
片段文件由索引文件和数据文件组成,其中后缀为“.index”表示索引文件,后缀为“.log”的表示数据文件,查看某一个分区的片段,输出结果如下图所示:

Kafka系统中的索引文件并没有给数据文件中的每条消息记录都建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据来建立一条索引。如下图所示:
提示:
通过稀疏存储索引的方式,避免了索引文件占用过多的磁盘空间。从而将索引文件存储在内存中,虽然没有建立索引的Message不能一次性定位到所在的数据文件上的位置,但是因为有稀疏索引的存在,会极大的缩小顺序扫描的范围。
3.2 消息格式
对于普通日志来说,一条记录以“\n”结尾,或者通过其他特殊的分隔符来拆分,这样就可以从文件中拆分出一条条的记录。但是这种方式对于文本来说比较适合,对Kafka系统来说,需要的是一种二进制格式。 因此,Kafka系统使用了一种经典的消息格式,在消息前面固定长度的几个字节中记录这条消息的大小(单位为byte)。在Kafka系统消息协议中,消息的具体格式见代码如下:
Message => Crc MagicByte Attributes Key Value Crc => int32 MagicByte => int8 Attributes => int8 Timestamp => int64 Key => bytes Value => bytes
这些字段含义如下所示:

4.清理过期数据
Kafka系统在清理过期的消息数据时,提供了两种清除策略。它们分别是:
- 基于时间和大小的删除策略;
- 压缩(Compact)清理策略。
这两种策略通过属性“log.cleanup.policy”来控制,可选值包含“delete”、“compact”,其默认值为“delete”。
1.删除策略按照时间来配置删除策略,配置内容:
# 系统默认保存7天 log.retention.hours=168
按照保留大小来删除过期数据,配置内容:
# 系统默认没有设置大小 log.retention.bytes=-1
另外,也可以同时配置时间和大小,来进行设置混合规则。一旦日志大小超过阀值就清除分区中老的片段数据,或者分区中某个片段的的数据超过保留时间也会被清除。
2.压缩策略如果要使用压缩策略清除过期日志,需要显示的指定属性“log.cleanup.policy”的值为“compact”。压缩清除,只能针对特定的主题应用,即写的消息数据都包含Key,合并相同Key的消息数据,只留下最新的消息数据。
5.总结Kafka核心组件整体来说比较好理解,实际在编写应用程序时,用到比较频繁的就是生产者和消费者,因此,处理学会应用之外,我们还需要更近一步的来了解Kafka的核心组件。
6.结束语这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出书了《Hadoop大数据挖掘从入门到进阶实战》,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。
联系方式:邮箱:smartloli.org@gmail.com
Twitter:https://twitter.com/smartloli
QQ群(Hadoop - 交流社区1):424769183
QQ群(Kafka并不难学): 825943084
温馨提示:请大家加群的时候写上加群理由(姓名+公司/学校),方便管理员审核,谢谢!
热爱生活,享受编程,与君共勉!
公众号:
